搜索引擎论文

摘 要: 针对传统搜索引擎算法搜索内容需要占用大量人工劳动进行标记,反馈信息和用户搜索信息匹配度低,无法理解人类语言输入等缺点,文中结合自然语言算法对信息的整合过程及理解用户语言过程进行优化。通过建立语料库、提取文本特征信息和模型训练等方法,提出了适用于智能搜索引擎的新型检索算法。文中在CSI语料库、AWS爬虫数据等数据集中进行了测试,测试结果表明,该算法只需进行前期的人工干预和标记,便可以自行搜集专业信息并自行展开机器学习和训练,从而降低维护及使用成本。
关键词: 搜索引擎算法; 人工智能; 自然语言处理; 文本特征提取; 文本分类;
Abstract: There are faults in traditional search engine algorithms,such as taking up a lot of manual labor when searching content,low matching degree between feedback information and search information of users,disable in understanding human language input. So,the process of integrating information and the process of understanding the user language are optimized based on natural language algorithm. Through establishing corpus,extracting text feature information and model training,a new retrieval algorithm suitable for intelligent search engines is proposed. In this paper,the tests are carried out in data sets such as CSI corpus and AWS crawler data. The test results show that this algorithm can collect professional information and carry out machine learning and training by itself with only manual intervention and mark in the early stage,which greatly reduces the maintenance and use cost.
