计量经济学论文


计量经济学已成为我国高校经济管理类学科本科和研究生必修的核心理论课程之一,并在我国经济学界越来越受到关注,正可谓经济学界的“宠儿”,引领经济学的研究方向。任何计量经济学研究都离不开高质量的数据。然而对计量经济学学者来讲,数据都是观测数据而非实验数据,很难得到大而全、高质量的数据,导致模型拟合存在天生缺陷。经济理论或模型作为对复杂现实经济的简化抽象,只能刻画主要的或重要的经济因素。而实际观测到的数据却是由许多因素共同作用的结果,其中,有些因素是未知的或不可观测的,或者没有包括在经济模型中,因此反映不出它们的影响。数据搜集困难导致数据不全、质量不高,加之计量模型假设过于苛刻和模型的过度拟合等缺陷致使处理结果缺乏可信度和实用性,因此当下计量经济学研究价值也饱受争议。自然科学中很多学科,如物理学,能够精确地把握物体运动规律和预测物体运动变化,一个重要原因是所研究的物理系统在相当长的一段时间内不具有时变性。经济系统则有很大不同,经济发展是一个不可逆或不可重复的动态过程,经济关系和经济系统也常常发生时变和结构性变化。
大数据概念炙手可热:随着互联网的发展,大数据有着强大的数据采集能力,且数据的采集具有实时性;大数据处理和数据建模都有专业的大数据团队来完成;计算机本身拥有强大的计算、分析和处理能力,计算机没有失误(除非程序本身错误)、不存在偏见和丰富的感情色彩。大数据使得不论是在数据的采集、数据的挖掘、数据的处理和数据建模等方面都有了质的飞跃,然而大数据能否弥补计量经济学的局限?在哪些方面、多大程度上弥补?大数据又将给计量经济学带来哪些影响和冲击?
一、计量经济学的局限性
(一)数据
1.数据的搜集
计量经济学研究的成功离不开全面、高质量的数据。然而,全面、高质量的数据离不开高水平的数据采集。因为受数据采集的工具、采集的条件和采集人员的失误等因素的限制,导致经济数据可能存在测量误差,数据很难满足高质量、全面、准确的要求,且经济学学者搜集到的原始经济数据几乎都已经过工作人员的处理,工作人员在数据统计时难免带有偏见和盲点,无论预测人员带有什么偏见和盲点,这些偏见和盲点都可能会被复制到他的计算机程序中,加之工作人员的偷懒和难以避免的失误等人为因素,都会使得采集的数据存在失真可能,数据经过多重的辗转反侧和多级的蹂躏才到达研究者手中。一些经济变量数据缺失,也使得经济理论研究数据缺乏完整性,给计量经济学研究带来阻碍。
同时经济数据的获得存在严重的时滞现象,时滞也使得数据的使用价值和统计计量研究价值黯然失色。如美国劳工统计局的人员每个月公布(CPI),联邦政府为了得到相关数据,要雇佣很多人向全美90个城市的商店、办公室打电话、发传真甚至登门拜访。然而采集到的各种各样的数据信息达80000种,政府要采集这些数据每年大概需要花费两亿五千万美元。这些数据是精确的也是有序的,然而从数据的搜集到到达统计计量经济学者手中再到结果的公布会滞后数周。2008年的经济危机表明,这种滞后是致命的。对于计量经济学学者来说,所使用的数据时间跨度更大,要求披满厚厚灰尘的数据有“左右”未来经济的能力,未免力不从心,数据的过于陈旧,也使得计量经济学模型频繁遭遇滑铁卢。
2.数据的处理
对于搜集到的数据,作为数据的应用方--经济学学者只能被动接受。建模者通常面对的是观测数据而非实验数据。这对计量经济学中的经验建模有两方面的重要含义。首先,要求建模者掌握与分析实验数据极为不同的技巧……其次,数据搜集者与分析者的分离要求建模者十分熟悉所用数据的性质和结构。
