搜索引擎论文

摘 要: 随着少数民族地区网民数量的不断增多,群众在网络上获取本民族文字信息的需求与日俱增,开发综合的少数民族文字网络搜索引擎势在必行,基于此,文章对少数民族文字(蒙古文、藏文、维吾尔文)网络搜索引擎的开发研究现状进行了调研分析。
关键词 : 少数民族文字;网络搜索引擎;
随着互联网的飞速发展,网民数量与日俱增,根据中国互联网络信息中心(CNNIC)《第45次中国互联网络发展状况统计报告》发布的数据,截至2020年3月,中国网民规模已达到9.04亿人,互联网普及率为64.5%。通过数据表明,实现互联网接入以来,中国在推进互联网全面普及的工作上取得显着成效,我国信息化发展的省间地区差异呈现稳定的下降趋势。
我国《宪法》第四条指出:“各民族都有使用和发展自己的语言文字的自由。”教育部国家语委发布的《国家中长期语言文字事业改革和发展规划纲要(2012—2020年)提出:加强各民族语言文字的科学研究和资源开发利用。加强语言资源数字化建设,推动语言资源共享,充分挖掘、合理利用语言资源的文化价值和经济价值。加强语言文字规范化工作。研制少数民族语言文字规范标准。加快制订社会应用和信息化急需的少数民族语言文字基础规范标准。做好少数民族语言的术语规范化工作。建设少数民族语言文字数据库。收集梳理少数民族语言文字的发展历史和文化信息,建设少数民族语言文化资源库和传统通用少数民族语言的大规模语料库。

近年来,我国已有蒙古文、藏文、维吾尔文、哈萨克文、柯尔克孜文、朝鲜文、规范彝文、傣文等10多种少数民族文字逐步收录于国际标准ISO/IEC 10646(《信息技术--通用多八位编码字符集(UCS)》)中,为我国少数民族文字信息化处理奠定了基础,也为少数民族文字网站的开发创造了条件。从少数民族文字网站的建设来看,我国传统通用少数民族文字多数已建有民族文字网站,并且逐年递增。据我们不完全统计,维吾尔文网站有近2 000个,蒙古文网站有1 000多个,藏文网站100多个;对民族自治区、自治州和自治县政府机关网站的民族文字版本建设情况调查显示:已有部分政府机关建有少数民族文字版本的网站,包括蒙古文26个、维吾尔文11个、藏文6个、朝鲜文10个、哈萨克文2个、柯尔克孜文2个、傣文2个。目前,民族文字网站拥有相当规模的用户群。以藏文为例,我们在西藏、青海、四川、甘肃、云南等地进行的藏族人民使用网络的抽样调查结果显示,300份调查问卷中有178人经常、有时或偶尔上网,其中有81人访问过藏文网站,占藏族网民的45.50%。
我国近年来的少数民族地区网民规模发展迅速,由政府、组织或个人建立的少数民族文字网站数量不断增多,形式多元化,且有一定规模的用户群。未来,少数民族文字网站的数量还将有更大的增长,信息量呈几何级的爆炸,少数民族群众在网络上获取本民族文字信息的需求也将与日俱增。如何从这些网站中快速检索出有效信息成了人们关注的焦点,网络搜索引擎在这种情况下应运而生,成为群众方便快捷地查找信息的工具。但目前国内外主流的搜索引擎多不支持少数民族文字网络信息的检索,因此开发一个检索结果准确、全面的少数民族文字网络搜索引擎对少数民族文字互联网资源的检索、采集,以及民族问题舆情发现和分析等方面的工作都有着重大意义。笔者调查了蒙古文、藏文、维吾尔文等少数民族文字网络搜索引擎的开发现状,以下分述之。
1 、蒙古文网络搜索引擎技术相关研究与开发
2010 年,内蒙古蒙科立公司发布了基于Indri开发的蒙古文搜索引擎;2019年,内蒙古自治区民族事务委员会发布上线“智路搜索”蒙古文搜索引擎,但相关技术仍有待完善。