文献检索论文


1语义分析技术应用领域和价值
自本世纪初互联网普及以来,人们在互联网上的行为广义上可分为两类:获取信息和分享信息。其中,获取信息往往是每一位接触互联网用户的最初诉求。然而,面对数量庞大的互联网信息,要在其中获取到自己想要的内容,这在上 世 纪90年 代 搜 索 引 擎 问 世 之 前 并 非 易 事。1998年9月,美国google(谷歌)公司成立,并于同年推出一款功能强大的信息检索工具;2000年1月,百度公司率先推出了全球最大的中文搜索引擎。在此之后,各类互联网搜索工具大量涌现,用户在互联网中的搜索体验也得到显着改善。优秀的搜索引擎通常都是基于高效的语义分析算法构建,通过对语言的合理建模和分词,搜索引擎往往只需相当小的系统开销就能获得大量信息回馈。因此,搜索引擎在互联网信息检索中有着重要意义。
2基于语言分析的搜索引擎文本处理方法
文本处理通俗地讲是告诉计算机如何认识人类的单词。高质量的语义分析算法通常在一套好的文本处理机制之上完成建模,其中最重要的两个方法是:中文分词以及分词权重(Term Weighting)。当获取一段文本时,计算机该如何知道它的语法和词语构成?参考人脑对语言的反应,一般情况下应先做分词。分词即是将一段文字合理地拆分成若干词根以匹配参照词库。
2.1局部切分多次匹配方法
分别按照顺词序最大匹配、逆词序最大匹配、双词序最大匹配及最短路径拆分的方式逐一查找词库,只要能命中词库词根即切分,在设立编号后写入索引表。
2.2应用统计模型的切分方法
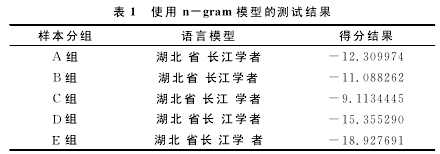
按局部切分多次匹配的方法进行分词后,对结果一般使用双数组Trie树进行存储,然后运用N元文法模型(n-gram)[1]统计模型找出最优路径,并在结果中遴选出最优切分方法。一个解决分词歧义的例子,如“湖北省长江学者”,根据词库的匹配情况切分出如下词根“湖北、省、长江、学者、湖北省、长江学者、省长、江学、江学者”,使用n-gram模型测算出语言模型得分,选出得分最高的模型作为最终切分方法。测算结果如表1所示,显然模型得分最高的C组同时也是最佳的分词方案。
2.3基于条件随机场(CRF)算法的由字组词切词方法
很多时候用户搜索的关键词句字与字中间的逻辑关系并非十分明显,如早期白话文、文言文、专业术语等。与基于隐马尔可夫模型的最短路径分词、N-最短路径分词相比,基于条件随机场(CRF[1])的分词对未登录词库的词根有更 好 的 支 持。使 用CRF预 测 串 中 每 个 字 的 标 注(tag),如以B、I、E、S 4个tag表示:开始(beginning)、包含(inside)、结束(ending)、单独(single),则“湖北省长江学者”的标注应为:“湖(B)北(I)省(E)长(B)江(E)学(B)者(E)”.CRF算法是目前分词效果相对较好的一种算法,它既可以像最大熵模型一样广泛加入各类特征(feature),又能够避免HMM的齐次马尔科夫假设。目前市面上包括谷歌和百度在内的多数搜索引擎都采用CRF算法构建语言模型[2].
2.4语言模型构建
语言模型狭义地说是一种概率模型,主要用来计算句子产生的组合。在公式P(m1,m2,m3…mn)中,n表示词的总数,根据条件概率Bayes Rule,则有:P(m1,m2,m3…mn)= P(m1)P(m2|m1)P(m3|m1,m2)…P(mn|m1,m2…m(n-1))。对于N-gram统计模型得到的语言模型通常也是最简单的语言模型。根据马尔科夫假设,句中每个单词与其前n-1个单词有关,则单词mn的条件概率仅仅依赖于它之前的n-1个词,显然有P(mn|m1,m2…m(n-1))=P(mn|m(n-k+1),m(n-k+2)…m(n-1))。n取值越大,模型值域越大,n值越小,模型可靠性越高。然而N-gram语言模型虽然简单有效,但也有局限性。由于仅考虑了词之间的位置关系,在词间相似度、语法语义等方面还存在明显不足,更为复杂的神经网络语言模型正好填补了这片空白。神经网络语言模型在N-gram上将每个单词m(n-k+1),m(n-k+2)…m(n-1)映射到词向量,再将每个词的向量组合构成更大向量作为神经网络输入,输出则是P(mn),词语间的相似性最终通过词向量来表现。映射结构如图1所示。