Keyword: search engine algorithm; artificial intelligence; natural language processing; text feature extraction; text classification;
0 、引言
搜索引擎是联系用户和数据库信息的重要桥梁[1]。当前各场景中的搜索引擎均面临着挑战,对于数据库中许多相近内容及相关项目,搜索引擎该如何理解用户需求,且准确找到有用信息,是目前亟待解决的难题。在庞杂的交互信息中,用户输入描述不精确的情况下,如何对模糊语义进行理解和解释,并找出数据库中关联度最大的内容,也是搜索引擎需要考虑的问题。近年来,对于搜索引擎算法的研究均是如何更好地组织文档或网页关键词的排列关系、从属关系,从而提升搜索效率[2,3,4,5];或是利用一些无监督的机器学习算法对搜索内容的相关程度进行排序[6];此外,是对人类语义进行研究,尝试利用语义信息进行关键词搜索[7]。
人工智能深度学习算法在计算机视觉、语音识别、自然语言处理和游戏对战等领域有着明显优势。而目前的搜索引擎算法存在维护成本高、信息检索不准确、无法理解人类的分类知识、无法分析用户输入的语义等一般算法无法高效解决的问题[8,9]。所以,利用深度学习算法的优势,从而解决搜索引擎在语义理解方面的问题是一个有效途径。
1、 搜索引擎算法
1.1、 算法原理
搜索引擎能发挥基础作用,基本由3个步骤构成[10,11]:(1)发现网络或数据库中的信息,搜集对信息的描述;(2)对信息进行提炼和分类,快速对信息进行组织,建立索引库;(3)搜索引擎的检索模块得到用户的信息描述,整理后在索引中搜寻相同描述或相近的信息,得到库中一系列信息与描述信息的相关性得分。最后,按照相关性返回给用户。具体算法如下:
(1)抓取网页技术。利用人工或半自动程序抓取数据库中的信息。每个成熟的搜索引擎均有自动抓取程序———爬虫(spider)。爬虫程序会利用网络中的超链接进行跳转,在每个网页中收集有效信息,分析内容并自动记录。

(2)处理网页内容。网页被抓取之后,不能直接处理复杂的网络页面。所以,需要预处理工作简化网页中的其他程序模块。例如,网页上的内容多数为文字和图片信息。对于文字信息先进行关键字的提取,判断哪些为可代表整个内容的文字。然后建立索引,记录到数据库中。对于图片要进行分析,判断其大致内容。预处理工作还包括去除重复内容、判断网页内容、网络内容的重要程度、访问量等。
(3)展示检索内容。当用户输入关键字时,要理解关键词并在索引中搜索相关信息,按照匹配程度和搜索网页的热度进行排序。此外,还会显示被索引网站的缩略图以供用户选择。
1.2、 搜索引擎算法
