录音艺术论文

摘 要: 对白是影视声音的重要组成部分.同期录音和后期配音过程中, 设备、环境和人为因素等均会造成各种形式的音质缺陷.传统的后期处理是通过人工查找缺陷进行修复, 效率较低.分析影视对白中的各类音质缺陷及其产生原因, 对比分析可行的检测方法, 以期为对白缺陷自动化检测提供思路.
关键词: 对白; 音质缺陷; 检测; 声音事件;

Abstract: Dialogue is an important part of film and television sound, but whether it is dialogue recorded in the same period or in the period of ADR (voice dubbing) , sound quality defects of various kinds are inevitable because of equipment, environment, and human factors. Traditional post-processing, which is carried out by manually searching for defects, is inefficient. This paper explores various types of sound defects in film and television dialogue, and then it compares feasible detection methods to provide ideas for automatic detection of dialogue defects.
Keyword: dialogue; sound quality defects; detection; sound event;
自有声电影诞生以来, 声音和画面一样, 成为了电影不可或缺的部分.电影中的声音可分成三类:语言, 音乐和音响.对白是电影语言的重要组成部分, 其质量的好坏对影视作品而言举足轻重.影视对白的后期处理传统上是通过人工查找缺陷的方式进行修复, 但这种方式的效率较低, 耗费声音剪辑师大量的时间和精力.
在日常生活中, 自然界会发生各种各样的声音, 如狗叫声, 脚步声, 玻璃粉碎声和雷声.在计算机听觉中, 识别一段音频内所发生事件的种类被称为声音事件识别 (sound event detection, SED) .SED可自动识别这些声音事件, 其目标是检测录音中每个声音事件的开始时间和偏移时间, 并将文本描述符 (每个事件的标签) 关联起来.近年来, SED受到了越来越多的关注, 其中包括音频监视[1], 医疗保健监测[2], 城市声音分析[3], 多媒体事件检测[4]和鸟叫检测[5]等
随着人工智能和深度学习模型的不断提出, 声音事件识别技术有了新的进展.基于混合高斯模型的隐马尔可夫模型 (Gaussian mixture model-hidden Markov model, GMM-HMM) 已被广泛应用于自动语音识别领域, 在SED中则被更多地应用于单音的声音事件识别[6].随着深度学习技术和公开可用的实时数据库的出现, 复音SED开始被更多地运用到实际案例中.基于非负矩阵分解 (non-negative matrix factorization, NMF) 的信源分离[7]和基于深度学习方法的前馈神经网络 (feed-forward neural network, FNN) [8]、卷积神经网络 (convolutional neural network, CNN) [9]和递归神经网络 (recurrent neural network, RNN) 与其他方法 (例如用于复音SED的GMM-HMM) 相比, 表现明显更好.
1、 对白素材的缺陷及其产生原因
根据对白录制地点的不同, 对白素材可以分成两类:同期声和后期配音.同期声是指在影视剧拍摄时同时记录角色的对白, 而不是通过录音棚的后期配音来完成.同期声记录的是现场的实时声音和演员的声音表演, 它比后期配音更为真实自然.但是拍摄现场录制同期声往往会遇到各种状况, 比如环境噪声、设备故障或者演员发音问题等.后期配音, 也称“自动对白替换 (automatic dialog replacement, ADR) ”, 是一种在声学条件良好并可控的环境下录制对白的方法.该方法通过为配音演员重复播放影片中某一片段, 同步录制新的对白.虽然现今电影声音的录制技术已经较为成熟, 整个流程也很完善, 但后期配音录制的部分素材仍可能存在缺陷.
1.1、 同期声
同期声是在演员表演时现场同步进行录制, 一般采用枪式吊杆话筒和无线隐藏式领夹话筒完成声音的拾取.吊杆话筒使用一种可伸缩的特制杆固定话筒, 接近声源而又不使话筒出现在镜头中.吊杆话筒包括话筒、吊杆、话筒支架、防风罩及防风毛皮.为了能够在远距离时清晰地拾取演员的声音, 一般采用高灵敏度的强指向性话筒.由于现场环境杂乱和话筒的高灵敏度, 现场的背景声音会被拾取, 从而造成素材底噪过大的问题.背景噪声主要有: (1) 环境中产生的随机噪声; (2) 无线干扰 (大功率照明灯产生高频噪声影响无线设备) ; (3) 吊杆移动产生的风声; (4) 吊杆员手摩擦吊杆的声音; (5) 领夹话筒拾取到的不清晰的声音.
