文献检索论文

摘 要: [目的/意义] 文章从科技文献检索应用的背景出发,提出了目前检索系统未能满足广大科研工作者的语义检索需求,为了解决这一问题,提出了多维语义索引的新思路。[方法/过程] 首先在总结归纳国内外相关研究中主要的语义索引构建方法的基础上得出了要采用的构建方法,然后详细介绍了多维语义索引的设计思路和整体框架,最后以面向物理领域科技文献为例,介绍了其具体实现流程。[结果/结论] 从如何针对科技文献内部细粒度知识及其之间的关联关系揭示的角度验证了多维语义索引在语义检索实际应用中的良好效果。
关键词: 科技文献检索; 多维语义索引; 细粒度; 构建方法; 本体; 自然语言处理技术;
Abstract: [Purpose/significance] Based on the application of scientific literature retrieval, we found that current scientific literature retrieval system cannot meet the semantic retrieval needs of the majority of scientific researchers. In order to solve this problem, we proposed a new idea for multidimensional semantic indexing of scientific literature.[Method/process] Based on previously prevalent methods of semantic indexing construction, we proposed a new construction method and illustrated the design idea and the overall framework of the multidimensional semantic indexing oriented to the scientific literature. Finally, the specific implementation process was introduced with the physics-oriented scientific literature as an example.[Result/conclusion] The good effect of multidimensional semantic indexing in the practical application of semantic retrieval is verified from the perspective of how to reveal fine-grained knowledge within scientific literature and the association relationships between them.
