计算机网络论文


1. 引言
本论文从网页分类方面对万维网上的数据处理技术进行了研究。对中文网页自动分类技术这一具有重要理论意义和广阔应用前景的课题进行了研究和探索。研究内容主要包括:设计了一种中文网页自动分类技术模型,应用该模型设计的中文网页分类器能够满足处理大规模中文网页的要求。
2. 技术模型架构
为了能够有效地组织和分析海量的Web 信息资源,帮助用户迅速地获取其所需要的知识和信息,人们希望能够按照其内容实现对网页的自动分类。
每一个网页分类系统都是建立在一定的文档分类方法基础之上。准确、高效的文档属性选择和文档分类方法通常会不断出现,因此,一个文档分类系统应该具备功能和性能上的可扩展性,这就要求文档分类系统建立在模块化、可扩展的体系结构基础之上。图1所示为我们设计的中文Web网页自动分类技术的体系结构。【图1】
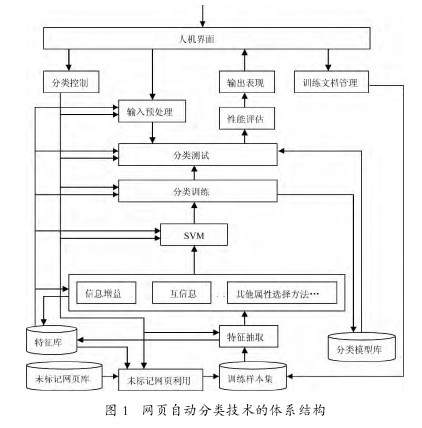
3. 数据库部件和功能模块组成
整个技术的主要功能由下列数据库部件和功能模块组成:
(1)分类模型库基于机器学习的分类通常由训练和分类两个阶段组成,在训练阶段,从训练文本学习分类知识,建立分类器;在分类阶段,根据分类器将输入文本分到最可能的类别中。根据训练样本集中的文本数据和具体的属性选择方法与分类方法,计算得到的分类模型数据,都存于该库中。将属性选择方法和分类方法的任何一种组合都作为一个分类模型。
(2)未标记网页库保存大量的未标记网页数据。当训练集中的样本数量较少时,可以通过未标记网页的利用方法从该库中选取一定的未标记网页加入到小规模的训练集中,从而弥补训练样本的不足,减少人工标记大量网页的需要。
(3)特征抽取模块负责从原始 Web 文档中提取特征信息。首先对网页进行页面分析,提取出其中的文本信息,经过分词程序分词后,去除停用词(如“的”、“和”等虚词),然后统计单词在当前网页中的词频(同时考虑单词出现在网页中的位置)。构成文本的词汇数量是相当大的,所以,表示文本的向量空间的维数也相当大,可以达到几万维。因此我们需要进行维数压缩的工作,这样做的目的主要有两个:第一,为了提高程序的效率,提高运行速度;第二,所有几万个词汇对文本分类的意义是不同的。某些稀有词在全部训练文档中出现的次数都很少,对于分类的意义不大,应予以滤除。我们设定一个出线次数阈值,如果某个特征项在训练集中的总出现次数小于该值,则滤除该特征项。
(4)文档属性选择模块负责实施分类属性的选择,提供各种用于文档属性选择的方法,它实际上是一个算法库。该模块规定统一的属性选择算法接口,以便于文档分类属性选择算法的增加与删减。一些通用的、各个类别都普遍存在的词汇对分类的贡献小;在某特定类中出现比重大而在其它类中出现比重小的词汇对文本分类的贡献大。为了提高分类精度,对于每一类,我们应去除那些表现力不强的词汇,筛选出针对该类的特征项集合,存在多种筛选特征项的算法,如前面介绍的文档频率、信息增益、χ2统计、互信息等。
(5)文档分类方法(模型)模块和前一个模块类似,这是一个分类算法库。目前实现的分类算法有基本 SVM 算法、决策 SVM 算法。根据实际的研究和使用需要,我们可以在该模块中补充新的分类算法。
(6)分类模型训练模块也就是学习模块,即根据训练文档、属性选择方法和分类算法推算分类模型。
(7)分类测试模块对预处理后的 Web 文档进行分类处理。
(8)输入预处理模块对待分类的输入Web 文档中进行预处理,从文档中提取出文本信息,滤掉对分类无用的非文本信息,通过分词提取出网页中的有效特征,并进行权值计算。
(9)性能评估模块通过对测试结果的分析,进而评估分类器的性能。
(10)输出表现模块输出分类结果和指标。
(11)训练样本集维护模块负责增加和删减训练样本集中的文档。
(12)分类控制模块对整个分类过程进行控制,包括设置分类训练和测试的参数、确定文档属性的选择方法、确定分类方法以及设置利用未标记数据的参数等。
(13)人机界面提供一个 Web 网页分类的交互环境。
(14)未标记网页利用模块该模块可以在少量的训练样本条件下,从未标记网页数据库中抽取出部分网页补充到训练集中,从而提高分类器性能,减少人工标记网页的数量。
上述体系结构的突出优点是:
a.模块化的系统结构,使得文档分类过程中的取词、选词等主要步骤相对独立,各个步产生的中间结果可以重用,从而提高效率。
b.文档属性选择和分类方法的分离,便于属性选择方法和分类方法之间的优化组合。
c.文档属性选择方法库和分类方法库的使用,有利于分档分类系统的扩展和完善。
d.未标记网页利用模块可以有效地减少人工标记大量的训练样本的需要。
4. 结束语
设计中文 Web 网页自动分类技术,该技术综合了本文在中文网页分类技术方面的研究,应用所研究的分类法提高分类器性能方面的工作,根据实际的研究和使用需要做出设计。采用模块化的结构,使得文档分类过程中的主要步骤相对独立,各个步骤产生的中间结果可以重用,从而提高了效率。文档属性选择方法库和分类方法库的使用,也有利于文档分类技术的扩展和完善。
参考文献:
[1]周水庚,关佶红,胡运发,周傲英. 一个无需辞典支持和切词处理的中文文档分类系统. 计算机研究与发展,2001,38(7);
[2]贺海军,王建芬,曹元大. 基于决策支持向量机的中文网页分类器.计算机工程,2003 年 2 期。

机械设备的生产状态和设备安装的合理性有着直接的联系,通过合理地安装机械设备能使实际生产中的设备应用和设计计划相匹配,以此来确保正常的运转和生产。...