另外, 录音师的操作不当会也导致素材产生缺陷.拾音时, 声音经过话筒、调音台再传输到监听耳机.当声音经过调音台传输到监听耳机时, 录音师会对声音进行增益预处理.如果增益太高, 会导致声音失真, 增益太低则会导致声音音量过小.
1.2、 后期配音
后期配音是在专业的录音棚中进行的, 因此对比同期声素材, 后期配音中环境噪声部分的缺陷减少.后期配音素材的音质缺陷更多的是人为操作不当造成的, 例如, 演员在念对白时会在读某些字时不自觉地发出齿音或者喷音.齿音和喷音在后期素材处理时的操作难度较大, 并且齿音和喷音人耳不易分辨.另外, 演员配音时吞咽口水的声音也会被麦克风拾取.
在录音棚内录制对白, 一般使用大振膜复合式话筒.由于声源在某点所产生的声压与该点到声源的距离成反比, 因而话筒距声源越近, 声压变化越大.对复合式 (心形拾音器) 方式而言, 当传声器近距离拾音时, 振膜处在球面声场中, 到达振膜两表面声波除了声压差还有振幅差.对于低频信号, 声波的相位差很小, 振幅差起主要作用, 因而受距离影响较大, 表现为近距离拾音时低频提升, 且随着距离的减小愈加明显.这种由于近距离拾音而造成的压差式或复合式传声器低频提升的现象称为近讲效应.近讲效应引起的低频提升会使声音清晰度降低, 尤其是在语言录音中.因此, 演员录音时应与麦克风保持适当的距离.另外, 由于话筒的单指向性的特点, 演员稍不注意就会偏离话筒的指向, 造成素材声音音量太小的结果.
2、 音质缺陷检测
2.1、 传统的检测方法
目前, 传统的音质缺陷检测一般是通过专业的录音师进行主观的评定.根据国家技术监督局1996年发布的标准GB/T 16463—1996《广播节目声音质量主观评价方法和技术指标要求》[10], 受过专业训练的评定员采用绝对法评定一个节目音质质量.常用的广播节目声音质量主观评价记分表中的评价参量包括清晰度、丰满度、圆润度、明亮度、重复度、真实度、平衡度, 评价述语参量分为优、良、中、差、劣共5个级别.由于对白素材中的缺陷依赖声音剪辑师的主观分辨, 因此该方法耗时费力, 且标准不统一.
2.2、 机器听觉
随着计算机技术的发展, 音质缺陷检测可以通过机器听觉来完成.音质缺陷检测属于SED的范畴.随着机器学习和深度学习的快速发展, 机器听觉的准确率有了较大提高.以声音为输入的机器学习任务, 可以被纳入机器听觉的范畴, 其中为大众所熟知的功能是语音识别.能够被“听”到的声音并不只有语音, 广义的声音还包括动物、机械和自然环境等发出的各种声音.
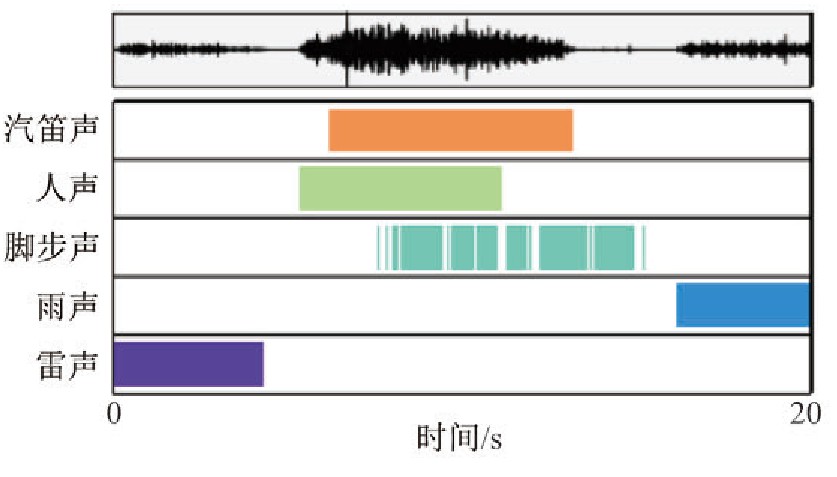
SED分为单音SED和复音SED, 其中在给定的时间点内最多只能检测到发生的一个声音事件称为单音SED.同一个时间点内无论存在多少个声音事件, 单音SED系统都只能检测到一个声音事件.无法检测同一时间点内发生的所有事件是单音SED实际适用性方面的缺陷.多个声音事件很可能在时间上重叠.例如, 繁忙街道的录音可能包含脚步、语音和汽车喇叭声, 这些声音会在同一个时间点上混合在一起.图1为重叠声音事件的识别[11].由图1可以看出, 其中多达3个不同的声音事件混合出现.