3分词权重设置
Term Weighting,即分词权重。对于信息检索结果,用户通常更愿意看到匹配度最高、最贴近搜索条件的结果列于高 位 显 示。在 对 文 本 分 词 后,紧 接 着 需 要 对 每 个term计算权重,重要的term应给予高权重。比如“湖北省长江学者”的Term Weighting结果中,“长江”的权重很可能是0.8,而“湖北省”的权重可能是0.5,而“省长”的权重可能不足0.1.
Term Weighting结果在文本检索中对于文本相关性、核心词提取等过程都有非常重要的参考价值。采用合理的Term Weighting计算方法会得出较为理想的分词权重值,常见的算法有Tf-Idf[3]算法和Okapi、MI、LTU、ATC、TF-ICF等算法。
4主题模型(Topic Model)应用于信息检索的方法
上文提到了语义分析中的一些文本处理方法,对于一条文本信息,在对其进行分词和Term Weighting打分后便要开始执行更高层的语义分析任务,当前业界使用较多的主体模型是LDA,其算法执行效率高,能够较好地解决关键词的主题关联问题。
4.1 LDA训练算法
LDA[4]的推演方法可以参考有关文献,本文主要讨论如何 训 练LDA.目 前 通 常 的 做 法 是 基 于 吉 布 斯 采 样(gibbs sampling[5])的工序。算法如下:
Step1:任意初始化每个词的主题(Topic),并计算两个频率计数的矩阵。
D-T矩阵N(t,d),用于描述文档的主题频率分布情况;W-T计数矩阵N(w,t),用于描述每个主题下词的频率分布情况。
Step2:顺序遍历训练语料,按照概率公式重新采样Topic,并更新两个矩阵的计数。
Step3:重复Step2,直到模型收敛。
4.2主题模型应用领域
主题模型已经可以广泛应用于文本分类、主题词归类、信息相关性检索、精确广告投放等。具体而言,基于主题模型可以很方便地计算出文本或用户的主题分布,并将其当作用户特征充分利用。
4.3文本分类
文本分类是最常见的文本语义分析任务,好的文本分类能够有效提高资源耦合度,在执行检索时有效提高命中率。文本分类方法通常比较简单,但工作量较大,内容复杂。基本上所有的机器学习方法都可以用来作文本分类,常用的有lR、MAXENT、SVM等算法。
5图片语义分析法在图片搜索中的应用
图片搜索是现代搜索引擎提供的一个重要功能,然而对于图片本身而言,并没有相关的关键词信息。如何根据文字检索出图片,是搜索引擎设计开发必须考虑的难点问题。采用基于图片的语义分析方法是一种较为良好的解决方案。
5.1卷积的作用
计算机在处理图像时经常使用卷积算法,如高斯变换即是对图像进行卷积。计算机对图像用一个卷积核进行卷积运算,其实际是一个滤波的过程,并藉此可以得到一个图像的权重模板。
5.2卷积神经网络
卷积神经网络是一种特殊简化的深层神经网络模型,每 个卷积层都是由多个卷积滤波器组成。在卷积神经网络中,图像的局部感受区域被作为层级结构的最底层输入,信息逐层上导,每层均通过多个卷积滤波器来获取图片特征。
5.3一种基于卷积神经网络的图片主题提取方法
首先对图片使用深度卷积神经网络和深度自动编码器提取图片的多层特征,并据此提取图片的虚拟关键词(visual word),建立索引。然后对大量种子图片作语义分析,根据相似种子图片的语义推导出新图片的语义。
6结语
在互联网项目开发过程中,信息检索通常是项目开发计划中的早期任务,关联到全系统的各级功能,因此是在系统架构设计过程中应充分考虑的因素。本文主要从文本处理、主题模型及图片卷积分类抽取特征信息3个方面探讨了语义分析算法在实施互联网信息检索工程中的一些方法,希望本文能给使用语义分析算法进行互联网项目尤其是搜索引擎项目开发的同行提供参考。
参考文献:
[1]宗成庆。统计自然语言处理[M].北京:清华大学出版社,2008.
[2]冯志伟。自然语言处理的形式模型[M].合肥:中国科学技术大学出版社,2010.
[3]刁倩,张惠惠。文本自动分类中的词权重与分类算法[J].中文信息学报,2000(3):25-29.
[4]李文波,孙乐,张大鲲。基于Labeled-LDA模型的文本分类新算法[J].计算机学报,2008(4):620-627.
[5]刘知远。基于文档主题结构的关键词抽取方法研究[D].北京:清华大学,2011.

随着网络技术的发展,网络信息越来越多,文本的数量也急剧增加,信息检索技术的出现满足了人们对需求信息的获取和使用。网络成为信息获取的来源和渠道之一,然而,从这些海量的文本中获取所需要的知识成为专家学者研究的热点。目前大多数的搜素引擎采用关键...
社会和时代的快速发展,使人类文明成果的积累和扩充也达到了空前的程度。在互联网e时代,由于网络技术的迅猛发展,信息检索与利用能力在现代人类社会生活中具有非常重要的作用、价值和力量。1信息检索与利用的重要意义在当今的信息爆炸时代,社会发展...