因而经济学学者只能凭借个人经验等手段屏蔽自己眼中的噪声--对数据进行加减乘除等各项处理(微观经济数据推宏观经济数据尤为如此)。在对数据进行处理时,受制于分析能力和技术条件的限制,经济学学者对搜集到的数据(尤其超大型数据)很难进行再处理,或者进行简单的处理,乃至不处理;即使处理也是根据学者要求进行,按照经验来看,所有人都有各自的信仰和偏见--这种信仰和偏见是由个人的阅历、价值观、知识、涵养、政治立场或者专业背景等因素凝聚而成,处理的数据也很难给出公正合理的结果;计量经济学学者在数据选择时可能存在样本的选择偏差,数据与经济模型中的变量的定义可能不相符或贴合度过低;因为过分追求模型的精确性,学者常常以特别数据严重偏离曲线为正当理由对数据进行抹杀;数据处理时细分维度低、无精细的数据,使得曲线过度拟合风险增加,且原始数据很难二次细分,也给数据的应用带来阻碍;宏观经济数据大都由微观经济数据简单的加减乘除得来,这种处理可能是应用两个或者多个低相关度的微观数据组推导宏观数据,可能改变宏观经济变量之间的关系。数据形式多样化:随着互联网的发展,数据不仅仅是可观测的结构性的数据,还存在不可观测的半结构性和非结构性数据(谷歌的搜索词条)等等,计量经济学却没有能力对结构性数据之外的数据进行处理。
计量经济预测者面临的最大挑战之一就是,他们的原始数据质量不高。经济预测者在进行预测时,很少公开自己的预测区间,或许是因为这样做会降低公众对他们的专业知识的信任度。哈祖斯说:“经济预测者为什么不公开预测区间呢?因为他们怕出丑。我认为就是这个原因”.然而,不仅经济预测中存在着不确定性,经济变量本身也具有不确定性。大多数经济数据序列都需要修正,统计数据已经公布,修正工作可能长达数月甚至数年。
(二)数据建模
1.模型假设
计量经济模型的构建之前,需要对函数形式提出众多前提假设,如最小二乘法的基本假设:x值是固定的或独立于误差项;干扰项ui的均值为0;各干扰项之间无自相关等。一个非常有价值的问题是:所有这些假定有多真实?这个“假定现实性”的问题是科学哲学中的一个古老问题。有一派观点认为假定是否真实无关紧要,重要的是基于这些假设的预测。以“假定无关紧要论”着称的弗里德曼,对他来说,假定的非真实性有着积极的意义。“为了有意义,……一个假设在其假定中从描述上看必定是错误的。”
但是回想一下在任何科学研究中我们做某些假定,都是因为它们便于逐步开展主题研究,并不因为它们在准确地复制了现实的意义上必须是真实的。但是,如一位作者所说,“……如果简单性是好的理论所盼望的一个准则,那么所有好的理论都将肆无忌惮地理想化和简单化。”模型漏洞百出,提出利己假设更多的是为弥补模型漏洞。
为了方便对经济数据进行统计分析,计量经济学家常常要假设一个经济系统的运行规律具有不随时间和个体改变的某些特征,比如假设经济系统具有时间平稳性或不同经济人的数据生成过程具有同质性。而任何经济系统的时变性(不确定性)是影响经济系统最主要的因素,一些经济预测者不愿意让人们知道这一点。与其他大多数学科门类的预测者一样,计量经济预测者将不确定性视作仇敌--威胁其名誉的天敌。他们没有对经济时变性做出准确地预测,而是无端地认为预测模型中的不确定性降低了,但在现实理论研究中,他们却无法提高预测的质量,这样做也无法改进真实经济中的预测。一旦洪水来袭,我们将毫无准备。假设给模型带来的害处就是给模型套上了枷锁,使得模型与实际相去甚远,多数模型只是划过天空的流星--经不起时间的考验。