Keyword: scientific literature retrieval; multidimensional semantic index; fine-grained; construction method; ontology; natural language processing technology;
科技文献检索是广大科研工作者研究过程中不可或缺的一项工作,在电子文献资源高速增长的时代,传统的文献检索系统查询效果往往难以满足用户的语义检索需求。究其原因,这些检索系统一般以整篇文献为单位揭示文献的粗粒度知识,未能对文献内部细粒度知识进行深入语义理解与揭示,这样导致其检索结果不尽如人意。因此如何实现文献内部细粒度知识的语义检索成为学者们研究的重点问题,这个问题的解决能够使科研工作者快速掌握其主要知识内容, 对于揭示其中的科学知识具有重大意义。

为此,本文尝试从揭示文献内部细粒度知识的角度出发,研究面向科技文献的多维语义索引的构建思路及实现过程,并将其应用到语义检索系统中。本文主要针对其设计思路、实现过程以及实际应用效果进行论述。
1、 语义索引构建方法相关研究
近年来,语义索引领域的相关研究得到国内外学者的广泛关注。语义索引的研究涉及信息检索、人工智能、数据挖掘等众多领域,相关的应用实践较为丰富,综合看来主要采用了3种实现方法:
1)基于词表和知识管理技术。词表和知识管理技术包括分类与词表管理、本体管理、知识图谱等。从资源组织的角度来看,基于词表和知识管理技术构建语义索引就是基于已有的词表、本体和知识图谱对文档进行语义描述,再对语义描述后的文档构建语义索引。
GoPubMed[1]利用Gene本体和MeSH词表对PubMed文献进行语义标引, 为标引出来的生物医学概念建立语义索引,在检索过程中,用户可通过浏览与检索词相关的生物医学概念来规范检索输入。Buscaldi等[2]介绍了一种通过本体标注文档中概念的语义检索系统YaSemIR,不同领域下的本体都适用这个系统。于晓巍结合本体和索引技术,设计出基于本体的文本标引系统,并提出了基于本体的路径索引和倒排索引结合的语义索引方法[3]。Google基于知识图谱(Knowledge Graph)里描述的人、地点、物体间的相互关系构建语义索引[4]。Springer Nature基于科研图谱(SciGraph)里描述的科研资助机构、科研项目、会议、科研单位和出版物的信息建立语义索引[5]。
2)基于隐语义索引。隐语义索引(Latent Semantic Indexing,LSI)又称为潜在语义索引,它是利用统计方法计算得到文档中词汇之间的上下文语义关系,并为其构建语义索引。Roger等考虑了词语对的关联性,并依据关联性强度快速地构建了一个潜在语义索引分析系统[6]。莫海波在支持向量机分类算法和改进的K-近邻算法的基础上,利用隐语义索引对文档进行分类[7]。
