计算机应用技术论文

数数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统和模式识别等诸多方法来实现上述目标。本文精选几篇关于数据发掘论文范文供大家学习一下。
数据挖掘论文一:
摘要:决策树算法广泛应用于数据挖掘领域之中.属性选择是决策树方法挖掘效率的关键,但ID3方法和C4.5方法在选择属性时,都会产生一定程度的选择偏差.据此,该文对信息增益模型进行了改进,将多次对数运算的信息熵求取过程简化为多值求和,从而规避了属性选择出现偏差的可能性,也加快了决策树构建的执行速度.依托学生情况数据展开的实验研究表明,与经典的ID3方法相比,该文方法构建的决策树更加简洁.同时,随着数据样本数量的增大,该文方法的执行时间大为降低.
关键词:数据挖掘;决策树;属性选择;偏差抑制
信息化技术的飞速发展,使得人们获得信息的渠道日益丰富,来自生产生活各个领域的数据信息让人们应接不暇.对海量的数据信息进行整理,并从中寻找到对自己有价值的信息至关重要,这就推动了数据发掘技术的不断进步[1].近年来,数据挖掘技术形成了重要的分支:基于决策树的挖掘方法、基于贝叶斯分类的挖掘方法、基于遗传算法的挖掘方法、基于神经网络的挖掘方法[2-4].
在这几大类方法中,基于决策树的挖掘方法应用最为广泛,这是因为决策树方法具有抑制噪声的能力,执行速度快,并且适合于各种规模的数据集合[5].决策树算法根据不同的属性对数据对象进行分类或测试,其中ID3型决策树算法是比较有代表性的挖掘算法之一[6].ID3型决策树采用了一种分治策略,依托信息熵理论并通过迭代分类器实现数据自动分类[7].
郭亦东等[8]在口令分析中使用了数据挖掘技术,并构建了一种基于剪枝决策树的挖掘方法,此方法中设计了节点代价的目标函数,并详细地设计了节点扩展、剪枝规则,从而进一步提升了ID3型决策树挖掘方法的效率.Kumar等[9]采取二分挖掘策略代替传统的线性挖掘策略,并对决策判断的局部阈值进行了分级改进,从而大大提高了决策树的构建效率.Ramos等[10]将模糊决策理论引入数据挖掘领域中的决策树构建,并证实模糊决策可以进一步提升决策树的归纳和推理能力.
基于决策树的数据挖掘方法依赖于准确的属性设置和表达,为了进一步提升决策树挖掘方法的准确率,本文对决策树挖掘过程中的属性选择偏差抑制问题进行探讨,以期得到具有更优秀性能的挖掘方法.
1、基于属性选择偏差抑制的决策树挖掘算法
在一个挖掘算法中,决策树的性能是否理想取决于属性选择得是否理想.选择了合适的属性,决策树就可以精炼,其预测能力也会大大提升.选择合适的属性、设置最精简的决策树是一个典型的NP问题(Non-Deterministic Polynomial,非确定多项式问题),已有的算法大都采取启发式策略加以解决.这种做法的最大问题在于启发式策略选择的属性,在数据分类过程中区分能力不能达到最准确,并且启发式策略执行依靠的计算复杂程度过高.
这里,数据分类的信息量一共有n个,分别用d1,d2,…,dn来表示.可见,公式(1)的计算过程涉及了多次对数运算,当参与挖掘的数据量过大时,这种算法的计算成本和时间代价非常高.作为决策树挖掘算法中的两类代表性方法,ID3挖掘算法依靠信息熵来选择属性,选择结果往往更倾向于取值较多的属性;C4.5挖掘算法则根据信息熵的增益来选择属性,选择结果往往更倾向于取值不均匀的属性.本文构建决策树挖掘算法的思路是在信息熵理论的基础上进行改进,并对属性选择时的偏差进行有效的抑制,同时兼顾属性选择的准确性和算法的执行速度.本文算法的首要工作是在信息熵和信息增益的基础上建立新的属性选择标准,抑制决策树算法在属性选择过程中出现的偏差,提高属性选择的合理性、准确性.
同时,本文算法试图构建最精炼的决策树,提高决策树的构建速度、提升决策树分类的准确率和效率.
2、实验结果与分析
为了验证本文在数据挖掘算法中提出的决策树构建方法的有效性,本文接下来的工作将针对具体的数据展开实验研究.实验中所用的计算机硬件配置为amd双核、主频2.0GHz的CPU,内存大小为8GB,硬盘大小为500GB.实验中所用的计算机软件配置为windows 7.0操作系统,matlab程序设计语言及编译环境.实验目的确立为验证本文方法构建决策树的精炼性和执行速度.实验的数据对象为某高校的学生情况,数据属性选择了奖学金情况、课程成绩、性别.
实验中,总样本数量为2 000个,从15,30,60,120,240,480,960,1920这样的顺序逐步扩大样本量,以测试本文提出的方法的性能.如表1所示,包含了30个样本的学生情况数据.
表1 参与数据挖掘决策树构建的学生情况数据样本
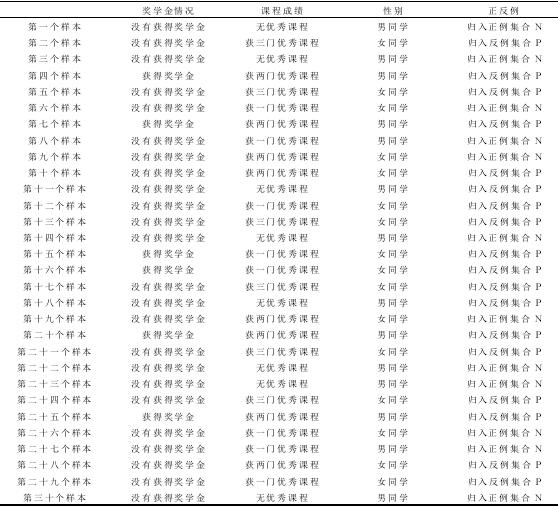
为了形成和本文方法执行效果的直观对照,笔者还选择了经典的ID3方法作为本文方法的比较算法.根据ID3方法以及表1中的样本数据,构建的决策树如图1所示.
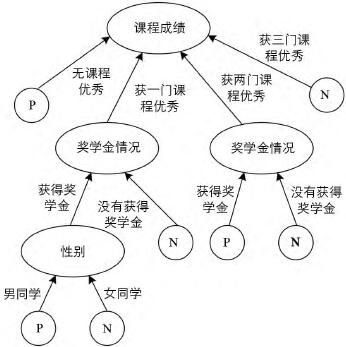
图1 经典的ID3方法获得的决策树
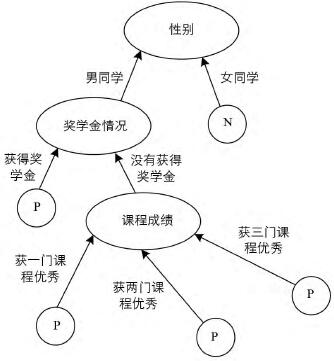
图2 本文方法获得的决策树
对比图2和图1的决策树构建结果,可以明显看出本文方法有效地避免了属性选择的多值倾向,从而有效地精简了决策树的结构,优于ID3方法.下面,笔者再从执行时间上比较本文方法和ID3方法的差异.实验对象的样本数量从15个样本开始,逐步翻倍到30,60,120,240,480,960,1920.2种方法构建决策树的时间对比,如图3所示.
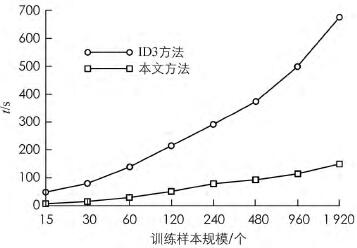
图3 2种方法的执行时间对比
从图3中可知,本文构建的方法因为避免了多次对数运算,而代之以求和运算,执行速度明显提升,大大优于ID3算法.尤其是随着数据集合规模不断扩大,这种优势更加明显,这充分说明了本文方法在速度上的优势。
3、结论
针对数据挖掘问题,本文对基于决策树的挖掘方法展开了研究.经典的ID3方法和C4.5方法在决策树构建的过程中存在属性选择多值倾向和不均匀倾向,具有一定的选择偏差.为此,在信息增益模型的基础上,笔者对信息熵的计算过程进行了进一步的改进处理,用多值求和替代了多次对数运算.这种计算原理上的改变,抑制了属性选择的偏差倾向,也提升了决策树的构建速度.实验结果表明,本文方法与经典的ID3方法相比,构建的决策树更加精炼,执行速度的优势也非常明显。