2.模型拟合
计量经济学家建立经济理论或模型,目的就是解释这些经验特征事实。这一阶段的关键是建立合适的经济数学模型,模型的好坏事关经济研究的成败。大多失败的模型预测大都源于一种盲目的自信导致的过度拟合,模型实际所能解释的问题和自认为所能解释的问题之间存在鸿沟。他们用精确的预测冒充精准的预测。在统计学中,将噪声误认为信号的行为被称为过度拟合。拟合的说法源于统计模型和过去的观测值贴合度,当过于粗略地拟合时即不充分拟合,就意味着你在对观测数据中的噪声进行拟合,而不是挖掘数据的深层结构。在计量经济学研究领域,过度拟合的错误更为常见。
为了弄清这种错误的成因,我们暂且赋予自己一种在现实中几乎不可能拥有的优势--我们清楚地知道真实数据的庐山真面目。如图1,画了一条平缓的抛物线,顶点落在中间位置,末端逐渐增强。这条抛物线代表着我们想了解的所有现实数据。但是,我们还是不能直接观察到隐藏在数据中的深层关系,这种关系由一系列的独立的数据点体现,而我们只能从这些点推断出这种关系模型。此外,这些数据点必定受特殊环境的影响--有信号,有噪声。在图1中,画了100个数据点,分别用圆形和三角形标记,貌似这样就足以从噪声中捕捉到信号。即使这些数据中存在一定程度的随机性,但显然它们仍遵循此抛物线。
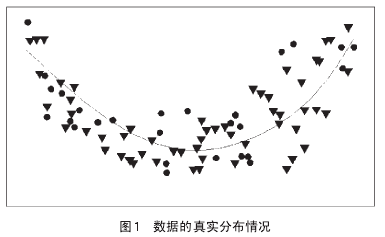
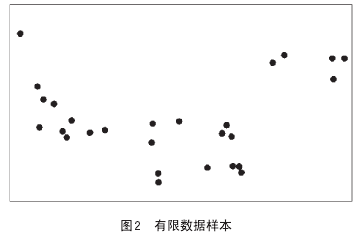
然而,当我们的数据相对有限时(现实情况常常如此),情况将会如何呢?那时我们就更可能陷入过度拟合的陷阱中。在图2中,将100个数据点缩减至25个,这时,你会如何连接这些点呢?
当然,前面已假设我们知道真实数据应该呈现的关系模型,就会自然地将它们连接成为一条抛物线。当然,这样的数学表达式用二次方程式可以很好地重建真实的关系模型(图3)。
但是,在无法得知数据拟合的理想模型时,我们有时就会表现得贪婪和聪明的无知。如图4,一个过度拟合的模型案例。在图中,设计了一个复杂的函数,可以追踪每一个边缘数据点,建构“准确”的数学模型,用这个函数连接这些点,曲线的上下波动陡然增强。这使得模型离真实的关系模型相去甚远,也使得预测更离谱。
这个错误貌似很容易避免,前提是我们无所不知,对数据的深层结构总是了如指掌,因此避免这个错误就显得很轻松。然而,几乎在所有的计量经济学研究工作中,我们都必须利用归纳法,从已知的证据中对其结构进行推断。当数据有限且充满噪声时,且我们对基本关系的理解很浅显时,就更有可能对一种模型做出过度拟合,在对经济危机预测时,这两种情况可谓司空见惯。
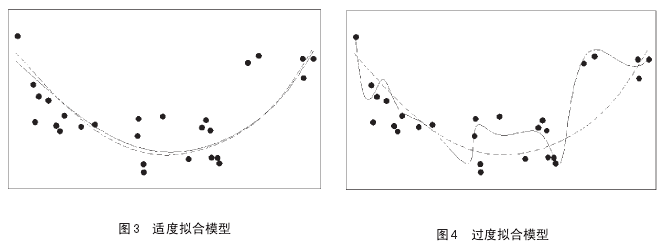
如果我们既不在乎也不知道数据关系的真相,就有很多理由解释我们为什么倾向于过度拟合的模型。其中之一就是,在计量经济学学者最常用的统计测试中,过度拟合模型更受青睐。有一项测试是用以测试拟合模型可以解释多少数据的变化。根据这一测试,过度拟合的模型(图4)解释了85%的数据变化,而适度拟合模型只解释了56%的数据变化。但是实质上,过度拟合模型是在混淆视听,将噪声误当作信号混入模型中。事实上,在解释真实世界时,它的表现更糟。
