搜索引擎论文


互联网最基础的功能即提供信息。像谷歌、百度这类通用搜索引擎重点在于广度搜索,搜索到的内容涵盖范围过于广泛、繁杂,用户难以从如此海量的信息中快速获取自己所需的确切信息。尤其针对用户的专业检索需求时问题更为突出,难以满足专业人士的检索需求。因此, 应开发搜索质量更准确、相关性更复杂的搜索引擎,以追求在某一学科或某一行业领域有最佳的检索效率及效果,垂直搜索引擎的应运而生, 成为搜索引擎发展史上的一座里程碑。因此,垂直搜索引擎以其搜索结果的高效性、准确性和专业性等特点逐渐得到人们的青睐。
1、 研究意义
信息时代的到来与中国经济的高速发展,导致互联网中企业信息数据量日趋加大,分散的企业信息使得通用搜索引擎非结构化数据搜索导致的数据准确性问题日渐突出。因此,针对企业领域的信息查找的准确性和专业性,可以对企业搜索服务模式的细分,对海量企业信息科学地整合与管理,为用户提供精准和具有针对性的企业搜索服务的搜索引擎系统,已成为当今中国企业发展的迫切需要。
2、 企业名录垂直系统核心技术
2.1 信息采集技术
2.1.1 网络爬虫技术
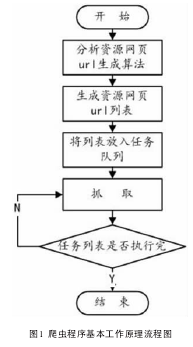
本文所述系统是基于垂直搜索的系统,所需要的海量企业信息分散于互联网中,因此,需要特定的程序从网络上搜寻与抓取需要的数据。在互联网上抓取网络资源的过程是依靠一个应用程序实现的,这个应用程序叫做网络爬虫(Spider),或者叫网络蜘蛛(Spider),其主要职责即从信息源处抓取所需资源信息。爬虫程序主要工作原理如下:
分析所需要信息的网页url地址生成算法,生成初始的url地址;依据初始url地址依次生成有效的url地址,形成地址列表;建立网络连接,从生成的url地址列表中依次提取url地址,放入任务队列,调用爬虫程序依次通过url入口进行网页抓取任务。爬虫程序工作原理流程图如图1所示。基于信息数据库的准确性与完整性考虑,本系统设计的爬虫程序同时包含有以下几种功能。
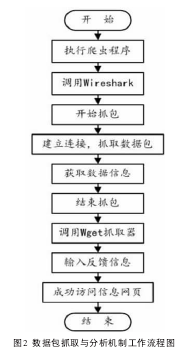
①数据包抓取与分析机制
多数网站为保证网站的稳定性与安全性,采取了隐式传参的方式,例如使用验证码等。因此本系统在调用爬虫程序抓取某些所需信息时,需要通过调用数据包分析软件、查看访问网站所需传输的参数内容。本系统调用的是Wireshark网络数据包分析软件,其功能是截取网络数据包,并尽可能详细的显示网络数据包数据,可用于分析访问网站中的隐式传参。通过抓取数据包,获取需要反馈网站的数据信息,之后将隐式信息反馈网站后使系统获取访问网站权限,成功访问网页,之后通过子程序调用抓取器来进行网页的抓取。本文所述系统中所使用的抓取器为Wget,支持TCP/IP协议,并可使用HTTP代理。Wget抓取器的使用非常简单,通过设置简单的参数,将页面按照要求完整地从互联网下载到本地。因此,该机制实现的工作流程图如图2所示。
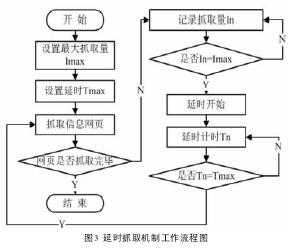
②延时抓取机制
网站基于通常设置一系列防范措施来保护网站安全,例如当某些用户在一定时间内大量访问网站时,网站防护程序可能认为这是恶意访问,从而屏蔽此用户IP。当系统调用爬虫程序抓取信息时,不可避免地在短时间内大量访问目的网站,因此需要进行一定量的延时机制来防止服务器IP被屏蔽。本系统设计的延时抓取机制基本原理为:首先设置一定的信息数量Imax作为启动延时抓取的条件,同时设置延缓时间Tmax;之后,记录抓取信息数据量In,即任务列表中已抓取的信息数量,当信息抓取量达到该条件后,即Imax=In时,标记当前最后一次抓取的url地址,爬虫程序暂时停止,Clock开始计时,同时信息抓取量In归零;最后,当Clock时长达到预定的延缓时长后,Clock时间归零,调用爬虫程序,此时进入任务队列的url地址为地址列表中顺序排在被标记的地址后的下一条url地址,之后取消被标记url地址的标记,信息抓取量In再次从零开始计数,直到达到规定条件后再次开始延时,直至任务列表中所有抓取任务都已完成。其工作流程图如图3所示。