3)基于自然语言处理技术。自然语言处理技术(NLP)包括命名实体识别、关系抽取、文本分类等。从智能化处理角度来看,基于自然语言处理技术构建语义索引通常指对文档进行语义标注,然后再为语义标注后的文档构建语义索引。Yan 等提出了一种利用卷积神经网络(CNN)学习语义表示来解决生物医学抽象索引的新模型,并设计了生物医学抽象文档语义索引的比较实验,在MEDLINE数据集上的实验结果表明,该模型比传统模型具有更好的性能[8]。
Quertle[9]是一个关系驱动的生物医学文献检索工具, 它首先使用自然语言处理技术从生物医学文献中抽取生物医学实体(如疾病、基因、药物)以及实体之间的一般或特殊关系,然后建立语义关系索引、关键词索引和辅助索引三种索引, 用于查找用户输入的检索词和提问, 并返回检索结果。
NCBI, NLM, NIH推出的LitVar是基于2700万PMC摘要和180万PMC全文进行语义标注,利用Bioc XML格式处理了全部PubMed摘要和PMC全文,然后使用实体标记提取所有变异及其相关实体(即基因、疾病、化学和物种)等信息,最后为提取的实体及归一化关系构建语义索引[10]。
伦敦大学/南京大学推出的SemEHR是基于自然语言处理技术标注电子健康档案(EHR)数据,然后针对这些数据创建SemEHR语义索引[11]。
通过以上分析,国内外对构建语义索引方法的研究主要集中在基于本体和基于自然语言处理技术。这两者都有其不足之处:基于本体的方法无法充分揭示蕴含在特定领域科技文献内部的丰富语义信息;基于自然语言处理技术的方法成本比较高,而且语义索引质量好坏取决于选用的自然语言处理技术。因此,本文决定结合这两者构建语义索引,具体思路是:通过自然语言处理技术对科技文献进行语义标注,挖掘出本体中没有描述的知识对象以及知识对象之间的知识关系,这对基于本体的方法是一个很好的补充。整个思路实际上是综合考虑了两者的优势互补,基于自然语言处理技术构建的语义索引可以补充基于本体构建的语义索引,补充后的基于本体构建的语义索引又可以更好地提升自然语言处理技术的性能,获得更加丰富的文献内部语义信息,从而反过来更新基于自然语言处理技术构建的语义索引。这样,两者都得到不断的补充、更新,形成互利互助,从而构建更细粒度、更丰富的语义索引。
2、 面向科技文献的多维语义索引的设计
科技文献里蕴含着丰富的语义知识,科技文献的知识组织可以按照以下四个维度进行组织:第一维度是文章描述层, 对文章的标题、作者、摘要、发布时间等基本元数据表达揭示;第二维度是文本句子层, 将文章摘要切分成句子, 对句子所属语步类型(在科技论文的摘要中,研究者一般需要说明其研究的目的、方法、结果以及结论等要素,这些要素被称为科技论文摘要的语步,能够精炼地反映科技论文所表的主要意图[12])进行揭示;第三维度是知识关系层, 用于对知识关联关系表达揭示;第四维度是知识对象层, 对文本中识别出来的通用术语和领域术语表达揭示。按照上述四个维度进行组织,可以形成科技文献丰富语义知识多维组织体系,如图1所示。
图1 科技文献丰富语义知识多维组织体系
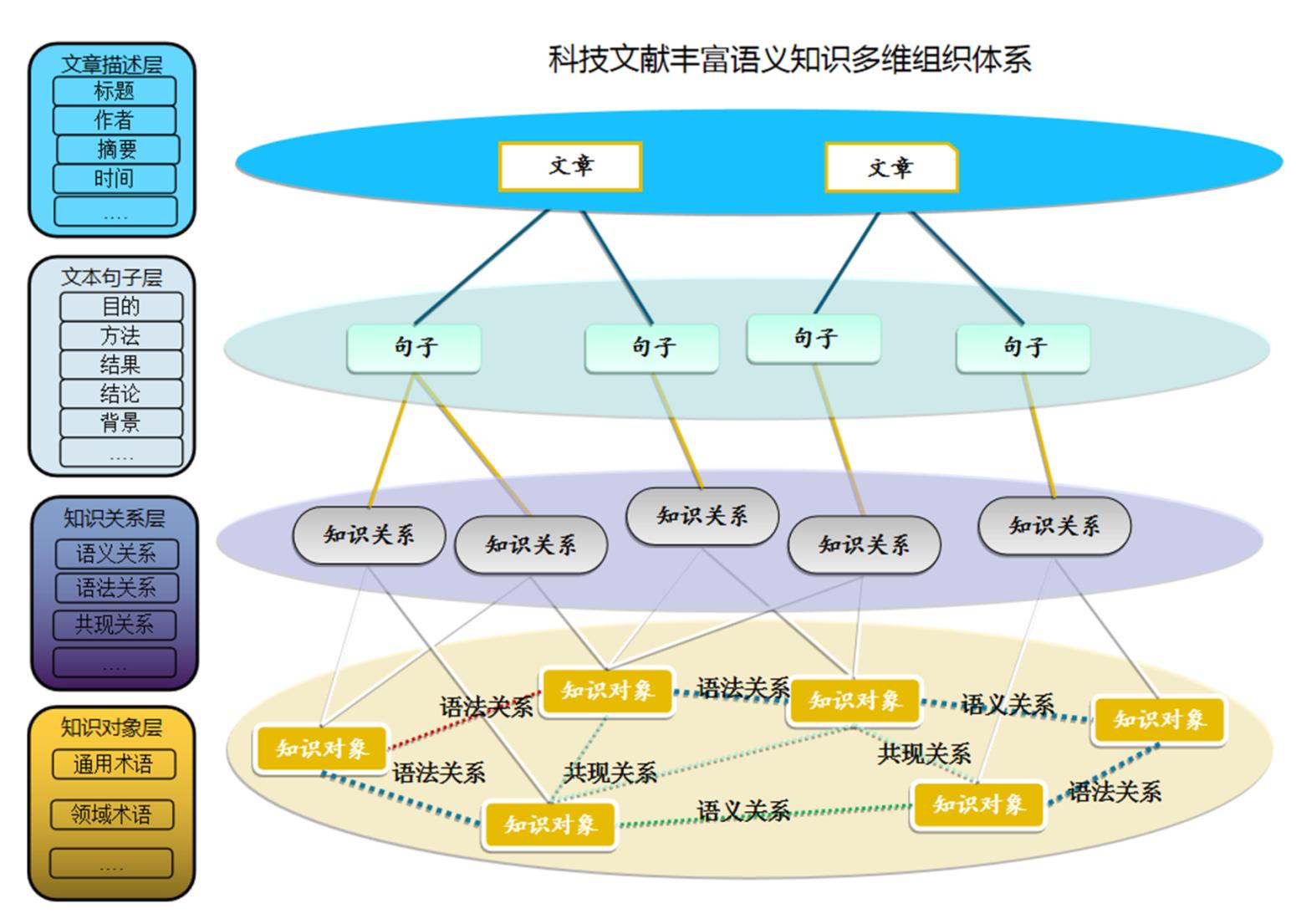