图1 重叠声音事件的识别Fig.1 Identification of sound overlaps
2.2.1、 单音SED
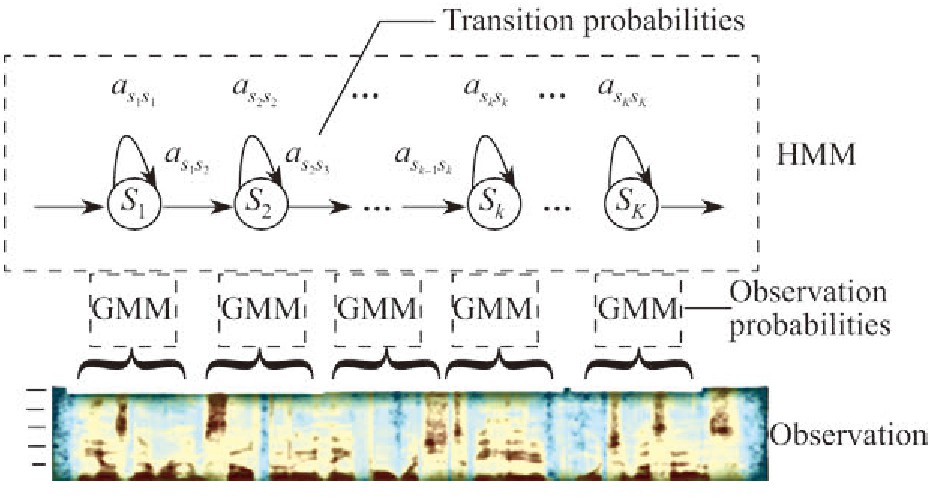
典型的SED方法基于GMM-HMM, 模型如图2所示.GMM-HMM将获取特征用混合高斯模型模拟, 再把均值和方差输入到HMM模型中.GMM-HMM是一个统计模型, 它描述了两个相互依赖的过程, 一个是可观察的过程, 另一个是隐藏的马尔可夫过程.GMM-HMM模型应用于SED时, 其发射概率分布由高斯混合模型 (Gaussian mixture model, GMM) 表示, 以梅尔频率倒谱系数 (Mel-frequency cepstral coefficient, MFCC) 为特征[12].在GMM-HMM方法中, 每个声音事件以及事件之间的静音由HMM建模, 最大似然路径使用维特比算法确定.但这种方法的性能有限, 准确率较低, 需要启发式方法才能执行复音SED.因此, GMM-HMM模型常用于单个声音事件的识别.对于现实生活情景来说, 更适合的方法是复音SED, 该方法可以在任何给定时刻检测多个重叠的声音事件.
图2 隐马尔科夫模型Fig.2 Hidden Markov models
2.2.2、 复音SED
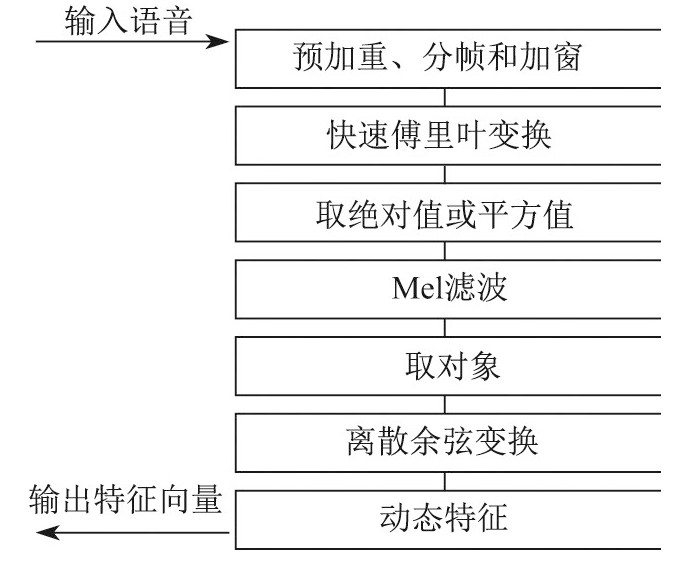
特征、模型和标签分类器就可以构成一个复音声音事件识别的系统.对于音频分类标签任务, 通常采用梅尔频率倒谱系数和梅尔滤波器组 (Mel filter bank, MFB) 作为基本特征.梅尔频率倒谱系数的提取过程如图3所示, 具体步骤如下: (1) 对语音进行预加重、分帧和加窗; (2) 对每一个短时分析窗, 通过快速傅里叶变换 (fast Fourier transform, FFT) 得到对应的频谱; (3) 将频谱通过Mel滤波器组得到Mel频谱; (4) 在Mel频谱上面进行倒谱分析 (取对数, 作逆变换, 实际逆变换一般是通过DCT离散余弦变换来实现, 取离散余弦变换 (discrete cosine transform, DCT) 后的第2?13个系数作为MFCC系数) , 获得Mel频率倒谱系数MFCC.