2.1.2 信息抽取技术
信息抽取是指从一段文本中抽取指定的一类信息,并将其转化为结构化的数据存入一个数据库中供用户查询使用的过程。因此如何将采集到的信息进行结构化的抽取是垂直搜索关键技术之一。一个html文本中通常包含有多类信息,例如企业名称、企业类型、注册号等,如何将这些信息结构化抽取、归类与整理也是信息抽取待解决问题之一。本系统采用的方法非常简单:利用已预定义的字符匹配算法———正则表达式(Regular Expression)来扫描html文本,进行信息匹配,提取正确匹配的信息。Html网页一般某类特定信息的句子带有特殊的句法。因此依照正则表达式的的基本字符匹配规则,可以确定某类特定信息提取的正则表达式,从而实现自动分类,提取对应信息。
2.2 检索技术
2.2.1 中文分词技术
中文分词技术是基于中文信息的搜索引擎的关键技术之一,是处理中文信息的基础,其准确性影响着查询结果的准确性。中文信息以字为单位,单个汉字按照一定顺序排列组合后合成词句进行有意义的表达。因此,如何将用户进行搜索的模糊信息分词处理后获得最接近用户原意的结果,是分词技术的难点。本系统实现分词技术采用的是Friso分词处理器。Friso是使用c语言开发的一个开源的中文分词器,完全基于模块化设计和实现,可以很方便的植入到其他程序中,如:MySQL,PHP等。Friso分词器源码可直接植入到任何平台编译使用,支持UTF-8编码、自定义的词汇数据库以及大小写等,可对中文与英文的混合词汇进行分词处理等,在系统中使用方便快捷。
2.2.2 索引技术
索引技术是垂直搜索技术中关键的一环。索引的建立,可以有效提高结构化信息的入库效率与信息查询的精准性。目前常用的基于中文分词索引建立方法有单字分词,双字分词(统计分词)和词典分词。单字分词即以单个汉字为单位建立索引项,此法索引建立简单,但查询时操作繁复,效率不高;双字分词法以两个汉字作为一个词来建立索引项,索引建立复杂且会存在大量冗余,查询效率相对单字分词法而言较高;词典分词法则是需要在分词前建立一个详细全面的词库,在切分中文信息时与词库中的数据进行匹配,遇到匹配的词汇时进行信息切分。经过综合对比,本系统选择词典分词建立分词索引,因此需要建立例如“合资”、“股份制”等与企业、行业、商业相关的专业词语的词汇数据库,选择基于词库分词法的中文分词技术以提高查询结果的准确性与相关性。
3、 企业名录垂直搜索系统的设计
3.1 数据库模块
3.1.1 企业信息相关词词库
为提高本系统搜索结果的精准性,本系统建立的自定义的企业信息词库。在构建企业相关特征词库时,首先需要确定描述企业的术语有哪些,例如描述企业类型的术语按照组织形式的不同被描述为国有、私营、合资、独资等,按照企业所属行业又可以分为交通运输、工业、农业等。因此,在建立词库时,首先需要确定初始的企业相关词,按照字符长度进行排列;之后,确定这些字符的汉语拼音。在建立数据表时,建立的数据项包括字的ID、汉语拼音、词语长度、词语汉字等数据项,当Friso分词器接受到用户的搜索时,可以依照所输入的汉语词汇或者英文输入法下的汉语拼音进行相对应汉语分词提示。