(1)目录式引擎算法。目录式搜索是先搜集信息,搜索信息的方式可以半自动化完成。然后,由引擎编辑人员将浏览后的信息编辑成摘要形式,将资料内容高度概括后存储为多个标签信息,由此标签就可将电子图书馆中的资料分成多个分类。当用户使用时输入某个关键词,搜索模块只需要将标签相同或相近的信息返回给用户,然后再由用户自行挑选。较多目录也可以由用户自行描述并上传,编辑人员采纳后可以应用于引擎的查找。此类引擎算法的人工标记过程利用了大量的人力物力进行总结和标记,虽总结信息准确、查询的质量高,但维护工作量较大。编辑需要的人工手段过多,在信息量剧增的时代背景下有着绝对的劣势。
(2)基于机器人的搜索引擎。搜索引擎寻找信息时利用爬虫算法以某种策略寻找网页,并摘取网页关键字等信息,建立索引。搜索引擎定期的寻找网络资源,其搜索面广、信息量大、更新迅速。但会返回无效信息,浪费空间资源,且信息筛选时间较长,因此用户体验感较差。
(3)元搜索引擎。元搜索是一种全局调用工具,在用户输入搜索内容时,根据内容调用合适的搜索引擎进行搜索,其通过一个友好的用户界面统一其他的引擎搜索内容。元搜索的覆盖面大、搜索效果好,但因其实质是调用其他独立的搜素引擎,所以调用不准时会有负面效果。
2、 基于人工智能的搜索引擎算法
2.1、 搜索引擎的缺陷
随着数据量的增长,大量系统中均需要搜索引擎来建立快速索引机制,电子图书的管理亦是如此。电子图书数据量大,容易对其进行归类,收集也相对简单,但搜索引擎仍有一些问题:(1)搜索的精细化程度较低。搜索多个条件时弹出的信息不够精确,搜索条件过于细化时无法搜索到相近意思的内容。(2)搜索时多个关键词的重要程度显然是不同的。搜索程序不能准确判断,搜索到的内容不是语义中的重要方面。(3)无法理解人类意图,只能按照人类数据寻找对应信息。例如,其无法在库中搜索到解决具体问题的专业知识,对非专业人员不适用。(4)无法搜索到某个词的相关联内容,例如书籍的作者、出版信息、专业门类等,此类信息必须用户进一步搜索才能得到。基于以上几点问题,人工智能算法在用户的语义理解和相关词条的关联方面均有着卓越的性能,可针对性的解决这些缺陷。
2.2、 自然语言处理的优势
自然语言处理是人工智能中的重要分支,其主要研究如何用智能、高效的方式对文本数据进行分析统计[12,13,14]。自然语言处理核心目的是令机器理解人类语义,懂得分清人类语言分布模式和人类意愿。
在用户进行搜索时,输入的内容中包含主要信息和描述性词语。若利用常规搜索算法,则搜出的信息将会尽量包含输入的词汇。但当输入较为复杂的语义时,传统算法无法正常的工作。例如,用户输入“在自然语言处理中的关键性技术”此类词条时,搜索列表中匹配度最高的会是“自然”、“自然语言处理”、“技术”等关键词汇,但用户显然想搜索的主要语义是“自然语言处理”和“关键技术”两者。而利用机器学习方法,算法会通过对现有词库的学习,分析出人类语言的分布规律,其会通过超参数的学习“记住”语言中“在”、“中”等语义。然后实现对一句话中信息的分割和评分,按照重要程度进行重排后进行搜索,其效率较高。机器学习算法能将上句话中的“自然语言处理”和“技术”同时反馈给查询接口,由此搜索出的内容将更贴近实际需求。