目前,蒙古文搜索引擎技术的相关研究开发主要在内蒙古大学等教学科研机构开展,主要研究有:如金威通过蒙古文的构词和语法等方面特点分析并确定了蒙古文停用词表,对蒙古文信息检索模型进行了探讨[1];李业荣根据传统蒙古文语言特点,利用信息检索技术设计了蒙古文搜索引擎原型系统[2];张畔对蒙古文搜索引擎基本方法进行了研究,主要研究了蒙古文网页信息采集和文档预处理、索引结构及索引构建[3];邢朝龙借助全文检索工具包Lucene,并在对开源搜索引擎系统Nutch进行二次开发的基础上实现运行于Hadoop分布式平台的蒙古文搜索引擎系统[4];巴雅尔赛汗在基于Page Rank算法研究的基础上提出了蒙古文搜索站点的建设方案[5];马路佳开发设计了蒙古文网页采集方案,采集的文档经过预处理后入库建立索引,通过跨语言词向量完成查询词源语言到目标语言的映射,最终形成蒙汉跨语言信息检索系统[6];温子潇等基于蒙古文的语言特点构建了一个可以同时检索传统蒙古文和西里尔蒙古文的信息检索系统[7]。
2 、藏文网络搜索引擎技术相关研究与开发
2015年,西藏大学研发了“阳光多文种搜索引擎”;2016年,海南藏族自治州藏文信息技术研究中心发布了“云藏”藏文搜索引擎,但相关技术仍需逐步改进。目前,藏文搜索引擎技术的相关研究开发主要在西北民族大学、青海民族大学、西藏大学等教学科研机构开展,主要研究有:如戴玉刚对藏文网页的采集系统进行研究,设计了藏文网页采集模块Tibet spider,并提出藏文网页的存储模式和通过创建URL树构造相似网页集合的方法[8],王思丽在其基础上对藏文网页的自动发现和采集,编码转换,网页判定与存储技术做了进一步研究,初步构造了藏文网页信息采集系统[9];江涛等以构建的藏文舆情分词词典为基础,讨论了藏文网络舆情话题发现与跟踪方法[10];高红梅等提出一种基于领域本体的面向主题的藏文信息爬取策略[11];龙从军等开发了藏语自然语言处理平台,实现藏文与拉丁转写互转、藏文文本拉萨音音标转换、藏文文本分词、藏文字性标注、分词标注一体化等功能[12];安见才让等探讨了基于Fisher 判别的特征提取方法,朴素贝叶斯分类方法,以及最大熵方法等关键技术,设计了藏文互联网信息舆情分析系统[13]。
3 、维吾尔文网络搜索引擎技术相关研究与开发
目前,维吾尔文搜索引擎技术的相关研究开发主要在新疆大学等教学科研机构开展,主要研究有:如吐尔地·托合提等深入研究维、哈、柯文网络信息检索现状和维、哈、柯文语言文字计算机处理方面的关键问题,介绍基于Web的维、哈、柯全文搜索引擎的设计和实现[14];吐尔洪·吾司曼等提出了维、哈、柯多文种搜索引擎中网页爬行器的结构及其设计方案[15];海丽且木·艾沙等研究了维、哈、柯多文种搜索引擎中web文本分类问题,采用基于改进的KNN的Web文本分类方法,并结合具体实验在对数据进行预处理的基础上实现了改进的KNN分类算法[16];麦迪乃·热合木江在研究了云计算的分布式Web文本检索技术的基础上,设计了Hadoop平台和Nutch系统相互结合的支持维吾尔文的文本检索系统[17];朱昊天在跨语本体重用构建维文本体框架的基础上,将本体集成与跨语本体转换相结合,设计了维文舆情本体构建系统[18];依不拉音·乌斯曼等研究了拉丁维文、西里尔维文和老维文之间的转换规则,提出Unicode字符编码体系和Unicode字符编码转换算法,实现在维语搜索引擎系统中通过拉丁维文和西里尔维文来直接检索老维文网页内容[19]。
4 、结束语
综上,我国少数民族文字网络搜索引擎的开发与研究工作已在不少教学科研机构开展,在近些年也取得了较好的成绩,但由于少数民族文字的信息处理方法和评价标准大多是从中文、英语等的处理方法中借鉴而来,对少数民族文字本身特点和规律的研究较为欠缺,并且少数民族文字语种繁多,编码不统一,分词困难等因素导致目前的少数民族文字网络搜索引擎的研究主要集中在系统实现方面,如网页采集与存储、文字编码与转换、文本分词等基础工作,已开发的系统大部分只是原型系统,不同系统之间兼容性差,可供采集的信息量不足,检索结果也未达到理想状态,针对如何实现理解用户行为,优化排序,权衡网络搜索引擎的“效率”和“效果”等搜索引擎技术的研究还比较薄弱,少数民族文字网络搜索引擎距离成为统一且稳定的多语种平台还有很长的路要走。
参考文献
[1]金威蒙古文信息检索模型的研究[D]呼和浩特:内蒙古大学,2009.