3.1.2 企业信息数据库
本文研究的企业名录垂直搜索系统,为实现准确的企业信息搜索,建立了详细的企业信息数据库,包含了企业名称、注册号、法人姓名、法人信息、企业地址、电子邮箱、联系电话等详细信息。并且为实现精准的企业垂直搜索,本系统对企业类型、注册资本、规模大小、所在地区、营业状况等分别进行较为详细的分类并建立相关索引,例如根据注册资本范围可以建立50万以下、50~100万、100~300万、300~500万和500万以上等几个数据的索引表,当用户选择相应的注册资本范围进行更快捷的查询,提高结果的精准性与搜索效率。
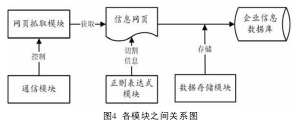
3.2 信息采集与处理模块
系统设计的爬虫程序由于需要调用Wireshark数据分析包与Wget抓取器,因此该模块又分为四个模块:网页抓取模块、数据库存储模块、通信模块与正则表达式处理模块,如图4所示。网页抓取模块即将包含有所需信息的网页从网络下载至本地;数据库存储模块即将切割后的结构化信息存储至企业信息数据库中;通信模块则负责父进程与子进程之间的通信,即爬虫程序中调用Wireshark子进程与调用Wget抓取网页子进程以及延时抓取中延时进程之间的通信,使得各尽程各司其职,互相协作,完成指令;正则表达式处理模块则是利用标准的正则表达式规则对抓取的网页进行信息的匹配,进行结构化信息的抽取。
3.3 垂直搜索与查询模块
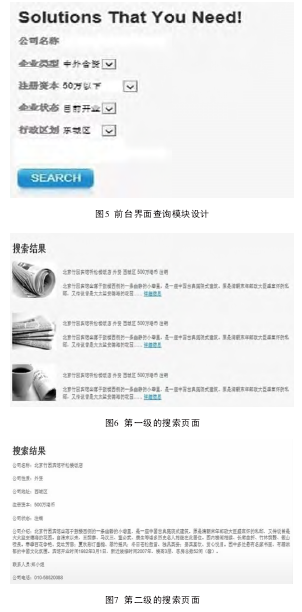
系统前台查询不仅使用了中文分词技术,调用Friso分词器可使用户在查询时可对相应的查询条件进行提示,同时支持联合检索。在前台搜索中,系统不仅设计了基于用户输入关键字词的搜索,还对注册资本范围、企业类型、企业状态、行政区划等条件进行了选择设置,用户可以直接选择所查询企业的注册资本范围、所属行业等,后台程序可将前台界面反馈后的多个查询条件进行联合查询,确保反馈给用户最需要的企业信息,如图5所示。搜索结果的展示是一个二级页面:第一级结果显示页是根据用户的需求显示出所有符合条件的企业,为用户提供选择范围,如图6所示;若用户需要了解自己感兴趣企业的详细信息,可直接点击链接进入第二级结果显示页,可显示该企业包括详细地址、公司简介等详细信息,如图7所示。
4、 结语
本文描述的基于企业名录的垂直搜索系统采集的企业信息包括企业工商注册号,其来源于各地工商信息系统,确保了数据来源的可靠性,不仅可以为用户提供正规精准的企业信息,还可以有效辨识企业的真伪;而且本系统利用垂直搜索引擎实现了联合搜索功能,用户可以根据自己所需输入企业筛选条件,例如所查找企业的所在地区、公司性质、注册资本等条件来进行搜索,提高搜索效率;本系统可以依据用户条件进行相应的企业搜索,可对用户提供相关行业中企业的信息,有助于企业用户选择所需的商业合作伙伴等,形成有效的商业产业链,促进企业之间的合作与发展,从而促进商业发展。
参考文献:
[1] 王文钧,李巍.垂直搜索引擎的现状与发展探究[J].情报科学,2010,(3).
[2] 张博,蔡皖东.面向主题的网络蜘蛛技术研究与系统实现[J].微电子学与计算机,2009,(5).
[3] 林海霞,原福永,陈金森.一种改进的主题网络蜘蛛搜索算法[J].计算机工程与应用,2008,(2).
[4] 周纯.垂直搜索引擎技术进展[J].知识经济,2011,(9).
[5] 季春,姜琴,吴铮悦.垂直搜索引擎关键技术研究综述[J].情报科学,2012,(10).