2016年流行一个术语叫做数据主义,数据主义认为整个世界由数据流构成,数据每天以指数级增长,电话、飞机、网购、出行都是一个新的数据。数据将会有越来越重要的作用,同时人的地位慢慢开始下降。未来人的价值取决于对数据流的分析解读能力,因此分析技术在...
前言:近几年,我国教育规模在不断扩大,学生对于学校也提出了更高的要求,希望学校制度能够更加灵活,并且适合学生。学校需要为学生提供机房,满足学生对于学习进度、指示导向等等学习内容的要求,提高学校为学生服务质量。但是学生的这些需求对于学校机房...
0引言科研档案是高等学校科研发展的缩影和真实写照,是反映高校科学研究和科研管理水平的重要标志,是高校实力的见证。科学研究水平是各高校核心竞争力的关键所在,支撑和引领学科建设与发展。随着高校科技创新竞争的日趋激烈,在科技资源配置方面,高端人...

目前,不论是银行还是其他金融机构,每天都要处理信贷、投资、储存等海量金融数据,而面对这些海量数据时,先进的数据挖掘技术则必不可少。...
文章首先介绍了数挖掘技术,同时将该技术与软件工程相联系,指出了将数据挖掘技术应用到软件知识库中的重要性,并从软件知识库的开发与应用两方面入手,对其具体应用手段与过程进行了分析。引言计算机以及信息技术的不断发展,使得数据挖掘技术逐渐出现,...

气象预报学是现代基础科学中难度最高、挑战性最强的一门综合性学科,作为一种预测性质的学科,气象预报极易受到天气系统变化、天气因素干扰、天气状况作用等要素的影响,会让天气现象在一定程度上不按照常规演变生成,使气象预报的不确定性进一步加大。...
1移动电子商务1.1电子商务目前,对电子商务(ElectronicCommerce、E-Commerce)的定义是通过互联网的这种网络手段进行以商品交换为中心的一种商务活动[1].电子商务目前广泛存在于全球商业活动中,又分为电子商务分为:ABC(Agent、Business、Consumer:...