2.3 、自然语言处理算法
对搜索引擎缺陷的分析可知,传统搜索算法的问题在于语义理解。此方面,深度学习算法具有较大优势。以下介绍自然语言处理在实际中的训练和应用[15,16,17]。
2.3.1、 文本信息预处理
文本中的信息大多是冗余的,在人类语言中有大量指示事物状态或功能的词,或是对相同动作有着不同的描述方式。通常会通过4种方式进行文本预处理:
(1)去除噪声。语句中存在没有语义的词汇或标点,先将此类文本去除。建立1个噪声词典,在计算前对输入逐一比对,消除噪声。
(2)对词语进行规范。输入的多个单词是表示同一种意义,将此类衍生词更改为其本源的词汇是必要的。其为重要步骤,此步将原本的高维度特征转换为了低维特征,降低词汇的多样性,有利于机器学习中因多样性过高而无法收敛的问题。
(3)对象标准化。输入中会出现未在标准字库中出现的词语,无法被算法所识别,所以对判断会出现干扰。对象标准化就是将拼凑、缩略或编造的短语转为意义相同或相近的标准词汇。
(4)其他方法。例如单词拼写检查,语法检查等。
2.3.2 、文本特征提取
标准化后,文字信息需通过各种转化技术转为特征向量。根据不同用法,转换方式也不尽相同。在数字图书的检索方面,常用的是特征统计方法。
本文介绍的特征统计方法是词频-逆文档频率模型[16,17](Term Frequency-Inverse Document Frequency)。TF-IDF模型常用于文档检索、信息搜索等应用,此目的在于基于每种标准词汇在文档中出现的频率,将文档转换为数字表示的向量模型。
词频是指某个词在某篇文章中出现的频率,即某单词出现次数除以总词量。反文档频率是指噪声较多时,为防止误将关键词当作噪声去除而设计的识别方法。例如,某个词在文章中利用频次较高,被认为不足以描述整个文章的特征。所以,利用反文档频率来估计词的“独特性”。反文档频率算法是语料库文章总数除以包含某个词的文章数。得到向量后,就可用特征方式描述一篇文档。
2.3.3、 文本分类
文本分类是自然语言处理的经典问题之一,主要目的在于分类文档的用途、内容等。首先,文本在输入后其特征会被创建;然后,机器学习算法从这些特征学习一组参数;之后,使用学习到的机器学习模型对新文本做预测。文本分类较大程度上依赖于特征的质量与数量。当然,在使用任何机器学习训练模型时,通常引入越多的训练数据会得到更好的训练超参数。
3 数字图书搜索引擎的应用与测试
本文设计的数字图书搜索系统包括用户查询系统、语料库、数据库和本文提出的一种新的语义理解系统,其关系如图1所示。
图1 电子图书搜索系统
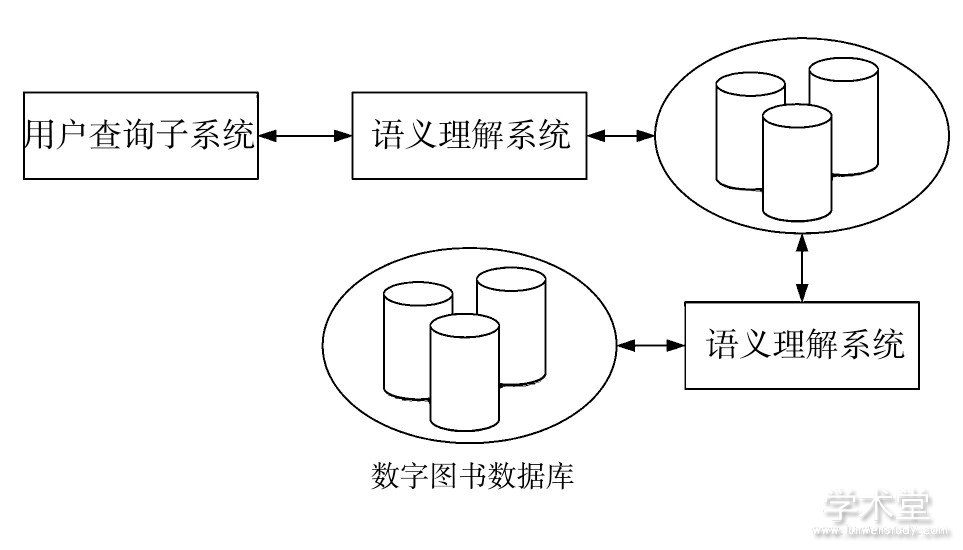