图3 MFCC特征的提取过程Fig.3 MFCC feature extraction process
特征提取完毕后输入到声学模型中进行训练.通常需要大量的数据训练声学模型, 最后识别的准确率才能达到理想的效果.常规使用的声学模型有CNN, RNN, 深层神经网络 (deep neural network, DNN) , 长短期记忆网络 (long short-term memory, LSTM) 等, 其中每个模型都有自己的优点和缺点.
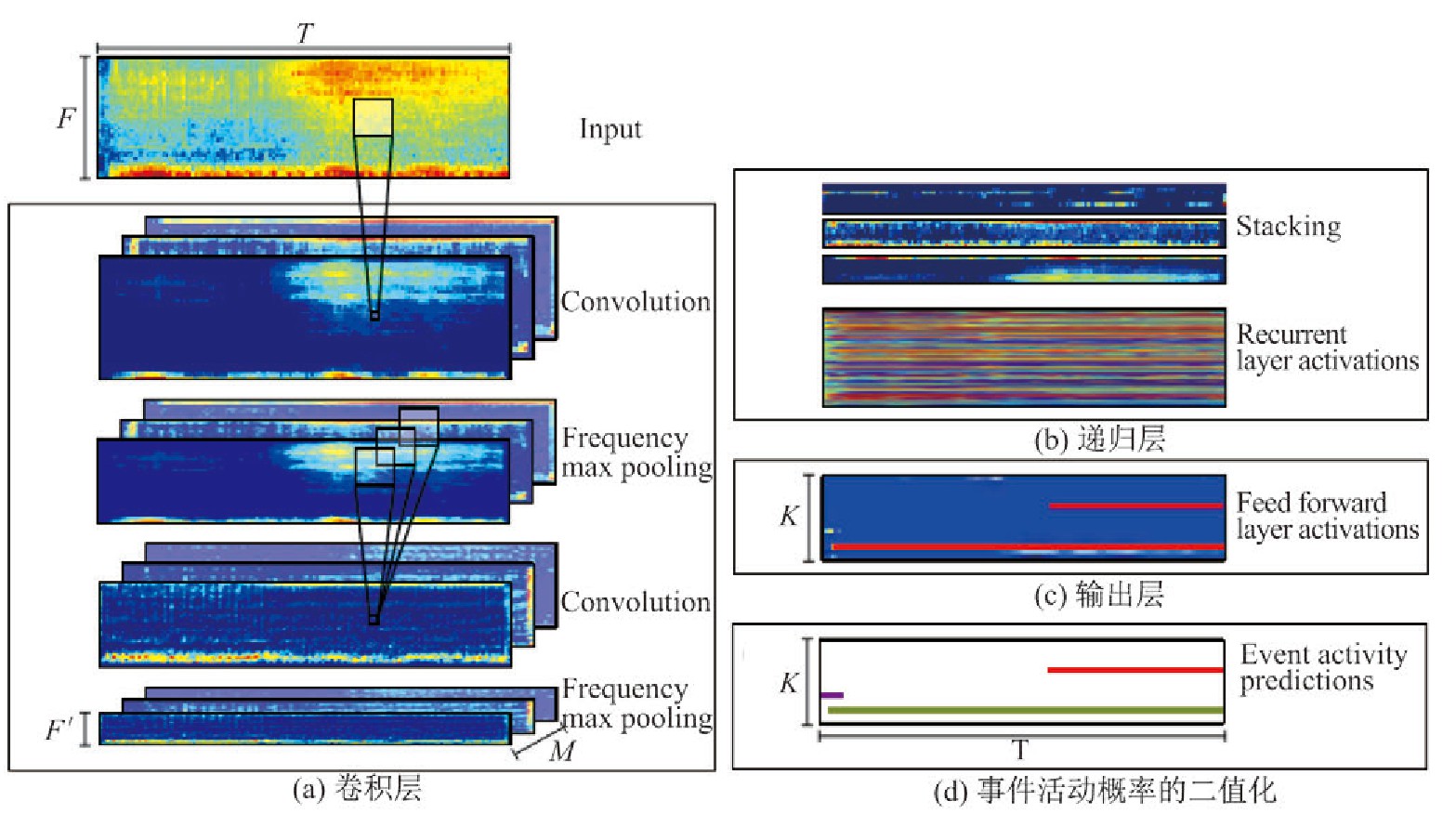
在复音事件识别任务中, CNN可以通过学习滤波器来解决特征提取后的时间和频率的不变性.滤波器实现时间和频率两方面均有偏移, 但会导致缺少长时间的背景信息的问题.RNN通过整合来自早期时间窗的信息解决了缺乏长时间的背景信息的问题, 从而呈现理论上无限的情境信息, 但是RNN不容易捕获频域中的不变性, 从而使数据的高级建模变得困难.Cak??r等[13]整合了CNN和RNN的优点, 将这两种体系结构组合成单一的网络 (在卷积层之后是递归层) , 被称为卷积递归神经网络 (convolutional recurrent neural network, CRNN) .图4所示为CRNN的网络结构.在这种结构中, 卷积层充当特征提取器, 递归层随时间集成提取的特征, 从而提供上下文信息, 最后前馈层产生每个类的活动概率.卷积、递归和前馈层的堆栈通过反向传播联合训练.
图4 CRNN的网络结构Fig.4 Network structure of CRNN
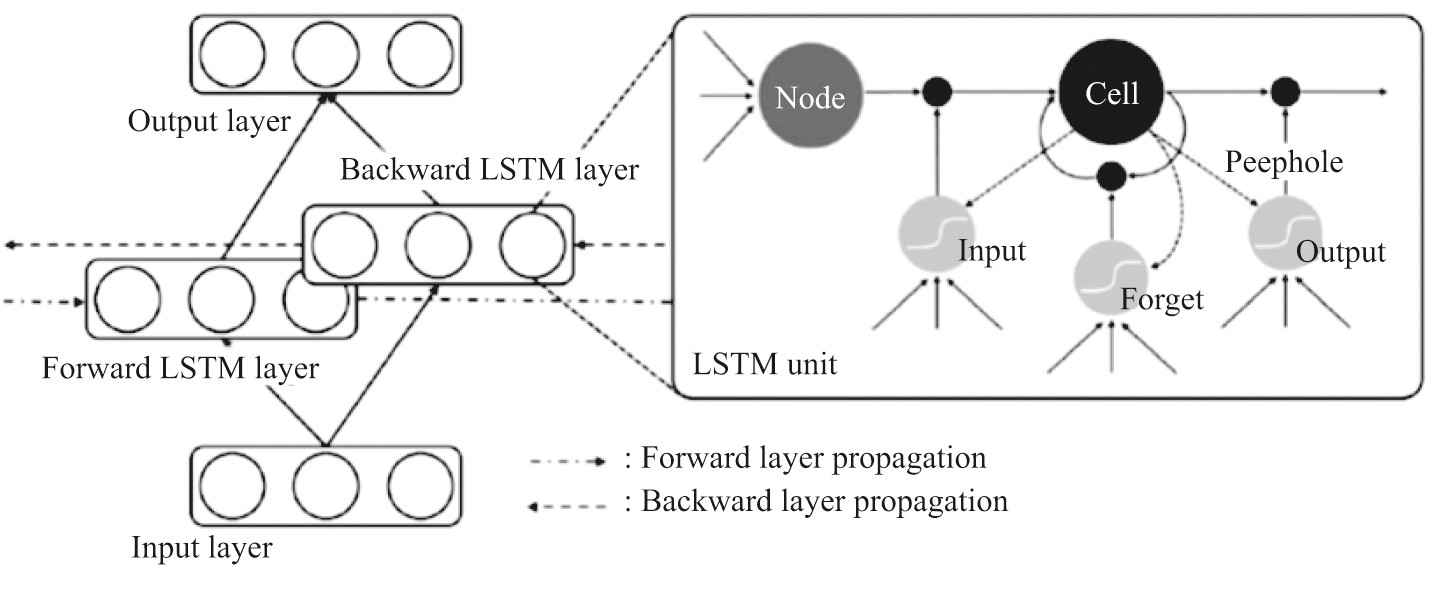