这种解释似乎让情况一目了然,但很多计量经济学学者完全无视此问题。研究者拥有众多统计检验方法,可这么多的方法却没有使他们增加一点科学态度,减少一点幻想,而是更像充满幻想的孩子在天空中寻找动物形状的云一样。
过度拟合代表了双重毒运:过度拟合模型表面上看来比较好,但其实际性能却很糟糕。因为后一种因素,若被用在真实的经济预测中,过度拟合模型最终将使得预测者付出惨痛的代价。而因为前一种因素--其表面效果不错,而且自称可做出非常准确并且经济价值很高的预测,所以,这类模型更吸引人,更易在学术期刊上推介。但是,如果这个模型是用噪声拟合的,就很有可能会阻碍经济的预测,进而阻挠经济发展。应该说明的是,这些错误司空见惯。它影响我们,让我们更容易被“随机性愚弄”.我们也可能会越来越迷恋此模型的特质,甚至可能会创造出一个貌似很有说服力的理论来佐证这一错误的合理性。
从逻辑的角度来看,这有点像观测者效应(长被误认为海森堡的不确定性原理):一旦我们开始测量某物,它的行为就会主动乃至被动发生改变。大多数统计模型都是依托这一概念建立的,自变量与因变量、信号与噪声,彼此之间泾渭分明,但在经济领域中,它们彼此之间却混在一起、乱作一团。
(三)模型检验和预测
以统计检验着称的计量经济学,做普通的线性回归分析时,如研究自变量和因变量的关系时,对自变量回归系数采用t检验,计量经济学界公认t<0.05就说明两变量相关,精确度则在95%以上。计量经济学学者在收集样本的时候应用一整套的方法减少错误发生的概率。在统计检验之前,他们也会检测样本是否存在潜在的系统性偏差。这些规避错误的手段无不在美化结果。一味的追求“精确性”,无时不在驱使着统计计量学家去挖掘更加“智能”的算法系统模型。回归分析有一些值得提出的基本分歧:在回归分析中,对解释变量和因变量的处理方法存在着不对称性。因变量被当作是随机的、统计的,也就是因变量有一个概率分布。而解释变量则被看作是在重复抽样中取得固定值。解释变量本身也是随机的。但是出于回归分析的目的,计量经济学学者假定它们的值在重复抽样中固定不变(即X在不同的多个样本中取同样的一组值),从而把它们转变成实质上非随机的。
计量经济模型通过实证检验拟合成功后,可用来检验经济理论或经济假说的正确性以及提供政策建议,当然最终要预测未来经济的走向。模型的质量决定预测的质量:墨菲提出,衡量预测的一种途径--或许也是最显而易见的途径--就是通过他所说的“质量”,但何种质量才可被认定为准确呢?“质量”是指预测与实际天气相符合吗?无论预测得多么准确,这个预测是预测者当时的巅峰之作吗?这个预测是否反映了预测者的最佳判断呢?公之于众之前,这个预测是否作了某种程度的修饰呢?预测是否有经济价值,判断的依据就是,预测是否有助于公众或政治决策者做出更好的决定或决策。
经济理论或模型作为对复杂现实经济的简化抽象,只能刻画主要的或重要的经济因素。而实际观测到的数据却是由许多因素共同作用的结果,失败预测的模型可能应用非样本数据,其中有些因素是未知的或不可观测的,并没有包括在经济模型中,或者数据的“信噪比”过低,因此反映不出它们的影响,而计量经济学学者却没有足够的能力和技术做出甄别。这点与自然科学不同,自然科学研究可以通过可控实验过滤或消除次要因素的影响。在经济学领域,经济学家通常是数据的使用方,大多数收集到的经济数据都是非实验性的。因此无法从观测到的经济数据过滤出经济模型以外的因素所产生的那一部分影响,这便造成经济实证研究的困难。