训练并建立人工智能搜索引擎的步骤大致如下:(1)利用智能搜索技术对数字图书数据库中的图像文字进行定期的搜索与分析;(2)接收信息后利用对文本信息的预处理方式去除其中无用链接和文字信息;(3)对每个文档做特征提取,建立语料库,收集关键词汇,收集时先以词频作为依据,或利用成熟的语料库作为先验再收集;(4)利用TF-IDF模型对文档进行特征的转换,得到每篇文档的数字特征信息,将其作为训练样本积累下来;(5)利用训练样本进行训练分类,得到关键词条的分类模型,分类依据应由专业人员检查、标注。训练模型稳定后,其可以利用模型对新的数字文档资料进行预测分类。建立索引库后,就基本建立起了一个有预测能力的搜索引擎。当用户发起搜索时,利用模型判断用户关键词,并与建立起的索引库进行对比,最后得到相关信息的罗列。
较传统的搜索引擎,利用人工智能算法可以降低人工标注难度且降低维护成本,实现自动获取并判断爬到的数字图书的类别。在用户输入时,可分析用户所需求的资料,从而提高用户的搜索质量。
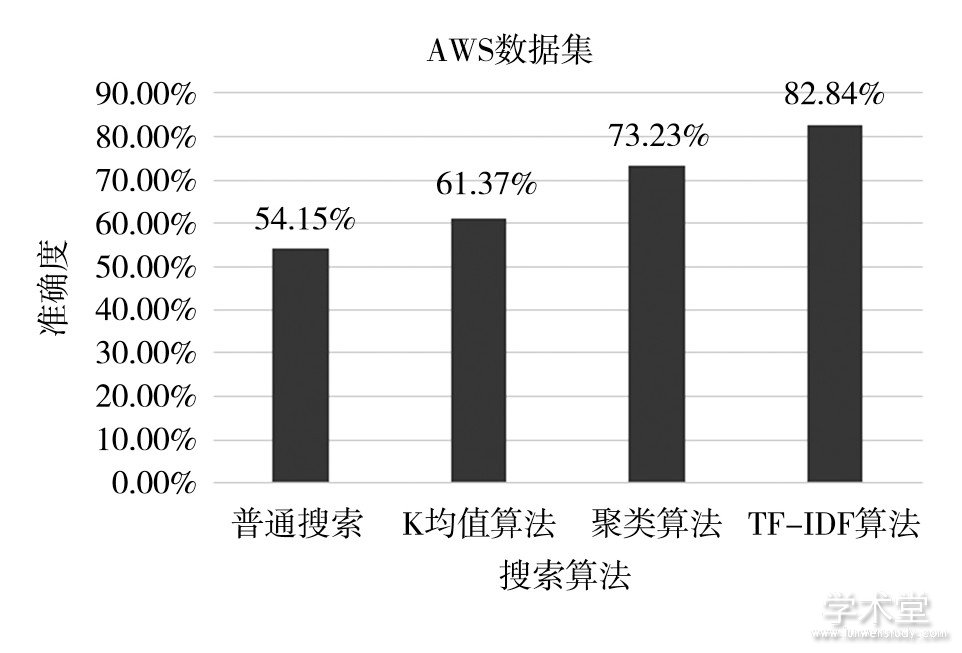
在实验中,利用已有的公开数据集CSI语料库和AWS爬虫数据,测试了普通搜索程序、聚类算法、K均值算法以及本文的TF-IDF算法的准确度和运行速度,准确度结果如图2-3所示。
图2 CSI数据集各算法平均准确度对比
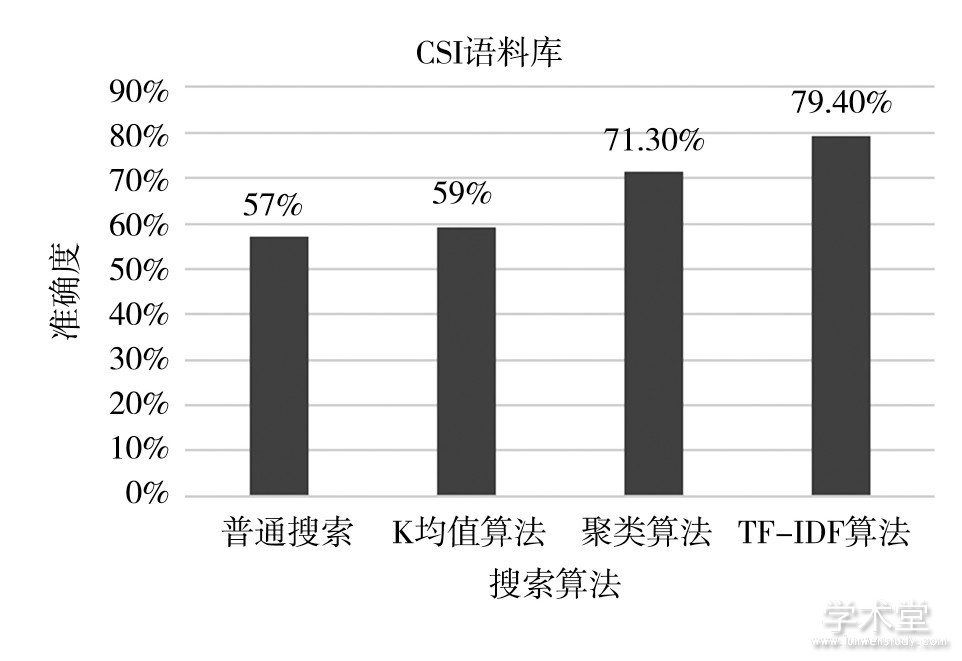
图3 AWS数据集各算法平均准确度对比
在两种数据库中各算法的运行速度如表1所示。
表1 运行速度对比
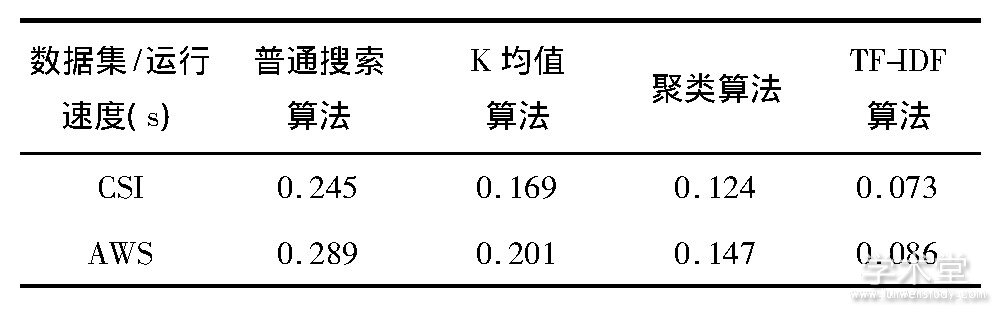
由普通搜索和TF-IDF搜索等算法对两种数据集的检索准确度和运行速度结果可看出,本文所设计的算法在准确度与运行速度方面相较于传统算法均有较大的提高。
为了进一步验证该系统的实用性和可靠性,除上述对已有的公开数据集进行测试外,将该搜索系统运用在某高校图书馆电子图书数据库中,进行检索结果测试。并与原有的搜索方式相比,对比结果如表2所示。
表2 两种搜索方法测试结果
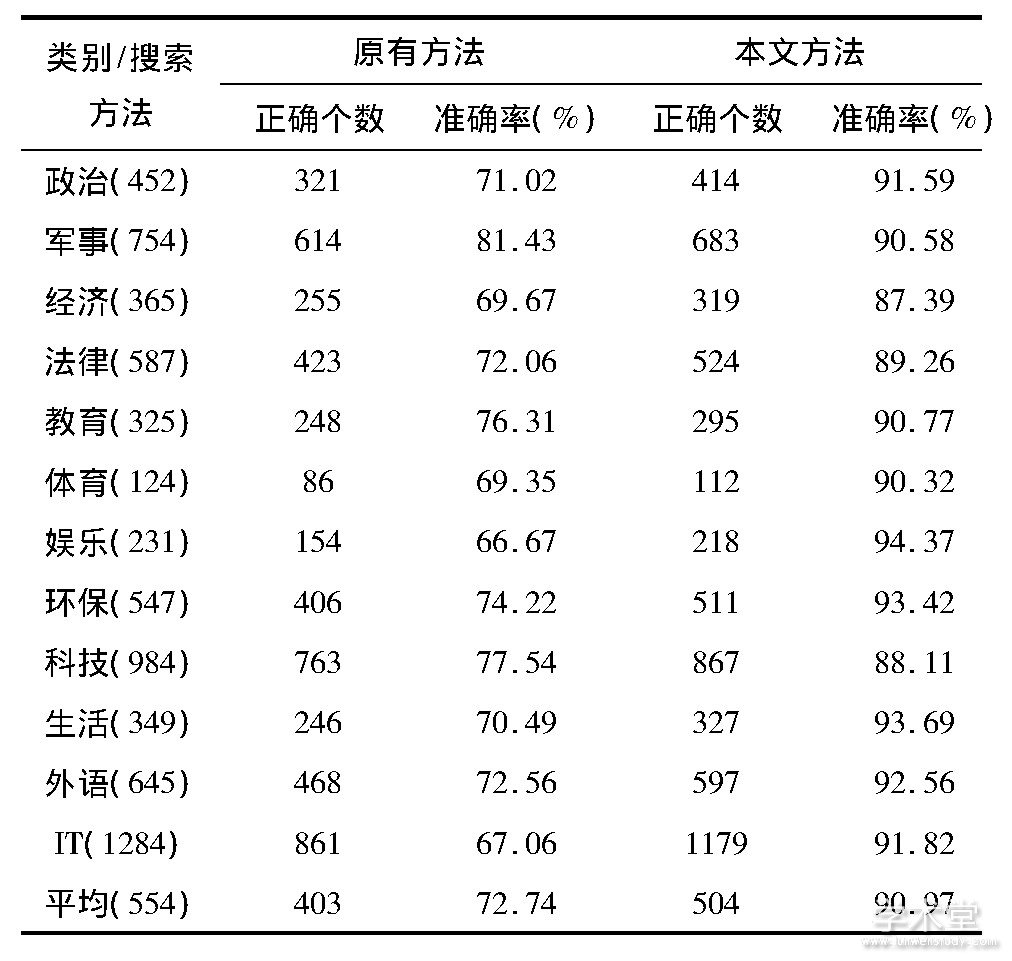
由结果可看出,利用本文所设计的人工智能搜索引擎通过关键词搜索所得到的结果准确率,在各种数字图书类别检索中均高于普通匹配搜索算法,在平均准确率方面可达到90.97%。虽该方法需要进行长时间训练,但算法理解能力和正确率均可达到当前先进水平,且能够充分满足数字图书的检索需要。
4、 结束语
本文讨论了将机器学习中的自然语言处理技术应用于数字图书馆的搜索引擎。针对数字图书搜索的具体情况,将自然语言处理中的特征提取算法和应用算法嫁接在搜索引擎上,可达到降低人工标注成本、给用户更好的搜索体验等目的。传统的搜索引擎算法已不能满足当前大数据的时代背景,本文提出的方法是未来专业搜索引擎研究的方向之一。然而,现如今的自然语言处理还存在一些弊端。例如,未达到能在和人类交谈的过程中了解人类需要的任务,无法在网络资源中自动搜索需要内容。因此,仍需要建立更加广泛的索引库和数据库以供快速搜索,这有待于进一步的深入研究。