本文从卷烟企业对信息数据检索的需求出发,论述了基于Solr开发出符合自身企业的搜索引擎的可行性,介绍了有关搜索引擎及Solr的相关知识。...

1、引言近年来,随着数字化教育浪潮的不断推进,我国在教育资源建设方面已经取得了巨大的成就,各类教育资源的数量巨大且呈现几何级数增长。随着搜索引擎技术的发展,通用搜索引擎的功能变得日益强大,取得了很大的成功,但其仍有局限性,如搜索的深度不够,...

搜索引擎经历近30年的发展,目前在使用的有几种类型,如全文搜索引擎、分类目录搜索引擎、多元搜索引擎、集成搜索引擎等。但这些都是网络上的公用商业搜索引擎,它们往往不能满足企业的需要。...
网络爬虫作为搜索引擎技术的核心技术,是按一定遍历策略,以网页之间的链接为路径,抓取网页必要信息,并将其下载到本地存储设备上,以便进行信息预处理的程序或脚本。随着互联网的普及与搜索引擎技术的不断发展,网络爬虫技术作为搜索引擎的核心技术,已被...

网络爬虫是搜索引擎技术当中的一类核心性技术,其技术主要是以遍历策略为基准,借助网页链接来收集整合网页当中必要类的数据信息,同时把其数据信息下载存储到本地的相应设备上,使得数据信息的预处理程序以及脚本等的使用变得更为流畅。...
1引言在这个信息爆炸的时代,搜索引擎已经成为一个新兴而重要的计算机应用领域,更是成为全球资本关注的一个亮点.搜索引擎克服了数据库中存在的不足,为数据的检索提供了更为方便快捷的方式.搜索引擎是以一定的策略在指定的搜索空间上收集和查找信息,对信...

搜索引擎优化既要有用户思维又要有搜索引擎思维,通过搜索引擎优化既要能够提升用户体验,又应使网站对搜索引擎更加友好,更加符合搜索引擎的收录规则,进而获得更多流量,实现企业网络营销目标。...
0引言在信息化时代,针对通用搜索引擎信息量大、查询准度和深度兼差等缺点,垂直搜索引擎已进入了用户认可和使用周期。垂直搜索是针对某一个行业的专业搜索引擎,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某...
以搭建节能减排领域的垂直搜索引擎为需求背景,利用Nutch开源框架,结合网页模板、向量空间模型以及朴素贝叶斯算法等技术,实现了垂直搜索引擎的开发。实验证明,完成的搜索引擎初步实现了对节能减排相关的信息检索,降低了工作人员获取该领域信息的难度。 ...

对于众多的企业来说,由于企业涉及到众多的专业领域,规模较大甚至有很多子公司,这样的企业通常每级单位都有自己的网站,这样对外可以展示企业形象,对内可以实现系统内企业网络化办公。...