0引言
新浪微博是一个由新浪网推出, 提供微型博客服务的类 Twitter 网站。 用户可以通过网页、WAP 页面、手机客户端、手机短信、彩信发布消息或上传图片。 新浪可以把微博理解为“微型博客”或者“一句话博客”。 用户可以将看到的、听到的、想到的事情写成一句话,或发一张图片,通过电脑或者手机随时随地分享给朋友,一起分享、讨论;还可以关注朋友,即时看到朋友们发布的信息。
由于新浪微博的低门槛和社交的便利性, 目前它拥有的用户群体和微博数量急剧增加。 如何能够快速精确地找到用户所感兴趣的或可能感兴趣的内容是本文主要的关注点。 目前与这个问题比较类似的问题是网页搜索, 因为网页搜索同样基于关键词找到用户最需要的网页。 目前较成熟的是 Google 提出的 PageRank算法,它根据网页与关键词的相关性和被引用程度对网页进行排序,从而预测用户比较感兴趣的页面。 但是微博与网页之间还是存在着一些差别, 例如文本长度、文本引用关系、社交性等。
本文提出了一种新浪微博的搜索排序方法。 该方法首先通过对微博分析提取出可能影响因素, 然后使用神经网络模型和初始化参数对于微博进行评分排序, 最后使用网页日志修正模型参数不断提高模型的准确性。
1相关知识
1.1 搜索引擎
搜索引擎, 通常指的是收集了互联网上的网页并对网页中的每一个文字(即关键词)进行索引,建立索引数据库的全文搜索引擎。 用户输入要查询的关键词,搜索引擎则把所有与该关键词相关的网页按照与关键词相关性的高低排序后提供给用户作为搜索结果。 搜索引擎的原理包括以下三步:
(1)从互联网上抓取网页:利用爬虫程序自动访问互联网上的网页, 并沿着任何网页中的所有链接爬到其他网页,以从互联网上自动收集网页。
(2)建立索引数据库:分析收集回来的网页 ,提取相关网页信息, 计算每一个网页针对页面文字中的相关度,再基于这些相关信息建立网页索引数据库。
(3)在索引数据库中搜索排序:当用户开始搜索关键词时, 由搜索系统程序从网页索引数据库中找到符合该关键词的所有相关网页。 相关度越高, 排名越靠前。 关于搜索引擎的一些近期发展可参见文献[2]。
1.2 Lucene
Lucene 是 apache 软件基金会 Jakarta 项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎, 而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎、部分文本分析引擎(英文与德文两种西方语言)。 Lucene作为一个全文检索引擎,具有如下突出的优点:①索引文件格式独立于应用平台; ②与传统全文检索引擎相比,提高了索引速度、实现分块索引,为新的文件建立小文件索引; ③优秀的面向对象的系统架构; ④索引器通过接受 Token 流完成索引文件的创立, 文本分析接口与语言和文件格式无关。 Lucene 的详细使用方法可参见文献[5]。
1.3 人工神经网络
神经网络是人工智能的一种常用方法。 目前人工智能广泛应用于各个领域,通过模拟生物功能已是人们解决实际问题的一种有效方法。 人工神经网络就是由模仿生物神经网络而来,其中应用比较多是 BP神经网络,BP 神经网络是一种具有三层或三层以上的多层神经元网络。 BP 网络按有教师学习方式进行训练,当一对学习模式提供给网络后,其神经元的激活值将从输入层经各中间层向输出层传播, 在输出层的各神经元输出对应于输入模式的网络响应。 接下来,根据的原则为减少希望输出与实际输出误差, 从输出层经各中间层、 最后再回到输入层, 并且逐层修正各连接权。 正因为这种修正过程是由输出到输入逐层进行的,所以它被称为“误差逆传播算法”。 当这种误差逆传播训练不断进行时, 网络对输入模式响应的正确率也会不断地得到提升。 BP 网络的具体步骤可参见文献[4]。
2搜索排序架构与实现
本节将详细介绍我们排序服务的流程以及模块组成,同时对每一个模块给出其功能以及简要的描述,主要目的是为了提供一个整体的框架的描述。
2.1 整体框架
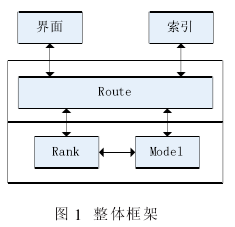
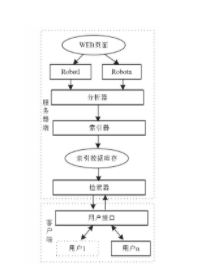