因此,要对科技文献内部语义知识进行细粒度的组织和揭示,其多维语义索引体系也要按照上面四个维度来构建,主要分为:
1)文献索引,即对文献的元数据信息、包含的术语及语步识别内容进行索引;
2)句子索引,即针对文本句子层的所属语步类型进行索引,主要是5种语步类型Methods(方法)、Objectives(目的)、Results(结果)、Conclusions(结论)、Background(背景);
3)知识对象索引,即针对文中包含的术语进行索引,主要包含基于自然语言处理技术抽取的普通术语及本体规范术语;
4)知识关系索引,即基于本体描述的明确关系建立语义关系索引,同时基于自然语言处理技术分析句法构建语法关系索引,这些知识关系可以根据知识对象之间的搭配关系分为语法关系、组合关系、修饰关系、连接关系。
本文旨在改进现有科技文献检索系统以整篇文献单维呈现无法揭示语义知识从而无法实现语义检索的不足,按照上述四个维度设计的多维语义索引,将科技文献内部丰富的语义知识以及知识之间丰富的关联关系等深层信息,利用多维语义索引重新组织,在检索结果中以多维分面的方式充分揭示出来。
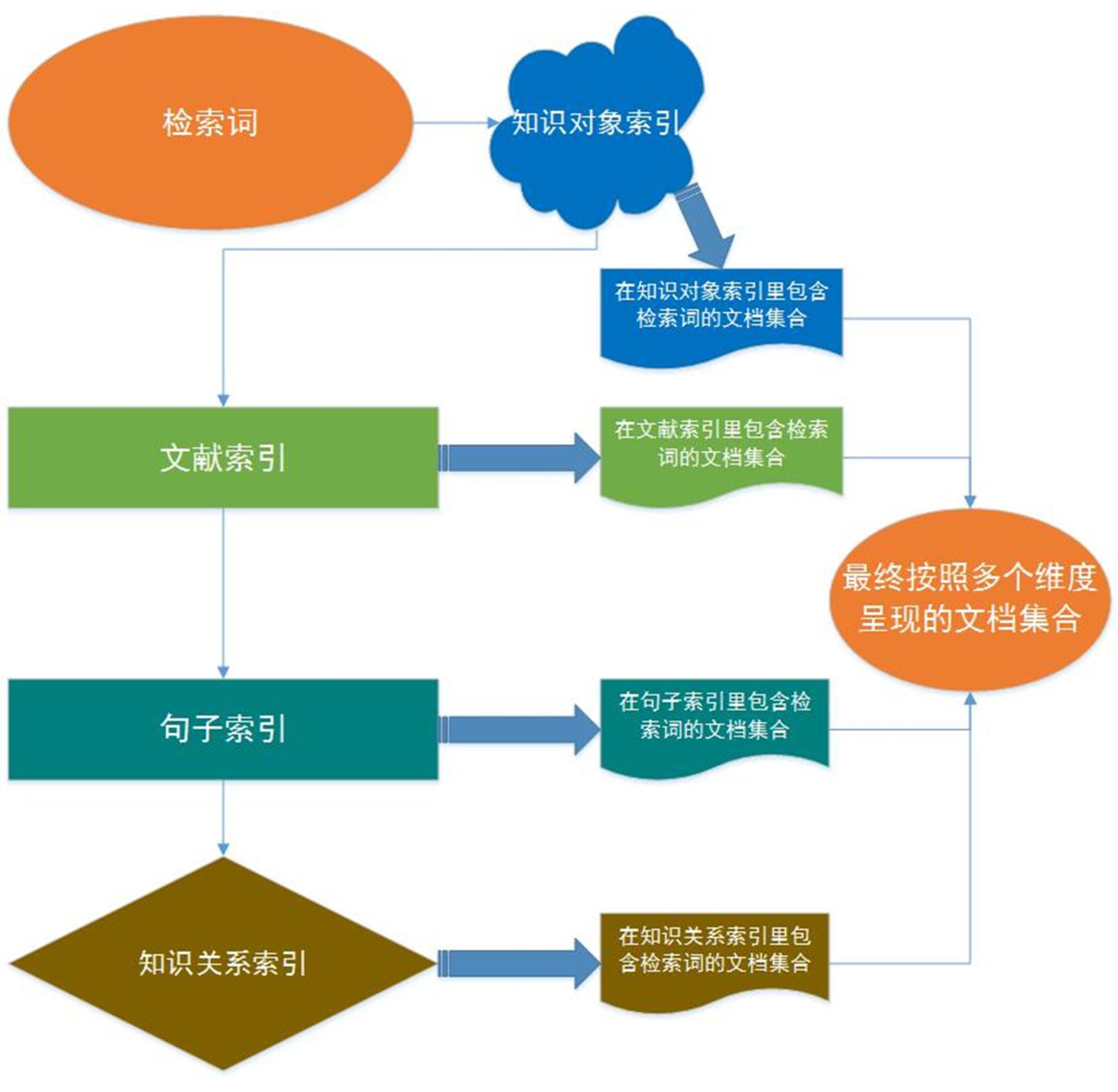
按照上述多维语义索引构建的科技文献检索系统具体的检索查询思路是:遵循用户使用流程,从检索关键词出发,查询知识对象索引对输入关键词进行语义识别和语义消歧,确定文献中的知识对象及其所属的范畴和类型;然后查询文献索引得到包含元数据及相关知识内容的文献信息;接着查询句子索引确定知识对象所属的语步类型以及句子共现术语;最后查询知识关系索引,发现检索词和文中知识对象的组合搭配关系;这些索引之间并不是独立的关系,每查询一个索引就会得到一个特定的检索结果集,最终返回给用户一个检索结果交集。
根据以上思路,本文设计的面向科技文献的多维语义索引整体框架如图2所示。
图2 面向科技文献的多维语义索引架构图
3、 面向科技文献的多维语义索引的实现
3.1 、工具的选型以及本体的选择
当前用于构建索引的工具主要有Solr和ElasticSearch两种,Solr和ElasticSearch各有优缺点。结合本文的实际应用场景分析,科技文献检索相对来说时效性要求不是那么高,更偏向于传统搜索应用,另外Solr的分面搜索的优点更能满足本文设计多维语义索引的需求,因此选择利用Solr来构建多维语义索引。通过利用Solr的分面机制设计多维语义索引,能够充分发掘揭示科技文献内部的丰富语义知识,从而满足用户对语义检索的需求。
在本体选择上,因为笔者需要构建物理领域科技文献语义检索系统,选取的是物理学本体ScienceWise。ScienceWise本体包含了物理学术语及其范畴(分为4个一级范畴和47个二级范畴)、16种语义关系(分为通用语义关系和领域特定语义关系)等。
3.2 、文献索引的结构
