水文学论文


0、 引言
洪水预报是指运用前期和现时的水文、气象等信息,揭示和预测洪水的发生及其变化过程的应用科学技术,直接为水库的防汛抢险、水资源的合理利用及工农业的安全生产服务。传统的洪水预报模型使用实测降水信息进行预报,其预见期取决于流域汇流时间,预见期较短,不利于水库的防洪调度。若能延长预见期,水库就能及时预泄和预蓄,能有效提高水库防洪安全和增加水电资源利用率。因此,延长洪水预报预见期就显得尤为重要。
现阶段,随着世界各国气象预报技术的迅猛发展,利用气象水文耦合模型延长洪水预报预见期已经成为国内外研究的热点,高冰等利用中尺度数值天气预报模式 WRF 和分布式水文模型 GBHM 对三峡水库2000 年 7 场洪水的研究,延长了洪水预报预见期,陆桂华等用加拿大区域性中尺度大气模式 MC2 和新安江模型单向耦合模型系统对淮河流域 2005 年 7 月的一次暴雨洪水的研究,延长了洪水预报预见期,Z.Yu等构建了中尺度模式 MM5 与水文模型 HMS 耦合模拟模型,该模型能够模拟流域的部分流量过程。上述研究表明了气象水文耦合模型有很好的应用前景,但洪水预报应考虑获取降水预报信息的实时性和方便性,而国内目前并不能方便地实时获取其使用所需的降水预报信息;且降水预报信息存在一定的不确定性,若直接输入到洪水预报模型中,不同时间的洪水预报精度波动较大。
本文以桓仁流域为研究背景,使用可从天气在线网站上方便实时获取的 GFS 降水数值预报信息,首先改进原洪水预报方案,挖掘出可在单位线法汇流计算中准确选择单位线的规则,其次对 GFS 信息进行修正释用,利用释用后的 GFS 降水数值预报信息与洪水预报方案耦合,以期达到延长洪水预报预见期的目的。
1、 工程背景
1.1 流域水文气象特征
桓仁流域面积为 10364km2,属于半湿润地区。流域年均降水量 860mm。一年中 70%的雨量集中在 6~9月,大洪水多发生在 7~8 月。一次天气过程造成的暴雨历时较短,致使大多数洪水呈单峰型。一次洪水历时 7 天左右,涨洪历时一般仅需要 1 天左右;退水历时一般 6 天左右;一次洪水总量多集中在 3 天之内。
1.2 水库概况
桓仁水库是浑江梯级电站的龙头,是以发电、防洪为主兼顾其他综合利用的不完全年调节水库。千年一遇洪水设计,万年一遇洪水校核。水库的死水位为 290m,正常蓄水位和防洪限制水位均为 300m,50 年一遇的防洪高水位为 306.0m。兴利库容为 8.2?108m3;防洪库容为 12.6?108m3;总库容 34.6×108m3。
1.3 原洪水预报方案
原桓仁流域产流预报方案为新安江产流模型。以 1966-2005 年的 77 场洪水为模拟期,并使用优化技术率定产流参数。根据我国现行《水文情报预报规范》SL250-2000,径流深相对误差小于 20%,绝对误差小于 20mm,为合格预报。模拟预报合格场次为 70 场,合格率 90.91%。以 2006-2010 年的 10 场洪水作为检验期,检验预报合格场次为 9 场,合格率 90%。产流预报方案精度甲级。
桓仁流域原汇流预报方案,根据历史雨洪资料中具有明显峰型的洪水,分析归纳出了六条6h时段单位线。按现行规范,洪峰预报以实测洪峰流量的20%作为许可误差,峰现时间以1个计算时段长为许可误差。原汇流预报方案使用六条6h时段单位线进行汇流计算,调度人员凭经验选取某一条单位线的汇流计算结果作为预报方案。
2、 挖掘选择单位线的规则
作业预报时,并没有整场洪水的雨洪资料,调度人员凭经验选取某一条单位线会造成预报结果的不稳定,时常出现较大的偏差。因此考虑进行数据挖掘,挖掘出选择单位线的规则,使汇流计算可依据规则直接准确地选取单位线。
