������������


����0����
������Ϣ����ϵͳ��ҪΪ�������û��ṩ����Դ�ļ��������û�ͨ�������Լ���ҪѰ�ҵ���Դ��Ϣ��������Դ�IJ������ƣ���Դ��������عؼ��ʵȣ�����Ϣ����ϵͳ�����û��ṩ�ļ������������Դƥ�����Դ��λ��������һ����˳��ƥ�����Դ�������û�����������������Ϣ����ϵͳ�Ļ����Ϸ�չ������Ŀǰ������������Դ��·�Ϊ��Ŀ¼ʽ�������棬Ԫ�������棬������������ȡ�Ŀ¼ʽ���������Ե�ǰ�����İٶ��������棨�������ĵ��������ȸ��������棨���ڶ������Ե�������Ϊ����������Ҳ��Ҫ��Ŀ¼ʽ��������Ϊ����չ��������������ϵ�ܹ����о���
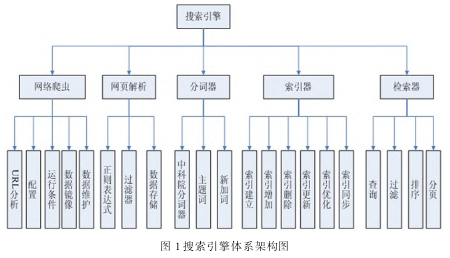
����1����������ϵ�ܹ�
�����������Ϣ����ϵͳ�����������ڼ���������ʱ����������Դ��Ԥ�������棬��������ϵͳ�Ż��˸����ϸ�ڣ��ڶ���Դ�����ƶ�ƥ�䷽�棬����������Ҫ���Ǹ�����������ۺ϶����û������ʺ���Դ֮������ƶȣ�����������������������ܶ�����������㷨��������˵������������Ҫ��Ϊ��������ϵͳ�����ݹ�����ϵͳ�����ӷ�����ϵͳ�ͽ��������ϵͳ�������������ϵ�ܹ���ͼ1��ʾ��
����1.1������ϵͳ
����������ϵͳ�����������ȡ��Դ����Ҫ��ʽ��������ϵͳͨ���ڻ��������������������ӳ����ڵĶԻ�������Դ���м�飬�ж�ָ��URL���ӵ������Ƿ����������ʱ�Ķ����ݽ��и��£��������º�����ݷ��������ݿ�ϵͳ��������ϵͳĿǰ��Ҫ�������ַ�ʽ������Դ��ȡ������ʽ��ȡ���ۻ�ʽ��ȡ������ʽ��ȡ��ʾ������ϵͳ���ݵ�ǰURL���ӵ�����ȥ������һ����ҳ���ۻ�ʽ��ȡ��ʾ���ݵ�ǰURL���ӱ���������֮��������ҳ�������µõ���URL���Ӽ��뵽���У���ɱ�����Ӷ�����ȡ�µ�URL����������������ϵͳ���ܵ�����ֱ�Ӿ��������������������������������Ϊ�����ݵ�ɸѡ����ҪҲ������������ϵͳ�������ݹ��ˣ�ɸѡ���м�ֵ����Դ��Ϣ��
����1.2������ϵͳ
����������ϵͳ���dzн���������ϵͳ��������Դ�����������ݳ��ֵ���һ��������߰�ṹ�����ݣ������˲����������ݸ�ʽ����������������ɶ���Դ��ɸѡ�������������������ϵͳ��Ҫ������������ͨ��������������ȡ��������Դ�������������չ�������ݽ��й���������������������Ϣ������������ݹ�����Ϊ��Ч�ķ�ʽ������ͨ�������ݵ���֪�Ǵ�����������ʼ����������Դ���ƣ����뵽��Դ�����������Ϣ����������������෴�������������ݹؼ��ʺ�������ȥ���ƾ������Դ���ơ�������������������ʱ�������뵽“�¶����”��“�Ƿ�”�ȣ�������Щ�ؼ��ʺ������������ǻ�������Ƶõ���Ӧ�Ľ�ӹ�����������������������“�������”��“�����˲�”�ȡ����������ķ�ʽ�����ǵ���������ϵͳ�Ǻ������ƣ��û�ͨ��������عؼ��ʺ�������ö�Ӧ����Դ��Ϣ��
�������ڵ������������ۻ��������Ƕ����������������Դ���нṹ���顣������Ҫ�����ݽ������ݷִʺؼ�����ȡ�������ĵķִ���һ��dz����ӵĹ��������IJ���Ӣ����������Ȼ���Կո���зָ���ķִ���Ҫ�������ַ����а��մ�����зָ�ָ���ÿ����Ԫ����һ���ؼ��ʣ����ж����Ľ��зִ���Ҫ�������ĵ����Թ淶���ص㣬��Ҫ��֤�ִ�֮��ÿ����Ԫ����һ�����������岿�֣�ͬʱ����Ҫ���Ƿָ�֮���������������ԣ���һ���棬�ڷִʹ�����Ҫ���Ƕ�ͣ�ôʣ��������������û��ʵ�ʺ���Ĵʣ���“��”����ȥ�ع������ִʺ�ͣ�ôʲ����൱�ڶ����ݵij�ʼ��������������ʼ��֮������������ݵij�ʼ��������������ϵͳ�Ĺ����ǽ��������ݳ�ʼ��֮���ĵ������ִ�֮���ĵ�����һϵ�йؼ�����ɣ���ʱ���Խ����ĵ��ؼ���֮��Ķ�ά����ά�����ж�Ӧ��Ȩֵ��Ϣ��ʾ�ؼ������ĵ��е�Ȩֵ��Ϣ���ؼ������ĵ��е�Ȩֵ����ͨ�����ַ�ʽ���Լ��㣬Ŀǰ��Ҫ�ɣ�TF������DF������TF-IDF������CHI������IG������MI������
����1.3���ӷ�����ϵͳ
�������ӷ�����ϵͳ���ǹȸ�ķ����㷨�������������ھ�������������м��ߵ����ۣ����ӷ�����ϵͳͨ���Ի����������ݽ��н�ģ���������ֻ�������ҳ֮��ͨ��URL���ӽ����˴�֮�����ϵ����ҳ֮��ͨ�������ӹ�ϵ����ҳ����ת��ͨ���Ի��������ӹ�ϵ����ȷ�������ҳ����Խ�ߵ���ҳ���䱻������ҳ������Ŀ�����Խ��֮��Ȼ��ͨ������һ���ɽ�����ȷ���������ģ�ͣ��ó���������ҳ����������ģ�ͣ�����ҳ����������������ҳ����������������ҳ��������PageRankֵ��PRֵ����ʾ���繫ʽ1��ʾ��
����PageRank��PR��ֵ=���·��ʸ���+�������ʸ��ʣ���ʽ1����
�������軥�����û��������ַ�ʽ������ҳ����һ��ͨ��һ����ҳĿ¼�������ѡ������һ����ҳ����������������֮�����»ص���ҳĿ¼���ٴ�ѡȡ�µ�URL���з��ʣ���������ѡ��һ����ҳURL���з��ʣ��Ӹ���ҳ����ȡURL�����б�����URL�����б������ѡ��һ����ҳURL�������ʡ����Ƕ���Ϊ�÷���ģʽ���������ģ�ͣ����ó���ҳ�������������۹�ʽ���繫ʽ2��ʾ��
����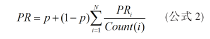
�����ڹ�ʽ2�У�p��ʾ�������·��ʵķ�ʽ����ҳ������ĸ��ʣ���Ӧ�ز��õ������ʵĸ���Ϊ��1-p������������ʱ�û�ѡ����һ��ҳ����з��ʵĸ���ȡ������һ��ҳ���PRֵ����ij��ҳ����������ҳ�����ж������ʾ���Ƕ�ÿһ��������ҳ����ȡƽ������Ȩֵ�ķ�ʽ��
����1.4���������ϵͳ
�������������ϵͳ���û�ֱ��������������н����IJ��֣����������ϵͳͨ���Է����û�ɸѡ���������ݿ�����Դ�������������������ϵͳ��Ҫ�ۺϿ��Ƕ������أ�������ҳ������PRֵ���û������ʺ�������Դ֮������ƶ�ֵ�ȶ�����档ͬʱ��������ϵͳ��Ҫ������α�֤�û���Ҫ����Դ���ڿ�ǰ��λ�á�����о����֣��û�ͨ��ֻ���ǰ��ҳ���������������е�������������ϵͳ����Ҫ��֤�ṹ�����ȷ�ԣ�����Ҫ��֤ȷ�ʺ��ٻ��ʣ�ͬʱ�dz���Ҫ����������ҳ�����ʡ�
����2�ܽ�
��������ͨ���Ե�ǰ������Ŀ¼ʽ�����������ϵ�ܹ������о�����Ҫ��������ϵͳ��������ϵͳ�����ӷ�����ϵͳ�ͽ��������ϵͳ�IJ��ֽ�������������ÿ����ϵͳ�йؼ��ʼ��������˽��ܡ�
�����ο����ף�
����[1]�Z����ʱ�⣬����졣����Web�ĸ��Ի�����������о�[J].�������������ƣ�2008,20:5206-5208.
