文献检索论文


0 引 言
目前,在互联网使用人群中,80%以上的人都在使用互联网搜索信息。然而传统信息检索系统都是使用关键字匹配的方式来进行查询,这种系统存在一些弊端,如“忠实表达”、“词汇孤岛”[1]等问题。比如在搜索引擎中查询“苹果”,出现的结果可能是苹果本身的真实信息,也可能是苹果品牌的某类产品或者与苹果相关的文章、书籍等内容,得到的结果可能并不是用户所需要的,这是因为系统中并不具备该字段的语义信息,搜索引擎在执行用户查询时,只是提取查询请求中的关键词,所以结果中出现了很多无关信息。因此以关键字检索文献资源的方式无法提供高质量的知识服务。
解决上述问题的关键在于为检索信息增加语义,既把语义Web 的知识引入到信息检索系统中来。2000 年 Tim Berners-Lee提出了语义Web[2]的概念。语义Web是一种能理解所需信息的智能化网络。要使检索系统语义化,很自然的需要引入本体(Ontology),在本体的基础上,文献检索系统在语义层上对文献资源进行查询和共享,从而提高信息的查准率及查全率。
1 构建领域本体
1.1 本体概述
本体概念最早产生于哲学。在计算机领域,本体并没有一个确切的定义。不同的人在不同的背景下对本体有不同的定义,比较有代表性的有:“本体是概念模型的明确规范说明”,这是Gruber给出的定义,这一定义在信息科学领域被广泛接受。后来Studer等对本体进行了更为深入的研究,认为“本体是概念化的明确的规范说明”[4],这个是目前最着名并被广泛引用的定义。Fensel对这个定义进一步分析,他认为本体的概念包括概念化、明确、形式化及共享四个方面。总结这些定义,可以看出本体构建的目标是捕获、描述和共同理解领域知识,并在形式化模式上明确定义词汇之间的相互关系,其核心是知识共享,实现不同主体在进行交流时准确无歧义。
1.2 本体构建方法
虽然本体得到了一定的应用,但是并没有一个被统一认可的方法体系,在不同的领域,本体构建的方法也各不相同。比较着名的有:生命周期法、骨架法、七步法等。可以根据各种方法体系的特点来选择其适用的领域。
1.3 构建领域本体
实现语义检索和推理的关键步骤是文献领域知识库的建立。本文在七步法的基础上,结合生命周期法及软件工程领域的原型法,依据构建领域本体的需要,提出一种简单的构建本体的方法,步骤如下:
第 1 步:确定本体的专业领域,就是图书名称和知识类型。
第2步:数据收集得到领域概念集合,抽取领域中的概念,构造概念类。
第3步:定义类与类之间的层次关系。确定概念的属性,构造属性类;确定属性和概念间的关系。
第4步:评估本体。
第5步:本体编码,本体构建完成。
该本体构建方法的流程如图1所示。
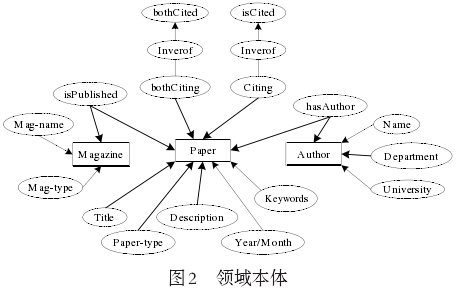
图2为建立的领域本体。文献信息中主要包含名称、作者、类型、出版时间、引用及被引用情况等,因此该本体构建了实体、实体关联、实体属性及关联属性。文献检索系统主要涉及Author(作者)、Paper (文献)和Magazine (期刊)三个概念实体,并通过其属性将这三个实体关联起来,同时定义了三个对象属性hasAuthor、isPublished和Citing,其中hasAuthor的定义域为Author类,值域为Paper类,它定义了文献与作者之间的关系;isPublished的定义域是Paper类,值域是Magazine类,它定义了期刊与文献之间的出版关系,Citing及isCited等属性的定义域是Paper类,值域也是Paper类,它定义了论文与论文之间的相互引用关系。通过检索,用户可以以查询到文献的一些相关信息,如作者、出版时间等。而通过文献的引用及被引用情况可以推理出同引和同被引。
2 文献领域语义检索的实现
2.1 基于本体的文献领域语义检索模型
图3为文献检索系统模型。该模型采用了基于浏览器/服务器 (B/S) 的三层结构,系统被分为表示层、业务层和数据层。系统提取用户输入的检索信息,依据得到的检索信息及系统定义的语义规则对文献领域本体进行语义推理,进而满足用户所的检索需求。
2.2 实验环境及工具
系统使用的开发工具为Java及Jena2.5,本体构建工具为protégé3.4,本体描述语言和规则语言为OWL+SWRL[5];Web服务器采用Tomcat6.0;实验环境为:主频为3.4 GHz的Intel酷睿i7 4770处理器、4G内存、1T硬盘,操作系统为Windows 7.
2.3 建立本体规则
基于本体的文献检索系统,是在语义层面的检索,其关键在于概念相互关系的推理,其目的是通过一种处理机制将隐含在显式定义及声明中所隐含的知识能够提取出来,即根据用户的检索要求进行相应的语义扩展,比如用户通过系统查询得到了文献的引用关系,进而推理出文献的同引及同被引文献。为了理解本体概念之间的语义,需要制定相应的规则,否则就和传统的检索系统一样,只能机械的进行关键字匹配。系统使用Jena作为推理机,在系统中构建规则,这种规则能够真实表达概念的相互关系,实现了检索系统的语义理解,从而满足用户的检索需求。
使用Jena作为推理机,OWL、SWRL及protégé作为建模工具创建规则。先定义语法规则,“→”表示蕴涵,用来关联前提和结论;变量名以“?”开头;符号“∧”用来连接引用的子公式;同时提供内置函数,用法与方法调用类似,其返回值为变量的值。
定义的规则如下:A(?x)∧B(?x) →C(?x)规则的语义如下:如果x是A的实例,同时也是B的实例,那么x也是C的实例。其部分推理规则如下:
第一条:如果a引用(Citing)了c,b也引用(Citing)了c, 且a和b的关系为不等同,则a和b之间存在“同引(bothCiting) 关系”.
第二条:如果a引用了b,a又引用了c,且b和c的关系为不等同,则b和c之间存在“被引(bothCited)关系”.规则代码如下
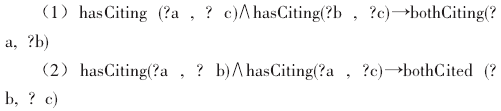
2.4 检索实例
当用户需要查询“当代作家”的相关信息,因为在本体体系中,“路遥”与“作家、陕西、文学家”之间是一种上下位的关系,所以当输入“陕西”、“作家”或者“文学家”这些关键词时,该系统会准确定位于“路遥”并对其作品信息进行显示。