在实际应用中, 基本的RNN被证实在处理不同类别的输入序列时, 无法充分有效地利用历史信息.在一些早期的研究中, 一种被称为“长短时记忆单元”的记忆结构被引入到RNN中, 这种RNN的变种成功地解决了传统RNN所不能克服的基本问题.当重要事件的间隔很长时, LSTM-RNN更适合于从输入序列中学习并分类、处理和预测时间序列.Hayashi等[11]提出了一种称为持续时间控制的长短时记忆的混合方法, 用于复音声音事件检测.该方法使用双向长短时记忆单元回归神经网络 (bidirectional long short-term memory, BLSTM) (见图5) 执行逐帧检测, 并且结合基于隐藏半马尔可夫模型的持续时间控制建模技术.这种方法可以精确地模拟每个声音事件的持续时间, 并且可以执行逐个序列的检测, 无需像传统的逐帧方法那样采用阈值处理.同时为了有效减少在噪声条件下经常发生的声音事件插入错误, 该方法引入了基于二进制掩码的后处理, 通过声音活动检测网络识别具有任何声音事件活动的片段.这种方法受语音识别系统中使用的BLSTM-HMM混合系统的启发, 相比传统的NMF以及基本的BLSTM方法有明显的改进.
声音事件识别的过程是先将音频信号进行预处理, 提取相应的声学特征, 然后再将提取到的特征输入到预先训练好的声学模型和预先训练好的分类器中, 最后由声学模型输出持续时间的概率和分类器输出相应的音频标签, 实现一个识别分类的过程.分类器的训练分成3种:无监督学习、半监督学习和监督学习.通常需要大量的数据集进行训练, 声音事件识别才能得到一个较为准确的结果.
图5 BLSTM模型Fig.5 BLSTM mode
对白的音质缺陷检测按频谱可以分成两类:一种是在原有语音的频谱上叠加背景噪声的频谱, 另一种是在语音频谱上产生了畸变.这两种情况都可以将其转换为相应的音频特征, 然后再对声学模型进行训练, 从而实现音质缺陷的自动检测.在噪声条件下进行SED常见的问题是插入错误导致性能下降, 即在没有实际声音事件发生时, 也会将背景噪声识别成一个声音事件.