2.1 选择单位线的影响因子
使用历史实测雨洪资料进行数据挖掘。为减小未来因使用预报降水信息与实测降水信息间存在的误差对规则造成的影响,降水量均采用分级方式进行处理。根据降水类型和单位线的关系,选取单位线影响因子并进行量化。
通过对流域历史实测雨洪资料分析,拟定选择单位线的主要影响因子有 8 个:前期影响雨量,6h 时段降水量大于 5mm 的历时,6h 时段降水量大于 10mm 的历时,次降水总量级,次平均降水量级,降水均匀程度,暴雨中心,降水分布趋势。前期影响雨量 Pa 为本场洪水降水开始时的前期影响雨量。
6h 时段降水量大于 5mm 历时为流域次降水 6h 时段降水量大于 5mm 的时段数,反映雨强适中的降水在一场洪水中的分布情况。6h 时段降水量大于 10mm 历时为流域次降水 6h 时段降水量大于 10mm 的时段数,反映雨强较大的降水在一场洪水中的分布情况。
次降水总量级是将流域次降水量分为 5 个级别,分析流域历年次降水量资料,按 30mm 降水量为一个级别进行划分。
次平均降水量级为次洪的 6h 时段平均降水量的级别,按照 GFS 发布的 6h 时段降水数值预报图中的量级进行分级,共 10 级,分级标准如表 1 所示。为减小因区间范围过大造成的规则误差,考虑设置 0.5 级别,如 6h 时段降水量级为 5~10(mm)的量级为 4 级,增设为 5~7.5(mm)为 3.5 级,7.5~10(mm)为 4 级。
降水均匀程度为反应次降水量分布均匀度的量化,值越小表示降水在整个流域分布越均匀,采用式(1)计算。

式中: max( Ps )为雨量站的次降水量最大值; min( Ps )为雨量站的次降水量最小值; average( Ps )为流域次降水量均值。暴雨中心根据桓仁流域 10 个雨量控制站的雨量大小进行划分,按距坝址距离分为上段、中段和下段,按在流域的位置,又分为偏左、偏右。
降水分布趋势,分为下游向上游递减和上游向下游递减两种情况。

2.2 挖掘选择单位线规则的方法与步骤
1) 数据挖掘的决策树方法
数据挖掘(Data Mining,简记 DM)是采取专门算法对数据库中不明显的、潜在的数据关系进行分析与建模。可采取的算法有神经网络、主成分分析、决策树等方法。本文采用决策树方法对选择单位线的规则进行数据挖掘。决策树方法的优点有: 可生成较好理解的规则;计算量不是很大; 可处理连续和种类字段; 可以清晰的显示哪些信息较重要。
2) 挖掘选择单位线规则的步骤
本文采用 1966-2005 年流域实测雨洪资料对选择单位线规则进行数据挖掘,使用 2006-2010 年的流域实测雨洪资料进行检验。步骤如下:
第一步:使用流域实测降水资料对 1966-2010 年的 87 场洪水进行模拟计算,记录下每场洪水使用六条6h 单位线进行汇流计算的 6 个结果中,与实际洪水过程最接近的单位线名称及其 8 个单位线影响因子的数据信息。
第二步:利用第一步的 1966-2005 年的 77 场洪水的各项数据,进行决策树方法挖掘,初步归纳出十条选择单位线的规则。
第三步:用十条选择单位线的规则对 1966-2005 年的 77 场洪水进行模拟计算,与第一步中记录的与实际洪水过程最接近的单位线名称以及合格率进行对比,对规则进行多次修正,让使用选择单位线规则的汇流计算结果与第一步记录的结果较接近,得出最终的十条选择单位线的规则。
第四步:使用十条选择单位线的规则对 2006-2010 年的 10 场洪水进行检验计算。
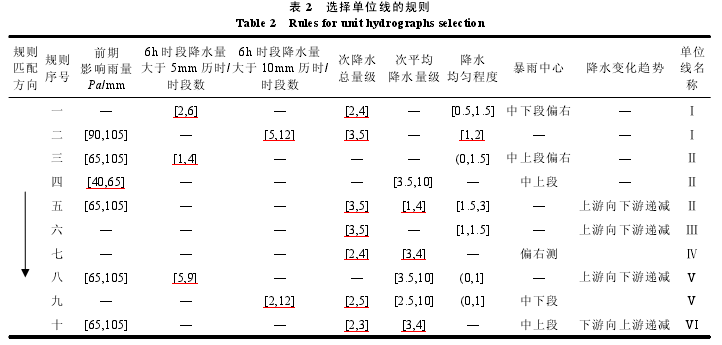