总计有长篇小说3部,中篇小说集9部,短篇小说14部,诗歌10部。其他作品8部。在搜索结果中,不会显示与用户需求无关的信息,保证了检索结果的查准率与查全率。
3 实验结果及分析
查准率(Precision)和查全率(Recall)是衡量智能信息检索系统性能的两个重要指标。查准率是检索出的相关文献与检索出的全部文献的比例关系。查全率表示的是检索出的相关文献与系统中相关文献总量之间的比例关系。假设N为检索出的文献数, Ra为检索出的相关文献数, Rb为系统中相关文档数,则查准率和查全率的计算方法如下:
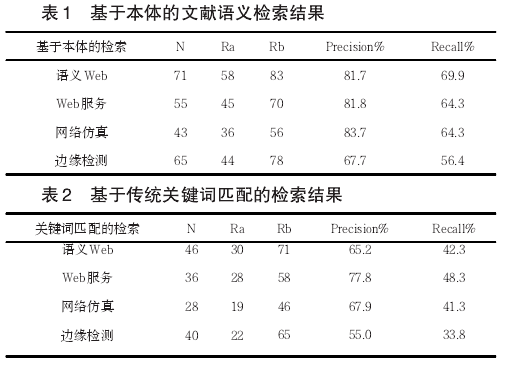
本文选取计算机领域的相关文献作为实验对象,在2010-2014年期间在计算机类期刊《计算机应用》、《计算机工程与应用》和《小型微型计算机系统》等上发表的论文中,根据不同领域,选取350篇文献构建本体库。对采用本体技术前后的检索性能进行比较, 得到的结果如表1、2所示。
实验结果分析表明,系统能够返回符合检索条件的文献资源,包括作者、出版时间、标题、文献编号、关键词、同引和被同引等信息。因为系统基于本体对检索关键词进行了语义的分析、扩展和推理,所以系统的查全率与查准率高于传统的基于关键词的检索系统,可见将本体技术应用到文献检索领域是可行的。
4 结束语
本文综合各种本体构建的方法,并根据文献信息的特点,提出了一个新的本体构建方法,创建了领域本体,建立了推理规则,构建了基于本体的文献检索系统模型。该模型可以根据用户需求,高效的查找出目标文献,提高了查全率和查准率。
最后通过实验,验证了基于本体的文献检索系统的优越性。
参考文献
[1] 袁 辉,李延香。 一种基于 Ontology 的文献领域语义检索机制的实现[J].自动化技术与应用,2013(05):16-18.
[2] T Berners-Lee, J Hendler, O Lassila.The Semantic Web. NewYork:Scientific American, 2001, 284(5):34-43.
[3] 胡世港。 语义 Web 与下一代互联网搜索引擎[J].软件导刊,2008(04):78-79.
[4] 黎 慧。 语义 Web 环境下的搜索引擎[J].桂林航天工业高等专科学校学报,2009(03):50-53.
[5] 曹利培,张志亮。 语义 Web 服务及其在搜索引擎上的应用[J].计算机与信息技术,2008(09):156-157.

1引言语义检索是信息检索的发展趋势,早在20世纪80年代,语义检索的思想就已经出现,并且信息检索领域已经开展了相关研究工作。企业级的语义搜索引擎近几年已经开始应用,例如Kosmix和等,特别等让搜索变得更智慧。百度框计算搜狗知立方代表了...

随着信息技术的飞速发展, 网络成为我们工作和生活中不可或缺的一部分, 网络化也对我们图书管理领域产生了巨大的影响。图书馆在经历了第一代、第二代、第三代的变迁后, 文献检索方式也由最原始的卡片检索、关键词检索过渡到现在的智能检索。...
引言专利作为技术创新的重要标志和体现,在很大程度上代表着一个国家或企业的技术水平和潜在的技术竞争力。专利文献检索在专利的申请、审查、管理和运用过程中具有重要作用。专利文献检索分为多种方式,包括关键词检索、语义检索等。为了提高查准率和查全率...
0引言专利作为技术创新的重要标志和体现,在很大程度上代表着一个国家或企业的技术水平和潜在的技术竞争力。专利文献检索在专利的申请、审查、管理和运用过程中具有重要作用。专利文献检索分为多种方式,包括关键词检索、语义检索等。为了提高查准率和查全...