因此在SED模型中, 通常加入一个声音活动模型 (Sound active detection, SAD) .SAD网络能够识别具有任何类型的声音事件活动的片段, 类似于语音识别领域的话音活动检测 (voice activity detection, VAD) [14].背景噪声属于对白缺陷的一种缺陷, 在模型的选择上可以摒弃SAD网络, 减少时间成本.对比于DCASE (detection and classification of acoustic scenes and events) 2016挑战的结果, 影视对白缺陷检测任务在分类器的标签分类数量上减少很多.同时考虑到模型的复杂程度和易实现性, 分类器模型选择LSTM网络.在2013年多源环境计算听觉挑战赛中, 研究人员证实了LSTM结构能够有效地利用上下文来学习由噪声而失真的声学特征.只要提供足够数量的网络单元和正确的权重矩阵, 就可以计算任何传统计算机能计算的问题, 因此, LSTM网络更适用于影视对白缺陷检测.声音事件的持续时间由隐半马尔可夫模型 (hidden semi-Markov model, HSMM) 输出.与传统的HMM模型相比, HSMM引入了一个参数持续时间概率分布来明确地模拟每个状态的持续时间的能力.在HMM中, 状态持续时间概率由状态转移概率表示, 因此, HMM状态持续时间概率固有地随时间指数地减小.HSMM能够很好解决这个问题, 从而使模型的精准度更高.模型的具体性能还有待进一步实验来证明.
3、 结束语
目前正值中国电影市场蓬勃发展的时期, 但是国内的制作工艺仍落后于北美等发达国家.这就需要电影工作者提高制作工艺.语音对白作为电影声音中的重要组成部分, 在整个电影的制作流程中需要耗费大量的时间去处理, 因此影视对白音质缺陷检测的提出具有较大的理论意义和实用性.