2.3 选择单位线的规则
综上,十条选择单位线的规则如表 2 所示。每条选择单位线规则中的影响因子需同时被匹配上才能使用该条选择单位线的规则,出现其他情况时使用单位线Ⅰ进行汇流预报。
2.4 改进后洪水汇流预报方案的精度分析
1) 1966-2005 年数据挖掘期的汇流计算结果
1966-2005 年 77 场洪水使用上述选择单位线的规则进行汇流计算,峰值合格场次为 66 场,平均相对误差为 11.52%;峰现时间预报合格场次为 69 场。汇流预报合格率为 85.71%。
2) 2006-2010 年检验期汇流计算结果
2006-2010 年 10 场洪水使用上述选择单位线的规则进行汇流计算,峰值合格场次为 9 场,平均相对误差为 12.01%;峰现时间预报合格场次为 10 场。汇流预报合格率为 90%。综上可知,使用选择单位线规则的汇流预报方案精度为甲级,可用于发布正式预报。
3、 GFS 降水预报信息与洪水预报方案耦合
3.1 GFS 降水数值预报信息的获取
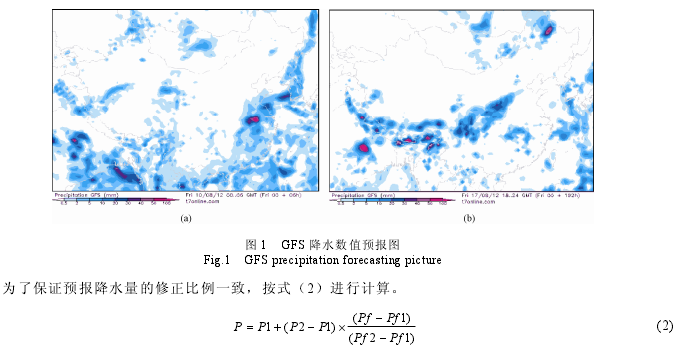
GFS(Global Forecasting System),由美国国家环境预报中心研制的降水预报模式,是应用较广泛的全球数值预报业务模式之一。按格林尼治时间(GMT)每日 00,06,12 和 18 点(北京时间为当日 08,14,20点和次日 2 点)发布未来 1~16dGFS 模式计算的全球各地区降水情况。其中,预报精度较高的未来 1~8d 降水预报模式,以 6h 时段间隔进行数值预报。图(1)为 2012 年 8 月 10 日 GMT00 时 GFS 发布的东亚地区降水分布情况,其中,(a)为 8 月 10 日 GMT00 时至 06 时的降水等值面图,(b)为 8 月 17 日 GMT18时至 24 时的降水等值面图。
GFS降水等值面图从天气在线网站(t7online.com)获取后,首先需要在图中对流域的位置与站点进行定位,然后利用开发的读图程序,从图中读出相应站点的降水数值预报信息。
3.2 GFS 降水数值预报信息的释用
数值预报产品释用是对数值模式预报产品的进一步“解释应用”,具体来说通过统计、动力、人工智能等方法,综合预报经验,利用历史资料对数值预报的结果进行分析、订正,建立预报模型,最终给出客观要素的预报结果。
主要原因为 GFS 系统误差和读图程序算法计算误差,造成了 GFS 降水数值预报信息的不确定性。因为 GFS 预报系统内部计算原理并不对外公布,无法获知具体的系统误差原因,但是预报结果时有出现空报和漏报的情况。故本文使用统计学的方法对桓仁流域 10 个雨量站 2006-2010 年 10 场洪水的 GFS 降水数值预报信息进行修正释用,主要为消除空报和漏报造成的误差。
GFS 预报 6h 时段的降水量级(见表 1 所示的降水量分级),实际可能会发生其他量级的降水,统计分析雨量站点各预报降水量级的实际发生降水量级的频率。可知:若 GFS 预报 6h 时段降水量级为 0~5mm 时,实际发生 0~5mm 降水量级的频率为 85%,精度较高,因此,对 GFS 降水数值预报信息的修正释用将针对6h 时段预报降水量大于 5mm 的降水量级。若 GFS 预报 6h 时段降水量级为 50~75mm、75~100mm 时,实际发生较小量级降水的频率明显较大,所以 GFS 预报 50~75mm、75~100mm 的降水量级时,直接修正为实际降水发生频率最大的降水量级。对其它 GFS 降水预报量级,由于实际降水量级发生频率分布较分散,若仅按实际降水发生频率最大进行修正,修正结果稳定性较低。因此本次研究使用分开量级对 GFS 降水预报值进行修正释用。