经济数据和经济系统的上述特征,不可避免地造成了计量经济学实证研究的局限性,使之难以达到与一些自然科学学科那样的成熟程度。计量经济学所面临的局限性不是计量经济学本身所特有的,而是整个经济学科所面临的局限性。事实上,正是由于经济系统的非实验性、时变性和不可逆性,以及经济数据的种种缺陷,计量经济学理论本身的发展已相对全面和成熟。但是这种“先进的”实证研究方法,仍无法代替或克服由经济系统和经济数据特点所造成的局限,从而使得计量经济学的分析与预测远没有像多数自然科学学科那样精确。
经济是一个动态系统,不是一个方程式,如果你只把经济当作一系列变量和方程式,而没有看到其深层次结构,那就很容易把噪声当成信号,误认为自己正在做出准确地预测,而实际上你的预测并不准确。大多数计量经济学家做预测时,会在一定程度上依赖自己的判断,而不依据统计模型输出的信息进行预测。考虑到数据杂乱性,这种做法或许是有益的。20世纪七八十年代计算机开始广泛使用时,经济学家普遍认为统计模型能够“解决”经济预测问题。但是,改进的技术无法掩盖对经济领域理论认识的缺乏,只会让经济学家更加迅速且煞费苦心地将噪声误认为信号。看似前景不错的预测模型在某些方面一败涂地,最后惨遭淘汰。
二、大数据时代的思维变革
经济预测者面临着三大基本挑战。第一,单纯依靠经济统计数据(仅依靠结构性数据),很难判断起因与结果。第二,经济是一个动态系统,始终都在变化,某一经济周期的经济运行状况无法被用来解释未来经济的发展。第三,经济学家以往的预测如此糟糕,那么他们作预测时所参照的数据也好不到哪去。以上挑战问题和大数据的特点不谋而合。IBM公司从其特点定义大数据:实时性--大数据是在线的,随时可调用和计算的,这是大数据区别于传统数据的最大特征;多样性--种类、来源多样化,包括结构化、半结构化和非结构化数据;规模性--数据量大,包括数据的采集、存储和计算的量都非常大。之后业界又加了两个特点:价值性--大数据作为新的生产力,创造价值;速度快时效高--增长和处理速度快,时效要求也高。如此一来,大数据又在哪些方面给计量经济学带来影响和冲击呢?
(一)数据
1.数据的采集
大数据是以移动终端、物联网、互联网等移动或者固定设备为依托而产生的非结构化、半结构化以及结构化数据的总和。几乎每个经济体,每时每刻都在生产数据,虽说大数据技术的意义不在于掌握规模庞大的数据信息,而在于对这些数据进行智能处理,从中分析和挖掘出有价值的信息,但前提是拥有大量数据。古人云:“巧妇难为无米之炊”,所以数据采集是为大数据价值挖掘创造条件,是大数据价值挖掘的基础。
数据采集的方式多样化:不论是移动的还是固定设备,要进行数据的采集都直接或者间接的和传感器相关。它更多地赋予设备智能化。传感器的可集成性、多样性、准确性等特点使得数据的采集变得方便、快捷、准确。目前世界最小的晶体管2nm[7].2nm的研发成功对于芯片市场来说绝对是个令人振奋的成果,如果该晶体管真正量产并广泛使用,将会极大地提高芯片的性能。到时科技将赋予传感器更多、更全的功能,传感器的精确度也会有质的飞跃。2nm绝对不是极限,科技的飞速发展和进步--数据采集的方法和手段的革新,也将更好地帮助人类去获取更加及时、准确和多样的数据。
2.大数据的挖掘
只有“米”没有“巧妇”,也不会有可口的饭菜。如此一来,自然诞生了下一个产业链:数据挖掘。数据挖掘赋予了大数据“智能”生命。有了数据仓库为依托,数据挖掘如虎添翼,就如“巧妇”进入了“米仓”.