[2]李业荣蒙古文搜索引擎原型系统的研究与实现[D]呼和浩特:内蒙古大学,2013.
[3]张畔蒙古文搜索引擎基本方法的实现[D]呼和浩特内蒙古大学,2015.
[4]邢朝龙分布式蒙古文搜索引擎系统的研究与实现[D]呼和浩特内蒙古大学,2016.
[5]巴雅尔赛汗基于Page Rank算法的蒙古文搜索引擎设计[D].呼和浩特:内蒙古大学2018.
[6]马路佳蒙汉跨语言信息检索模型研究[D].北京中央民族大学,2018.
[7]温子潇,包飞龙高光来,等蒙古文信息检索系统的设计与实现[J]中文信息学报,2018,(7).
[8]戴玉刚藏文网页采集技术研究[A]民族语言文字信息技术研究
第十一届全国民族语言文字信息学术研讨会论文集[C].2007.
[9]王思丽藏文网页自动发现与采集技术研究[D]兰州:西北民族大学,2010.
[10]江涛,于洪志,李刚基于藏文网页的网络舆情监控系统研究[A].全国计算机安全学术交流会论文集[C].2008.
[11]高红梅,仁青诺布,普次仁领域本体的藏文主题爬虫搜索策略研究[J].计算机应用与软件,2015,(9).
[12]龙从军藏语自然语言处理平台([EB/0:Tt:t/tibetan.vurl cn/ .2016-04-15.
[13]安见才让拉毛措,孙琦龙互联网藏文信息舆情分析系统设计[J]微处理机,2017,(2).
[14]吐尔地托合提维尼拉木沙江,艾斯卡尔艾木都拉维、哈、柯多文种全文搜索弓擎的设计与实现[J]计算机应用与软件,2009,(6).
[15]吐尔洪吾司曼维尼拉:木沙江维、哈、柯多文种搜索引擎中网页爬行器(Crawler)的设计与实现[J]新疆大学学报(自然科学版).2009.(1).
[16]海丽且木艾沙,维尼拉木沙江维、哈、柯多文种搜索引擎中web文本分类的研究[J]新疆大学学报(自然科学版),.2011,(8).
[17]麦迪乃热合木江基于Hadoop的分布式Web文本检索系统的研究与开发[D].乌鲁木齐:新疆大学2013
[18]天基于跨语本体转换的维吾尔文舆情本体构建研究[D]乌鲁木齐新疆大学,2015.
[19]依不拉育乌斯是王悦面向维吾尔跨文字搜索引擎的统-转换机制设计[J].计算机科学 ,2016,(S2).
首先Web信息检索挖掘技术做了简要概念,其次对基于Web挖掘的网络搜索引擎技术的应用进行了分析,提出了一种给予Web挖掘的个性化搜索引擎,并对各系统模块的功能及实现方式进行研究,分析结果表明,此种系统具有很强的检索灵活性,而且还能实现个性化查询结果...

0引言随着互联网技术的飞速发展,互联网中的信息量也越来越大,如何更加有效地利用这些信息资源,已经越来越受到人们的关注。互联网中存在的信息来源十分广泛,与此同时,存在的形式也是多种多样,包括图像、文本、视频、音频等不同的形式,面对着不同来源...
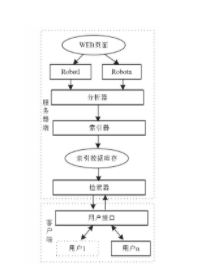
搜索引擎是一种利用网络自动搜索技术,对网络各种资源进行标引,并为检索者提供检索的工具。其工作原理主要包括以下几个过程:信息的采集和存储;信息索引的建立;检索界面的建立;检索结果的相关处理[1].好的搜索引擎不仅能提供好的检索界面,而且还能提...
当今社会计算机技术迅猛发展,信息资源越发丰富,网络信息受众量庞大。根据中国互联网信息中心CNNIC发布第34次调查报告最新数据显示,截止到2014年6月我国网民数目达到6.32亿。对于众多网民来说,搜索引擎是从海量网络数据中获取信息的最有效工具,...