根据桓仁流域历史实测降水资料,次降水分布为初期雨量较大,后期较小。故考虑修正方法为:GFS预报 6h 时段降水量时,以该预报降水量级为分界点,将实际发生的降水量级分为两个子区间,如:GFS预报 6h 时段降水量级为 4 级,则将实际发生降水量级分为[1,4)、[4,10]两个子区间。先在比该预报降水量级大的子区间进行修正,将时段预报降水量级修正为该子区间中实际降水发生频率最大的降水量级。根据实际降水过程知,发生较强降水的时段一般不会连续超过 2 个时段,为避免修正后的次降水总量级过大,一场预报降水过程连续两个时段 GFS 预报降水量级向高量级修正,则在接下来两个时段 GFS 预报降水量级修正中,一个时段保持原量级不变,下一个时段在比该时段预报降水量级小的子区间进行修正,将该时段预报降水量级修正为该子区间中实际降水发生频率最大的量级。
式中:[ Pf 1, Pf 2]为修正前的预报降水量级区间;[ P1 , P 2]为实际降水发生频率最大的降水量级区间; Pf 为修正前的预报降水量; P 为修正后的预报降水量。由于 GFS 每次发布时的实时气象环境发生了变化,每次发布的对同一时间段的降水预报信息会进行调整。为了使预报信息更准确,对次洪前 GFS 连续四次发布的对同一时间段的降水数值预报信息按上述修正方法修正后,再加权平均,作为此时间段 GFS 预报降水量的释用值。因降水数值预报预见期越短,降水数值预报信息可信度越高,最近时刻 GFS 发布的降水预报信息权重应最大,本文对次洪前 GFS 发布的四次同一时间段的降水数值预报信息的权重分别率定为 0.1、0.2、0.3、0.4。
3.3 释用后的降水预报信息在单位线选择规则中的可利用性分析
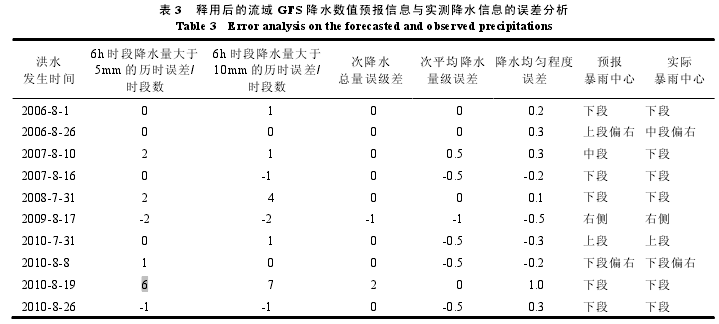
按照 3.2 节方法对场次降水前 GFS 发布的桓仁流域 10 个雨量控制站的降水数值预报信息进行释用,流域面雨量为 10 个雨量控制站雨量的面积加权。统计分析 2006-2010 年桓仁流域 10 场次降水释用后的 GFS降水数值预报信息与实测值的误差,包括:6h 时段降水量大于 5mm 的历时,6h 时段降水量大于 10mm 的历时,暴雨中心,降水均匀程度,次降水总量级,次平均降水量级等。统计分析结果如表 3 所示。
选择单位线的规则中,单位线影响因子的数据信息均用一个区间表示。次降水总量级和次平均降水量级区间均大于 1 个级别,所以降水总量级误差和平均降水量级误差在 1 个级别内则为允许误差;6h 时段降水量大于 5mm 的历时的区间均在 4 个时段以上,所以 6h 时段降水量大于 5mm 的历时误差在 4 个时段内则为允许误差;6h 时段降水量大于 10mm 的历时的区间均在 7 个时段以上,所以 6h 时段降水量大于 10mm的历时误差在 7 个时段内则为允许误差;降水均匀程度区间均在 1 以上,所以降水均匀程度误差在 1 以内为允许误差;暴雨中心误差要求必须是相邻流域段内。
3.4 利用释用后的 GFS 降水数值预报信息进行洪水预报
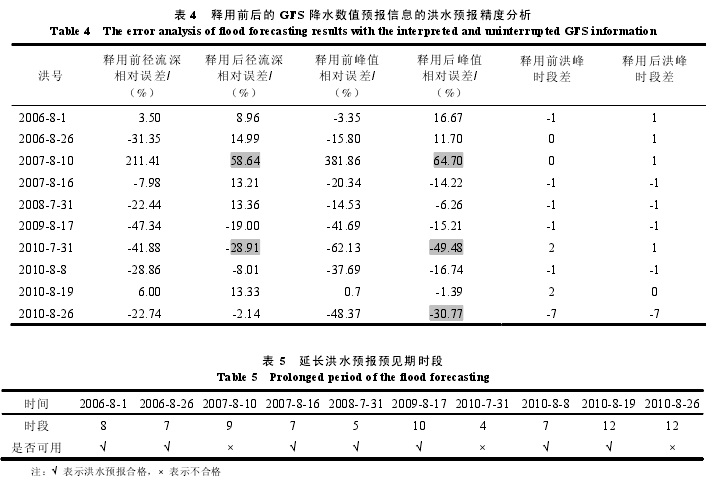
使用释用后的桓仁流域 GFS 降水数值预报信息选择单位线,2006-2010 年 10 场次产汇流计算结果见表4 所示:产流预报合格场次 8 场,径流深相对误差为 18.06%;汇流预报合格场次为 7 场,洪峰相对误差为22.71%。而使用未修正 GFS 降水数值预报信息进行产汇流计算的结果为:合格场次仅为 4 场,径流深相对误差为 42.35%,洪峰相对误差为 62.7%。可知,使用 3.2 节方法修正释用后的 GFS 降水数值预报信息进行洪水预报结果较好,可用于选择单位线作业预报。