数据挖掘指通过一定的计算机算法对大量数据进行数据分析,进而解释大数据背后隐藏的趋势、模式和关系,为决策者提供依据,创造价值。之所以称作“挖掘”,就比如在苍茫大地中开矿掘金一样困难。数据挖掘的主要目的:一是去发现埋藏在大数据表面下的历史规律,即对历史描述性分析;二是对未来进行预测,即预测性分析。数据挖掘把数据分析的范围从“已知”到“未知”,从“过去”到“未来”,是商务智能的真正的生命力和“灵魂”所在。它的成熟与发展,最终推动商务智能在各行各业的广泛应用。
多维度数据分析法作为大数据挖掘的基本方法,它主要通过对数据的汇总、对比、交叉、趋势分析等途径,获取有价值的信息。数据分析的多维度不仅弥补了独立维度进行分析所难得发现的一些问题--不同维度之间的相关关系,通过多维度之间的比较、细分,使得分析结果更有意义,还赋予大数据更多的价值。
计算机数据处理的优点:计算速度快;不会犯错,除非编程时就编入错误;不会偷懒,在分析招数、分析可能位置时不会半途而废;不存在偏见,不带感情色彩,不会赢了一步过度自信以致失去胜势,或是遇到困局而沮丧。互联网的数据采集优点:数据的采集实现实时性,不掺杂个人感情和偏见;采集到的数据形式多样化;原始数据可依据个人需要随意提取。计算机和互联网的以上优点也给大数据弥补计量经济学的局限和成就计量经济学带来了可乘之机。
(二)大数据分析
1.大数据预测追求混杂性而非精确性
计量经济学研究经常根据所研究的内容事先提出多个前提假设,在假设的基础上,应用数学模型进行统计检验验证假设。经济学学者在收集样本的时候应用一整套的方法减少错误发生的概率。在统计检验之前,他们也会检测样本是否存在潜在的系统性偏差。这些规避错误的手段无不在美化结果。一味地追求“精确性”,无时不在驱使着统计计量学家去挖掘更加“智能”的算法系统。
大数据更多的用概率说话,不再追求“精确性”,转而追求数据维度的集合--混杂性。大数据不仅要求计量经济学预测不再追求精确性,伴随数据维度和组合越来越丰富,也使得他们无法实现精确性。
错误不是大数据所特有的,但是也是大数据无法消除的,且可能长期存在的。如果计量经济学试图扩大数据的维度,获得大数据带来的价值,大数据就要求计量经济学包容和接受“混杂性”和不确定性。混杂是标准途径,而不应当是计量经济学所竭力避免的。大数据要求计量经济学学者重新审视精确性的优劣,尝试追求数据的完备性和混杂性,进而实现范式转移。
据估计,只有5%的数字数据是结构化的且能适用于传统数据库,如果不接受混杂性,剩下95%的半结构化和非结构化数据都无法被利用,比如网页和视频资源。通过接受大数据非精确性,我们就会打开一个从未涉及的经济之窗。
2.大数据预测:样本=总体
传统计量经济学研究一直停留在小数据时代,对于新生事物是不敏感的,必须等事情发生并且成长到一定规模以后才能搜集到足够数据进行相关研究。在计量经济学理论研究中,因为分析、记录和存储数据的工具不够好,加之数据搜集条件和数据处理能力等方面的影响,只能应用少量数据“说话”.计量经济学家们认为:样本分析的精确性随着采样随机性的增加而大幅度提高,与样本数量的增加关系不大,即样本选择的随机性比样本数量更重要,退一步讲,当然这种观点颇有建树,通过搜集样本,用较少的花费做出高精确度的判断,虽然样本分析取得了巨大成功,成为当代测量领域的中流砥柱。但是这只不过是条捷径,是在无可奈何(搜集和分析数据等困难的束缚)的情况下的迫不得已。样本采集的过程中难免掺杂个人感情,加之经济学学者往往还要对采集到的数据进行二次处理,研究结果多被采样的质量绑架,大大降低了研究成果的质量。结论往往诞生在结果之前,也不免使得结论价值大打折扣。
在经济活动中真正有趣的事情往往藏匿在细节中,这是样本分析法难以捕捉的--如啤酒与尿布的相关关系。在大数据时代,利用所有的数据,而不再仅仅局限于依靠小部分结构性数据,拓展了计量经济学的研究范围。采集数据的方式多样化,拥有先进的技术手段对大规模数据快速处理,且数据的采集具有实时性,可以更加快捷地通过分析全体数据对经济行为进行研究,一旦有新情况、新动态立即予以关注,及时对事前政策做出适应性调整和指导未来政策的走向,从而实现对新生事物的早期干预和分析,因此具有前瞻性。大数据本身就具有智能,可以辅助计量经济学发现知识。麻省理工学院(MIT)的两位经济学家,阿尔贝托·卡瓦罗和罗伯托·里哥本通过一个软件在互联网上搜集信息,他们每天可以搜集到50万种商品的价格。收集到的数据很混乱,也不是所有数据都能轻易进行比较。但是把大数据和好的分析法相结合,这个项目在2008年9月雷曼兄弟破产之后马上就发现了通货紧缩趋势,然而那些依赖官方数据的人直到11月才知道这种情况。