文献索引结构的主要字段为paperId(文章Id)、title(标题)、author(作者)、publishTime(发布时间)、abstract(摘要)、objects(包含的术语)、methods(方法)、objectives(目的)、results(结果)、conclusions(结论)、background(背景)等。与传统文献索引的区别在于这里还包含了语步识别内容,因此在检索结果展示界面可以进行传统摘要和结构化摘要的双重呈现,可以让用户迅速了解某篇文献的整体内容。
3.3 、句子索引的结构
句子索引结构的主要字段为paperId(文章Id)、content(句子内容)、moveType(句子所属语步类型)、objects(包含的术语)、sentenceOrder(在摘要中的顺序)等。与传统的句子索引不同,这里的句子索引里包含了句子所属语步类型,通过语步类型可以在检索结果界面揭示有哪些方法里包含了检索关键词,哪些结论里包含了检索关键词等,从而让用户迅速了解研究主题的整体研究脉络。
3.4 、知识对象索引的结构
知识对象索引的主要字段为paperId(文章Id)、objectName(术语名称)、isScienceWise(是否是ScienceWise本体规范术语)、topCategory(在ScienceWise中所属的一级范畴)、secondCategory(在ScienceWise中所属的二级范畴)、weight(知识对象权重)等。这里术语与一般的科技文献检索系统里的主题词不同,它通过ScienceWise赋予了术语特定的语义信息,将这些术语划分到其细粒度的物理领域。
另外,知识对象权重是指知识对象在科技文献中的所占比例,权重越高,这个知识对象就越能代表科技文献。传统的TF-IDF权重计算方法通过词频统计信息反映了知识对象对文档的表达,但它没有考虑到知识对象的语义信息,而科技文献中的知识对象之间存在着特定的知识关系,知识对象存在于哪种语步类型,这些都是知识对象语义信息要考虑的方面,因此计算知识对象权重应该是在传统的TF-IDF权重计算方法的基础上综合考虑知识关系权重以及语步类型权重。它是对传统TF-IDF权重计算方法的改进,弥补了TF-IDF权重计算方法在语义方面的不足,而且在检索词与知识对象无关时,可以自动调整为传统的关键词检索。
按照传统的TF-IDF权重计算方法,知识对象在文档中的权重为:
式中,p表示知识对象在文档中出现的次数;q表示文档的知识对象总数;N表示文档总数;表示包含该知识对象的文档数,当所有文档都不包含该知识对象时,分母为0,因此这里分母要加上1。
在科技文献中,知识对象间搭配关系的不同,比如连接、组合、修饰,它们对知识对象语义信息的贡献大小也会不一样。本文用知识对象间的知识关系权重来表示不同类型的知识关系对知识对象语义信息的贡献比例,在[0,1]范围内赋值。本文选取10万篇来自arXiv数据库的物理领域科研论文作为初始数据集进行语义标注,通过对语义标注结果进行统计分析,其中,修饰关系共有236051组,连接关系共有169962组,组合关系共有195928组,三者比例约为1:0.7:0.8,因此本文采用的知识关系类型及分配权重如表1所示。
表1 知识关系类型及分配权重