����[2]�������������ֱ��������ϵͳ���о���ʵ��[J].�鱨��־��2009,10:144-147+169.
����[3]�ı�������诣��Ծ��ƣ���������ҵ����������Ի�����[J].�����ϵͳӦ�ã�2013,04:199-203.
����[4]١���ޣ����㡣һ���ض����������������漼�����о�[J].�����Ӧ���о���2004,05:49-51.

2013��2014���й�����������ҵ��չ������
����3~5��ķ��ٷ�չ��Ŀǰ�����������ƶ�����������ռ��ڽ�ɽ���ƶ��������иϳ�������������Ϊ��Ҫ����;��֮�ơ�2013~2014���й�����������ҵ���������������ٶȶ����ɧ��ͬʱ���������ߺ���и�������������ڹ�,ͬʱ�������������ڶٶȹ�����в...

������ҵ��Դ������������������������
���ĴӾ�����ҵ����Ϣ���ݼ�������������������˻���Solr����������������ҵ����������Ŀ����ԣ��������й��������漰Solr�����֪ʶ��...
1���Ի����������뷢չ�����˸���������Ϣ��Դ�����Ŀ������͡�����2014��6�£��ҹ�ӵ��273�����վ��3.3�ڸ�IPv4��ַ[1].��Ժ�嫾�����������Դ���û�ͨ������������ٻ�ȡ������Ϣ��Ϊ��Ҫ��Ŀǰ���ҹ����������û���4.9�ڣ�����ƽ��ʹ��...
�������������������崹ֱ�������湹��
1�����Խ�����,�������ֻ������˳��IJ����ƽ�,�ҹ��ڽ�����Դ���跽���Ѿ�ȡ���˾�ijɾ�,���������Դ���������ҳ��ּ��μ��������������������漼���ķ�չ,ͨ����������Ĺ��ܱ������ǿ��,ȡ���˺ܴ�ijɹ�,�������о�����,����������Ȳ���,...
��ǰ��������ļ�ֵ��˼������ԭ������������
��������ҳ������ѧ�����¬�����ڡ�����ý�飺���˵����졷�������ý�����˸о��������������չ����һ����������Ҫ���壬���ڽ��˵ĵ�һ�йٺ�ý��Ĵ������������˶�Ӧ�����磬���ӽ����쵽ӡˢý�飬���������쵽�㲥�Լ��ӡ�������ͬ���쵽���ӡ���...

�������澭����30��ķ�չ��Ŀǰ��ʹ�õ��м������ͣ���ȫ���������桢����Ŀ¼�������桢��Ԫ�������桢������������ȡ�����Щ���������ϵĹ�����ҵ�������棬������������������ҵ����Ҫ��...
��4��ģ���������������������ǰ�����������������۷����Ļ����ϣ���Ϸ�̸�Ľ����������������Ż�������Ч����ά�ȣ������������ߵĸ���ģ�ͣ�����˸��о�����֮��ļ����ϵ��4.1��̸����̸����ָ�о���ͨ������桢QQ�ȷ�̸��ʽ�����ܷ���...
���������漼���ķ�չ֮��,���ܼ�����Ϊһ�����͵ļ�����ʽ�Ѿ��������������ݵ������,���ּ�ⷽʽ�ܹ��������Ǽ�������������Ϣ,�Ǽ�����ʽ��չ��һ�ֱ�Ȼ����,�������ھ���Ӧ����������Դ����ʵ�����ܼ����ķ�չ,Ҳ�ܹ�Ϊ�����ṩ�����Ӿ��������...
������������������������ķ�չ�ͽ������������ݵ���Դ�����Լ���Ϣ�ļ��ɶ���֮ǰ���ӱ�ݺ���Ч�ˡ������������������˼�����������SESϵͳ�����ݲɼ��������Ļ��ƣ����ҽ���������Ϣ�����ݵĹ������ص㣬�ƶ���һ�״ӽṹ��ϵ���Լ���ȫ����Ϊ��Ҫ...
��Lucene�ܹ����ڰ�ϵͳ����������������
�ڼ���������Լ����缼���ر����ƶ�ͨ�ż������Ϸ�չ�ı����¸������ֻ������˼���ķ�չ�ռ䡣Ŀǰ���ܹ�ʣ�Ѿ���Ϊ�˵�ǰ�����ֻ����ձ�����֮һ��Ӳ�����ܹ���ǿ��ı������������ܸ��ϲ�������Ҳ�͵������û��������Գ�����һ���̶ȵ��½������˻�...