三、大数据和计量经济学的融合
计量经济学是被“样本=总体”撼动的最厉害的经济学分支学科之一,伴随大数据分析取代样本分析,计量经济学不再单纯地依靠实证数据分析。虽说统计抽样在经济学界固若金汤,但统计抽样只是为了在被技术限制的特定时期,解决存在问题的被动选择。现如今,技术已不是阻止大数据的最大障碍,当然在特定条件下统计抽样方法依然可用。大数据拓展了计量经济学的研究范围,可增加计量经济学研究的实用性,数据的实时性也可增加计量经济学预测的准确性。
大数据所涉及的资料已远远超出一般的计量经济学分析所能处理的范畴,大数据分析法的出现给计量经济学研究提供了更大的空间、更新的视角,也给以往计量经济学“难以研究”或者“不可研究”的经济领域--如商业中啤酒和尿布的关系,注入了新的原动力;大数据分析法并非是传统计量经济学家通过思考、领悟、观察、建模等方法的分析而获取结论的,而是通过大数据的汇集和不同数据维度的组合、交叉,运用计算机技术和大数据思维处理得来的;大数据构建了丰富且可持续完善的数据集和分析工具,其共享性、协调性、重用性等大大增强,这些都为大数据与计量经济学的融合提供条件;大数据汇集专业领域的数据采集、数据处理、数据维护等专业团队,也为与计量经济学的融合提供了必备条件。以上所有的理由都表明:大数据和计量经济学融合有其天然的优势,同时也是大势所趋。
计算机速度非常快,而且它可以非常踏实衷心地计算--不知疲倦、不带感情、不会中途改变分析方式。但这并不意味着电脑做出的预测就一定很完美或者很准确。若给计算机输入错误的数据,或提供一套愚蠢的指令供其分析,它不可能“变废为宝”.此外,计算机也不善于完成需要创造性和想象力的任务,比如为这个世界的运转方式设计策略或提出理论。
因此,大数据和计量经济学的珠联璧合显得尤为重要。未来大数据计量经济学的研究,不仅仅需要大数据、云计算的技术支持,还要有第三方大数据处理机构--大数据算法师、大数据建模师、大数据维护师等,计量经济学家也是不可或缺的。未来计量经济学家、大数据拥有者、大数据处理机构共同构造大数据计量经济学的“价值链”,使得计量经济学更接地气,创造更大的经济价值。大数据时代,我们将见证大数据计量经济学腾飞。
四、思考与总结
经济预测和经济政策之间的界限十分模糊,一个不准确的预测可能会使现实中的经济状况变得更糟。大数据应用全体数据分析二维或多维数据的相关性,而不是分析少量数据样本;大数据对纷繁混杂的数据选择了包容,而不再一味地去追求精确性;大数据不再追寻经济行为之间的因果关系,转而用相关关系挖掘经济行为之间的联系。这些给计量经济学研究带来的好处就是:大数据量化经济风险,减弱了经济行为中因信息不确定性带来的逆向选择和道德风险;大数据提供计量经济学更大的探寻历史、追寻未来的空间;传统计量经济理论多为“纸上谈兵”,大数据给传统计量经济学带来新转机,使得经济理论预测和现实经济行为贴合度更高。种种迹象表明大数据和计量经济学融合必将结出丰厚的果实。未来可能诞生大数据计量经济学派。
然而所有数据只代表过去,所以有时你会听说,抛开数据的原因之一就是,你正在试图解决的问题发生了根本性的转变。经济不是网球,网球比赛总是遵循同样的规则,而经济规则不会一成不变。问题是你永远都不会知道下一个转变什么时候会出现,也不会知道这个转变会使经济变得更加波动还是更加平稳,更加强大还是更加脆弱。如果一个经济模型是建立在“没什么大变化”的前提条件之上,那么这个经济模型就毫无价值可言。但是,预测这些转折点的出现实非易事。
任何预测模型的目标都是尽可能地“抓住信号、扫除噪声”.保持两者的平衡有时并非易事,需要有理论依据和保质保量的数据作保证。在经济预测时,数据贫乏,理论研究薄弱,所以有人认为“经济模型越复杂,预测越糟糕”.这句话就是告诫人们,“不要在食谱中加入过多的盐”[2].虽说大数据拥有足量的数据和技术,但可以肯定地说大数据不是经济预测的“圣杯”,但这不能否定大数据拥有提高经济预测准确度的能力。
参考文献:
[1]ARIS SPANOS.Probability Theory and Statistical Inference: Econometric Modeling with Observation-al Data[M].Cambridge University,United Kingdom,1999,p.21.