在文档中,知识对象有N个的知识关系,表示为,另外,的分配权重为,则知识对象的知识关系权重为。那么,知识对象在文档中的知识关系权重可以表示为:
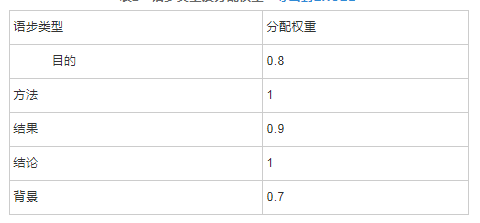
知识对象权重还要考虑语步类型权重,语步类型主要有目的、方法、结果、结论、背景这5种类型,每种语步类型对知识对象语义信息的贡献大小也不一样,同样,在[0,1]范围内赋值。同理,通过对语义标注结果进行统计分析,目的共有158692句,方法共有190964句,结果共有175898句,结论共有191195句,背景共有133837句,五者比例约为0.8:1:0.9:1:0.7,因此其语步类型及分配权重如表2所示。
表2 语步类型及分配权重
在文档中,知识对象有N个的语步类型,表示为,另外,的分配权重为,则知识对象的语步类型权重为。那么,知识对象在文档中的语步类型权重可以表示为:
知识对象的知识关系权重和语步类型权重两者在对知识对象权重的贡献上同等重要。因此本文采用的知识对象权重的计算公式可以表示为:
3.5 、知识关系索引的结构
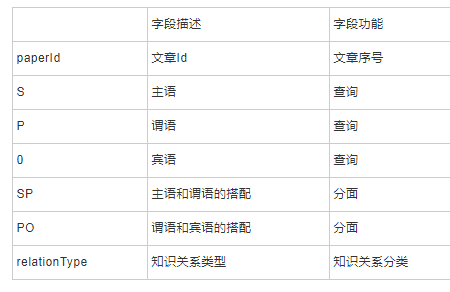
本文参考知识图谱RDF三元组的表达方式将知识关系用三元组S-P-O表示,其中,S代表三元组主语,P代表三元组谓语、O代表三元组宾语。为了揭示知识关系,本文在知识关系索引中增加了SP字段(主语和谓语的搭配)以及PO字段(谓语和宾语的搭配),当输入检索词为主语S时对PO字段分面揭示,当输入检索词为宾语O时对SP字段分面揭示。另外,还增加一个知识关系类型字段relationType,通过这个字段可以从检索词搭配角度多方位呈现知识对象之间的知识关系。知识关系索引结构如表3所示。
表3 知识关系索引结构
3.6、 多维语义索引的查询
以上内容分别讲述了多维语义索引的结构,多维不是多个,这几个索引之间并不是独立的关系,它们都有一个共同的字段paperId。因此,要想实现多维语义索引的分面揭示,查询的时候要对查询结果按照共同字段paperId来进行综合,其具体实现步骤可以分为五步:
1)查询知识对象索引,获取匹配的知识对象,并可以得到一个paperId集合;
2)查询文献索引,获取文献元数据相关信息,并可以得到一个paperId集合;
3)查询句子索引及文献索引,获取句子共现术语以及文章共现术语,并可以得到一个paperId集合;
4)查询句子索引,获取检索词在文章中的知识关系(连接关系、修饰关系、组合关系、语法关系),并可以得到一个paperId集合;
5)最终将上述paperId集合并取其交集,即为返回给用户的最终结果。其实现步骤核心代码如图3所示。
图3 多维语义索引的查询

4、 实际应用效果
基于上述设计思路和实现过程,本文设计和实现了“物理领域科研论文自动语义标注检索系统”。该系统选取10万篇来自arXiv数据库的物理领域科研论文作为初始数据集,其中,对于检索词“dark matter”,一共发现4643篇文章,其检索结果界面如图4所示。
图4 检索dark matter结果页面