整个排序服务以 Webservice 的形式提供服务,服务的框架包括两层,即路由层和控制层,路由层负责与前端界面和后台索引建立数据连接和传输, 控制层完成微博的排序逻辑以及排序模型的递增训练。 图 1 是整体框架的示意图。
2.2 路由层
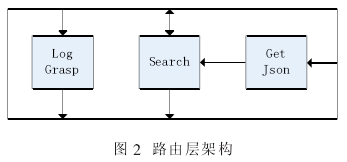
如图 2 所示,路由层包括三个小模块:Search、Log-Grasp、GetJson。 它们共同完成了数据在前端界面排序服务以及后台索引之间的传输。
●Search 模块: 该模块主要负责从页面端接收搜索关键字,并将搜索关键字通过 GetJson 模块传输给后台索引。经过后台索引的处理,将返回给 Search 模块相应的微博。 接着,Search 模块将从索引端获得的微博传递给控制层的排序模块处理, 从而获得排序结果前 20的微博。 最后该模块将 20 条微博返回给前端界面。
●LogGrasp 模块: 该模块负责从前端界面获取用户的点击日志,并将日志传递给控制层的 Model 模块,以便该模块通过日志对模型进行改进。
●GetJson 模块:用于获得后台索引端返回的相应关键字的微博列表。
2.3 控制层
控制层用于实现微博的排序逻辑 , 包括排序(Rank)和模型(Model)两个子模块。
(1)排序模块
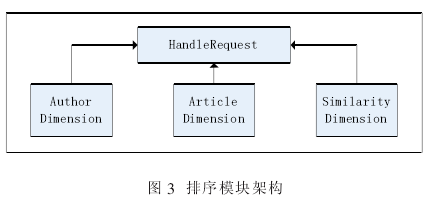
排序模块(如图 3)负责具体实现微博排序的逻辑。
HandleRequest 模块将从路由层的微博参数解析,过滤掉无关的脏数据(例如来自 iPhone、来自 iPad 等),并将参数传递给负责排序模型各维度处理的模块, 排序模型的维度模块包括作者相关属性模块(AuthorDimen-sion)、微博相关属性模块(ArticleDimension),以及相关性维度模块(SimilarityDimension)。 这些模块计算出相应维度的权重作为模型的输入,以便进行排序。
●作者相关属性模块(AuthorDimension),负责统计计算与微博作者相关的属性维度的权重, 包括作者的粉丝数、关注数,以及作者是否为 V 用户等。
●微博相关属性模块(ArticleDimension),负责统计计算与微博相关的属性维度的权重, 包括微博的评论数、转发数等。
●相关性维度模块(SimilarityDimension),负责统计计算微博内容与关键字的相关性维度的权重。 在该模块中我们基于第三方开放源代码的全文检索引擎工具包 Lucene 以及 IKAnalyzer 分析工具重构了微博索引,并修改了相关性公式。 在原来的计算公式中微博内容越短微博的相关性越高, 我们认为这在实际使用的是欠合理的, 因此我们修改公式使内容较长的微博的相关性权重有所提高。 此外我们还通过修改索引建立的规则, 增加了多关键查询的功能, 在改进后效果提升。
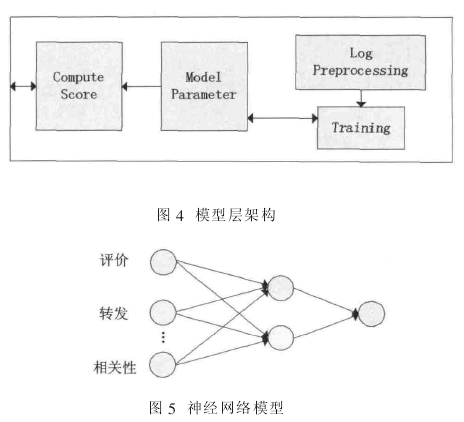
(2)模型层
模型层(如图 4)是微博排序的模型实现,负责从排序模块获得微博参数,通过模型计算出结果。 此外,我们在模型层还增加了模型的优化模块, 通过对用户点击日志的解析,重新训练模型,进而获得更好的排序结果。
在该模块中使用的排序模型为神经网络模型,以排序模块中各维度获得的权重为输入建立模型, 学习率设定为 0.9, 产生的输出即为该微博的排序得分,将其返回排序模块排序即可获得排序结果。
日志处理模块(LogPreprocessing)负责统计处理路由层获得的日志数据,作为训练模型的 test data,将预处理的日志结果传递给模型训练模块(Training),由该模块训练排序模型, 以便根据用户点击结果实时更新模型参数。 考虑到新浪微博只允许同一账号在一个小时内抓取 150 条左右的微博,我们设计了一个定时器,在每天晚上 24 点从前端界面获取点击日志,然后每一个小时处理 150 条微博改进排序模型。
3实验结果
3.1 文本长度
我们使用关键词“药监局”做搜索,图 6 左右两侧给出了使用原始算法和经过改进的搜索结果的比较。从图中我们可以清晰地看到改进的算法降低了短文本的相关性,使得一些更长更相关的较长文本排在前面。

3.2 多关键词