[2]M.G.KENDALL and A.STUART.The Advanced Theory of Statistics[M].Charles Griffin Publishers,New York,vol.2,1961,chap. 26,p.279.
[3]达摩达尔。N.古扎拉蒂,唐。C.波特。 计量经济学基础(上册)[M].北京:中国人民大学出版社,2011:20-21.
[4]MILTON FRIEDMAN.Essays in Positive Economics[M].University of Chicago Press,Chicago,1953:14.
[5]MARK BLAUG.The Methodology of Economics:Or How Economists Explain,2d ed[M].CambridgeUniversity Press,New York,1992:92.
[6]维克托·迈尔·舍恩伯格,肯尼斯·库克耶着。大数据时代--生活、工作与思维的大变革[M].盛杨燕、周涛,译。杭州:浙江人民出版社,2012:27-94.

1980年10月15日,由瑞典皇家科学院宣布,授予劳伦斯克莱因诺贝尔经济学奖金,从而表彰他在创造计量经济学模型将该模型用于经济波动分析和经济政策方面的贡献。他是当代西方经济学流派中着名的经济计量学家。计量经济学是经济学的一个分支。计...

电力产业作为国民经济的基础产业,是中国能源的重要组成部分。电力能源的发展可满足人民生活需要,保持经济可持续发展,对社会的进步至关重要。...

一、建立模型设计量经济模型为:=+++++式中,为第t年全国国内旅游收入(亿元);为国内旅游人数(万人/次);为城镇居民人均旅游支出(元);为农村居民人均旅游支出(元)为铁路里程(万公里),解释变量前的系数均为正。为估计参数...

计量经济学专业专业是以经济计量模型为主要手段,以模型来定量分析研究具有随机性特性的经济变量关系的学科....
题目:常见计量经济软件的回归分析方法研究摘要(详见正文)1Eviews、Excel、spss的简介1.1Eviews简介1.2Spss简介1.3EXCEL简介2案例分析2.1用EXCEL对案例进行线性回归分析2.2用EVIEWS对案例进行线性回归分析2.3用SPSS对案例进行线性回归分...

本文研究中国经济增长的空间计量经济相关内容,探究经济学分析准备工作,包括指标选择和数据来源,探究分析经济变量之间的空间相关性,讨论残性方差回归模型、空间滞位模型、经济拐点三种方法分析中国经济增长的特点和情况...

党的十九大报告强调创新是引领发展的第一动力, 技术市场是国家创新驱动发展战略中的重要组成部分, 技术市场是技术产品实现从科研成果到生产要素转化的重要路径。...

央行作为我国政府调控经济的主要机构, 把握中国经济的发展实际情况, 采用相应的货币和财政政策对经济进行调控, 以适应经济形势的变动...
计量经济学分为理论计量经济学和应用计量经济学。理论计量经济学是随机性地对经济变量的做理论上的研究,对统计资料进行分析,找到对经济变量进行计量的方法。而应用计量经济学是在理论计量经济学的指导下,研究计量经济学的模型在各方面的应用。二者各有侧...

大数据时代, 计量经济学课程对经济、管理和统计学科专业本科生能力培养的作用越来越显著。有关计量经济学教学的研究中, 李子奈[1]认为, 我们当前的任务是加强理论研究并提高应用研究的水平。...