深度神经网络在语音识别[15,16]和自然语言处理[17]等领域均取得了成功.在大多数领域中, 神经网络都代表了先进的技术.但是深度学习仍具有局限性, 识别的准确度依赖于大量的数据进行训练.目前, 经常使用的评定测试集是CHi ME-Home数据集和TUT Sound Events2016, 这些数据被用作DCASE2016挑战1的一部分.目前, 还没有关于对白缺陷的训练集, 有关人声的训练集更多地集中在说话人识别、语音识别等方面.因此建立一个包含各种缺陷的数据库是关键的一步.另外, ADR素材缺陷中的齿声和口水声的时长过短, 提取的特征需要提高提取的精度才能有效地进行区分.提取精度的提高是建立在牺牲计算的时间成本基础上.虽然在网络构建上缺陷检测的复杂度低于常规的SED网络, 但是实际计算过程中缺陷检测仍有很多不可预知的困难需要去解决
参考文献:
[1]Foggia P, Petkov N, Saggese A, et al.Reliable detection of audio events in highly noisy environments[J].Pattern Recognition Letters, 2015, 65 (C) :22-28.
[2]Goetze S, Schroder J, Gerlach S, et al.Acoustic monitoring and localization for social care[J].Journal of Computing Science and Engineering, 2012, 6 (1) :40-50.
[3]Salamon J, Bello J P.Feature learning with deep scattering for urban sound analysis[C]//23rdEuropean Signal Processing Conference (EUSIPCO) .2015:724-728.
[4]Wang Y, Neves L, Metze F.Audio-based multimedia event detection using deep recurrent neural networks[C]//IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) .2016:2742-2746
[5]Stowell D, Clayton D.Acoustic event detection for multiple overlapping similar sources[C]//IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) .2015, DOI:10.1109/WASPAA.2015.7336885.
[6]Cai R, Lu L, Hanjalic A, et al.A flexible framework for key audio effects detection and auditory context inference[J].IEEE Transactions on audio, speech, and language processing, 2006, 14 (3) :1026-1039.
[7]Mesaros A, Heittola T, Dikmen O, et al.Sound event detection in real life recordings using coupled matrix factorization of spectral representations and class activity annotations[C]//IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) .2015:151-155.
[8]Cakir E, Heittola T, Huttunen H, et al.Polyphonic sound event detection using multi label deep neural networks[C]//International Joint Conference on Neural Networks (IJCNN) .2015, DOI:10.1109/IJCNN.2015.7280624.
[9]Cakir E, Ozan E C, Virtanen T.Filterbank learning for deep neural network based polyphonic sound event detection[C]//International Joint Conference on Neural Networks (IJCNN) .2016, DOI:10.1109/IJCNN.2016.7727634.
[10]全国广播电视标准化技术委员会.广播节目声音质量主观评价方法和技术指标要求:GB/T16463—1996[S].北京:中国标准出版社, 1996.
[11]Hayashi T, Watanabe S, Toda T, et al.Duration-controlled LSTM for polyphonic sound event detection[J].IEEE/ACM Transactions on Audio Speech&Language Processing, 2017, 25 (11) :2059-2070.
[12]Heittola T, Mesaros A, Eronen A, et al.Context-dependent sound event detection[J].EURASIP Journal on Audio, Speech, and Music Processing, 2013, DOI:10.1186/1687-4722-2013-1.
[13]Cakir E, Parascandolo G, Heittola T, et al.Convolutional recurrent neural networks for polyphonic sound event detection[J].IEEE/ACM Transactions on Audio Speech&Language Processing, 2016, 25 (6) :1291-1303.
[14]Sohn J, Kim N S, Sung W Y.A statistical model-based voice activity detection[J].IEEE Signal Processing Letters, 1999, 6 (1) :1-3.
[15]Graves A, Mohamed A, Hinton G.Speech recognition with deep recurrent neural networks[C]//IEEE international conference on Acoustics, speech and signal processing (ICASSP) .2013:6645-6649.
[16]Sainath T N, Vinyals O, Senior A, et al.Convolutional, long short-term memory, fully connected deep neural networks[C]//IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) .2015:4580-4584.
[17]Karpathy A, Li F F.Deep visual-semantic alignments for generating image descriptions[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR) .2015:3128-3137.