参考文献
[1]姜韶增.互联网搜索引擎搜索策略和算法的研究[D].兰州:兰州交通大学,2015.
[2]马安进.个性化搜索引擎排序算法的研究[D].西安:西安理工大学,2016.
[3]胡存刚,程莹.基于粒子群算法的大数据智能搜索引擎的研究[J].计算机技术与发展,2015,25(12):14-17.
[4]黄剑,李明奇,郭文强.并行Fp-growth算法在搜索引擎中的应用[J].计算机科学,2015,42(S1):459-461,483.
[5]高庆芳.主题搜索引擎搜索策略的研究及算法设计[D].兰州:兰州大学,2017.
[6]白亮,于天元,刘湜,等.基于改进谱聚类方法的搜索引擎排序算法[J].计算机科学,2016,43(10):220-224.
[7]王倩,宋朝.基于用户兴趣模型的元搜索引擎算法研究[J].电子设计工程,2013,21(20):14-17.
[8]郑幸子.移动数字图书馆的图书分类系统设计[J].现代电子技术,2018,41(7):165-169.
[9]钟亮.用k-最近邻和贝叶斯分类预测图书用户喜好[J].信息技术,2016,40(9):62-65.
[10] 许嫣.浅析人肉搜索及其和传统搜索引擎异同[J].媒体时代,2015(6):101-103.
[11]韩倩倩.传统搜索引擎与语义搜索引擎检索服务比较研究———以雅虎和Kngine为例[J].信息通信,2015(4):115-116.
[12]王萌,俞士汶,朱学锋.自然语言处理技术及其教育应用[J].数学的实践与认识,2015,45(20):151-156.
[13]奚雪峰,周国栋.面向自然语言处理的深度学习研究[J].自动化学报,2016,42(10):1445-1465.
[14]孙茂松,周建设.从机器翻译历程看自然语言处理研究的发展策略[J].语言战略研究,2016,1(6):12-18.
[15]褚晓敏,朱巧明,周国栋.自然语言处理中的篇章主次关系研究[J].计算机学报,2017,40(4):842-860.
[16]马力,李沙沙.基于词向量的文本分类研究[J].计算机与数字工程,2019,47(2):26-29,48.
[17]朱晶晶,韩立新.基于RNN句子编码器的聊天机器人[J].计算机与现代化,2018(1):32-35.

Internet网络技术的快速发展,使网络已经成为了人们日常生活不可或缺的一部分,它作为信息发布、传播的主要方式,Web拥有几亿页面的分布式信息空间,目前仍然以130~200d翻一番的速度增加。Internet信息广泛,涵盖量很大,要从中迅速找出自己需要的信息...