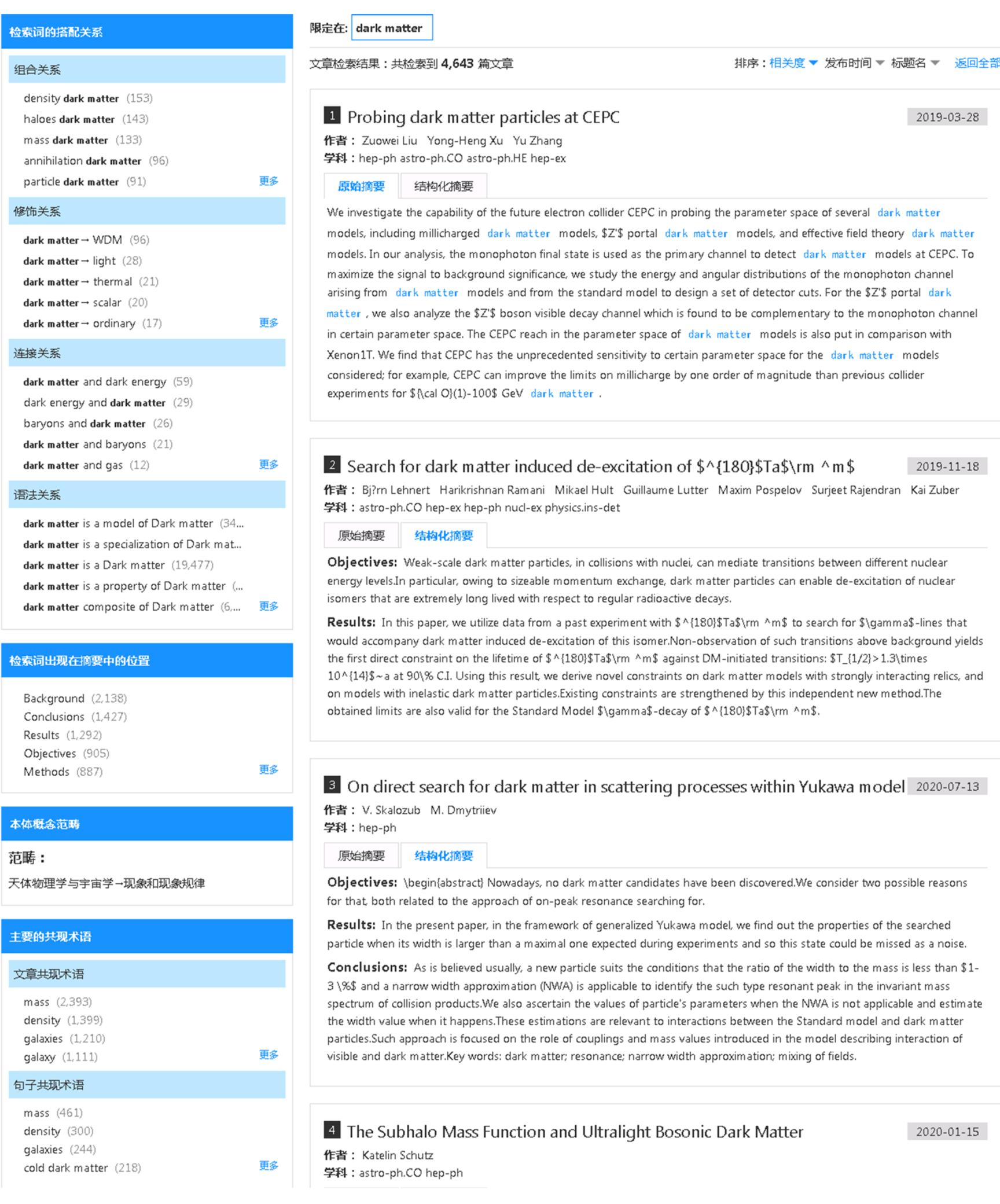
如图4左侧分面导航所示,系统通过检索词的搭配关系分面揭示了检索词“dark matter”的知识关系,可以帮助发现潜在知识。还可以通过检索词出现在摘要中的位置分面发现文章摘要中背景中包含检索词的句子有2138个,结论中包含检索词的句子有1427个,结果中包含检索词的句子有1292个,方法中包含检索词的句子有887个,目的中包含检索词的句子有905个。通过这个分面揭示了检索词“dark matter”的整体研究脉络,从而辅助用户在科研选题时在目标、方法、结论等方面的创新性提供快速的参照。
本文结合了基于本体和自然语言处理技术构建语义索引,图4也体现了这两者的优势互补,前面两个分面已经展示了基于自然语义处理技术构建的语义索引,本体概念范畴分面则从基于本体构建语义索引的角度揭示了检索词所属的物理学科范畴,为用户迅速了解其范畴提供了参考借鉴。另外通过摘要中高亮显示的知识对象可以跳转到该知识对象在ScienceWise本体中的相关关系界面,如图5所示。该图展示了该知识对象在本体中与其他物理学概念的相关关系,主要由两类关系组成:入关系和出关系,其中入关系指入该概念的相关关系,出关系是该概念指出的相关关系。例如,对于知识对象“dark matter”,其中一条出关系为“Dark matter is a part of BSM physics”,表示“dark matter”与概念“BSM physics”存在“is a part of”关系,该关系的方向是从“dark matter”指向“BSM physics”。通过构建这些相关关系语义索引可以让用户通过本体里相关关系去发起下一步检索,让用户发现更多相关的内容,这个是单独基于自然语言处理技术构建语义索引无法满足的。
图5 知识对象在本体中的相关关系 下载原图

本文还从分面角度调研了几种主流的科技文献检索系统,它们大多从科技文献的外部特征进行分面揭示,也有少部分检索系统针对文献中的相关主题进行分面揭示。而本文设计开发的物理领域科研论文自动语义标注检索系统主要是从科技文献内部的语义知识进行分面揭示,通过多维度的分面揭示方式能够充分发掘揭示既有语义关系和潜在语义关联,从而满足科研工作者的语义检索需求。
5、 结论
在传统的检索系统不能满足科研工作者语义检索需求的背景下,多维语义索引的构建对满足其语义检索的迫切需求具有重要的实用价值。本文围绕这个问题展开研究,给出了多维语义索引的设计思路和实现过程,验证了其在语义检索实际应用中的良好效果。在未来的工作中将进一步优化索引,并推广到其他不同的领域中。□
作者贡献声明:张敏,论文撰写及修改。丁良萍,论文校对。刘欢,数据整理。
参考文献
[1] DOMS A,SCHROEDER M. GoPubMed: exploring PubMed with the gene ontology[J]. Nucleic acids research,2005,33(Web Server issue):783-786.