我们使用两个关键词“北京”和“玉渊潭”做搜索,图 7 左右两侧给出了使用原始算法和经过改进的搜索结果的比较。 从图中我们可以清晰的看到改进的算法考虑了多个关键词, 使得匹配更多地关键词的微博排在前面。
3.3 噪音数据
我们使用关键词“iPad”做搜索,图 8 左右两侧给出了使用原始算法和经过改进的搜索结果的比较。 从图中我们可以清晰地看到改进的算法过滤了一些噪音数据,使得搜索结果更准确。
4结语
本文介绍了一种基于 BP 神经网络的新浪微博搜索排序方法,主要工作有:
●提取可能影响排序结果的微博特征, 例如关键词与微博内容的相似度,博主信息等,同时对于这些特征做了预处理。
●通过网络点击日志训练预测模型。
●通过分析实验结果,改进算法,例如考虑文本长度,多关键词搜索等。
下面是目前我们方法中的一些不足和改进方法:
●目前网络日志的数据比较少, 且数据有效性并不能保证,因此我们训练出的模型还不够准确。 这点的解决方案是增加搜索引擎的用户数量和点击数量,同时保证用户不能够随意点击。
●我们方法中的一些改进技术需要重新对搜索结果做索引,这样可能会降低搜索和排序的速度。
●从最后的统计结果看, 我们的排序结果在前三条的点击率都很高,但会在 10 或 11 条有一点突起。 这个的主要原因是我们的排序结果中是所有搜索结果与关键词的相关性都比较高, 用户愿意点击的微博存在一定的随机性。
参考文献:
[1]新浪微博. 百度百科.
[2]罗武,方选,朱兴辉 .网络搜索引擎排序算法研究进展. 湖南农业科学,2010,7:137~140
[3]S. K. Ganta,S. P. Somayajula. Search Engine Optimization Through Spanning Forest Generation Algorithm. International Journal onCormputer Science and Engineering,2011,3:3276~3282
[4]J. Han,M. Kamber. Data Mining. China Machine Press, 2006
[5]M. Mohd. Development of Search Engines Using Lucene: An Experience. Procedia Social and Behavioral Sciences,2011,18:282 ~286
[6]X. Zeng, T. Song, X. Zhang, L. Pan. Performing Four Arithmetic Operations with Spiking Neural P Systems, IEEE Transaction onNanoBioscience,2012,11(4):366~374
[7]L. Pan, X. Zeng, Small Universal Spiking Neural P Systems Working in Exhaustive Mode. IEEE Transaction on NanoBioscience,2011,10(2):99~105
[8]M. P. Selvan, A .C. S., A. P. Dharshin. Survey on Web Page Ranking Algorithms. International Journal of Computer Applications,2012,41:1~7
[9]D. K. Sharma,A. K. Sharma. A Comparative Analysis of Web Page Ranking Algorithms. International Journal on Computer Science andEngineering, 2010,2:2670~2676
[10]曾湘祥. 膜优化算法在 DNA 编码中的应用研究[D]. 武汉: 华中科技大学, 2007
[11]X. Zhang, X. Zeng, L. Pan, On Languages Generated by Asynchronous Spiking Neural P Systems, Theoretical Computer Science,2009,410(26):2478~2488