桓仁流域使用释用后的 GFS 降水数值预报信息进行洪水预报,可延长洪水预报预见期 5~12 个时段(6h一个时段),见表 5 所示。
4、 结论
本文利用决策树方法挖掘出了桓仁流域十条选择单位线的规则,其中降水信息可直接利用释用后的GFS 降水数值预报信息,减少了选择单位线时因人为经验和实时修正重选单位线造成的误差,使洪水预报更精确。就桓仁流域,GFS 降水数值预报信息预报小于 5mm 降水量的精度较高,而对大于 5mm 降水预报信息采用统计频率修正释用后,精度取得较大提高,为洪水作业预报准确选择单位线提供了可使用的降水预报信息。
释用后的 GFS 降水数值预报信息与洪水预报方案耦合,能有效的延长桓仁流域洪水预报预见期 30~72小时。随着世界各国气象预报技术的持续发展,降水数值预报精度会越来越高,本文研究的基于释用后的降水数值预报信息与洪水预报方案耦合延长洪水预报预见期的方法会有良好的应用前景,为水库和流域带来更大的防洪和兴利效益。
参考文献:
[1] 高冰,杨大文,谷湘潜,等.基于数值天气模式和分布式水文模型的三峡入库洪水预报研究 [J].水力发电学报 2012,31(1):20-26.
[2] 陆桂华,吴志勇,雷 wen,等. 气耦合模型在实时暴雨洪水预报中的应用 [J].水科学进展,2006,17(6):847-852.
三江源区径流量对降水量的响应关系存在明显的空间差异,但61.8%的区域径流量对降水量的响应关系并未发生明显变化或者在波动中保持相对稳定的关系。少部分地区径流量对降水量的响应关系发生明显变化,反映出冰川融雪和人类活动对流域产流机制的干扰。1957...

小河是茹河一级支流,是泾河二级支流,发源于甘肃省环县庙儿掌,在彭阳县城汇入茹河干流,流域面积1127km2,主河道长74.6km。随着上游水利工程及水保措施的实施,以及连续多年的气候干旱等重要原因,小河水量逐渐减少,水资源短缺等问题越来越突出,已成为...
白龙江属长江二级支流,嘉陵江一级支流,河流全长535km,流域面积32810km2,多年平均径流约40108m3,发源于甘肃省碌曲县与四川省若尔盖县交界的郎木寺乡,向东流经碌曲、若尔盖、迭部、舟曲、宕昌、武都、文县、青川及广元9个县(市),于昭化县旧城北部汇入嘉...
20世纪80年代以来,我国沿海地区城市的海水入侵现状日趋严重,据国家海洋局监测结果显示,辽东湾北部及两侧的滨海地区海水入侵的面积已超过4000km2,莱州湾海水入侵面积已达2500km2[1].监测及研究结果显示在深圳地区也存在不同程度的局部海水入侵区[2,...
0、问题的提出为了河道整治或河道内工程建设的需求,经常需要预测推求工程涉及河段在未来某时期的水位变化,工程所在河段的水面线计算是防洪评价中的重要内容。例如,在多沙河流的行洪滩地内修建公路或跨河修建桥梁,工程建设会侵占部分主槽与滩地,造成对...
由于日地间距离的变化、工业化进程的加速及其他相关人类活动已经严重影响到了全球气候系统,改变了全球的能量收支,气候变化已经成为一个不争的事实,已得到人们的认可.相继气候变化,海平面的上升、冰川与积雪的加速消融以及洪、涝、旱灾害的频现,已经严重影响...
全球气候变化正越来越受到当今社会的关注。近年来,我国西北干旱区气候变暖显着,气温以0.2℃/10a趋势上升。同时西北地区西部和中部降水量显着增多,大部分地区出现了气温升高,降水增多的暖湿化趋势。这势必会不同程度的引起水资源时空上的重新分布和...