[2] BUSCALDI D,ZARGAYOUNA H. YaSemIR: yet another semantic information retrieval system[C].Proceedings of the Sixth International Workshop on Exploiting Semantic Annotations in Information Retrieval. San Francisco,2013:13-16.
[3] 于晓巍.基于本体的文本标引的研究与实现[D].沈阳:沈阳工业大学,2009.
[4] DAVID A.谷歌语义搜索[M].程龚,译.北京:人民邮电出版社,2015:156.
[5] Springer Nature SciGraph[EB/OL].[2021-01-05].http://h-s.www.springernature.com.forest.naihes.cn/cn/researchers/scigraph.
[6] ROGER B B. An empirical study of required dimensionality for large-scale latent semantic indexing applications[C].Proceedings of the 17th ACM Conference on Information and Knowledge Management. Napa Valley,2008.
[7] 莫海波.潜在语义索引分类模型的研究与改进[D].大连:大连理工大学,2008.
[8] YAN Y,YIN X C,ZHANG B W, et al. Semantic indexing with deep learning: a case study[J].Big Data Analytics,2016,1(1):1-13.
[9] COPPERNOLL-BLACH P. Quertle: the conceptual relationships alternative search engine for PubMed [J].Journal of Medical Library Association,2011,99(2):176-177.
[10] ALLOT A,PENG Y,WEI C H, et al. LitVar: a semantic search engine for linking genomic variant data in PubMed and PMC[J].Nucleic Acids Research,2018,46(Suppl.8):530-536.
[11] WU H H,TOTI G,MORLEY K I, et al. SemEHR: a general-purpose semantic search system to surface semantic data from clinical notes for tailored care, trial recruitment, and clinical research.[J].Journal of the American Medical Informatics Association: JAMIA,2018,25(5):530-537.
[12] 张智雄,刘欢,丁良萍,等.不同深度学习模型的科技论文摘要语步识别效果对比研究[J].数据分析与知识发现,2019,3(12):1-9.

随着科学技术的迅速发展, 农业科研领域的学科分类越来越多、越细, 研究领域也在不断延伸, 与之相应的农业信息资源也日益剧增。...

科技文献检索是指根据学习和工作的需要获取科技类文献的过程,本篇文章为大家介绍几篇科技文献检索论文的范文,来探讨了解一下科技文献检索中会遇到哪些问题,希望对大家写作此类论文时也有所帮助。 ...

进行科研活动首先要确立研究题目、明确目的, 接着才是相关文献检索, 其次是进行文献综述、确立创新点, 然后进行科学试验, 分析试验现象和数据, 探求科学本质。因此, 一切科研活动离不开科技文献的检索。...

科技文献信息检索课程的设置目的是培养大学生的信息意识,着重提升学生信息素养与解决实际问题的能力。通过文献检索,人们可以快速掌握科技的最新成果及发展动态,了解最前沿的科学技术。...

介绍了国内主要科技文献检索的网络数据库系统, 依据科技文献查询工作的需求特点对网上信息资源进行收集整理, 并提供了可获得国内信息资源网址的数据库和信息资源高效快速的检索途径和检索方法。...