博士论文写作

10 月 27 日至 11 月 2 日,两年一届的 ICCV 2019 来到韩国首尔,选址 COEX 会展中心举行。严谨且严肃的国际顶级学术会议与充满着热情与活力的首尔将在这个枫叶开得正红的季节碰撞出怎样的火花呢?这里带大家一起看!
ICCV 的全称是 IEEE International Conference on Computer Vision,即国际计算机视觉大会,由IEEE主办,与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并称计算机视觉方向的三大顶级会议,被澳大利亚ICT学术会议排名和中国计算机学会等机构评为最高级别学术会议,在业内具有极高的评价。ICCV论文录用率非常低,是三大会议中公认级别最高的。
29 日,经过 2 天 Workshop 和 Tutorial 的前期预热和酝酿,ICCV 2019 开幕式在笼罩着一片温煦秋阳的清晨如期而至。

开幕式开始前,几位主席在台上合影
韩国时间八点四十五一到,ICCV 2019 四位大会主席(General Chair)之一、首尔大学(Seoul National University)教授 Kyoung Mu Lee 上台宣布会议开幕并进行开幕致辞。他首先逐一介绍并感谢了包括其它大会主席、程序主席,并向其他各领域的主席们致谢。
说到中途,他话锋一转向台下各位寒暄到「这几天首尔是不是很冷?」台下一片掌声和欢笑声后,他接着简单介绍了本次 ICCV 的整体数据。正如之前所报道的,今年 ICCV 共收到 4303 篇投稿,最终收录了 1075 篇,虽然整体数据都有所提高的,但是由于分母--总投稿量的大幅增加,今年收录率为 25%,比去年 28.9% 的收录率要低上不少。

而今年参会人数的数据非常惊人惊讶:人数达 7501 人,比去年增加了 2.41 倍之多!而值得一提的是,今年参会人数中有 2964 位来自韩国,1264 位来自中国,1199 位来自美国以及 260 位来自日本,从这些数据来看,临近国才是最「捧场」的区域所在呀!
虽然 ICCV 的赞助商数量不如今年 CVPR 那么壮观,但数据相比于其他学术顶会而言,也算不错,获得了 56 家企业的赞助以及 72 家展商参展。

论文数据一览:华人论文数量超美国
UIUC 副教授 Svetlana Lazebnik 作为 ICCV 2019 的程序主席之一,随后对今年 ICCV 的论文情况进行了解说。今年的 4303 篇投稿,相比去年增加了一倍,其中参与论文的作者人数达 1 万人;最终接受论文数为 1075 篇,收录比为 25%,其中包括 200 篇 Oral 论文,并且所有 Oral 论文都如 CVPR 2019 一样--都为短论文。
从论文主题来看,最热门的关键词如图所示,排在前几位的依次是 Learning、Image、Network、Deep、3D、Object 等,这也反映了该领域内研究人员们对于各个细分课题的关注程度。

从论文的区域分布来看,今年接收论文数量最多的国家是中国,超过 350 篇,其次是美国、德国、韩国和英国。在这组数据发布前,大家都知道这次华人研究者表现很好,但不知道论文收录数量比美国还多!
而这些论文被收录的背后,同样的也离不开程序委员会的工作。据 Svetlana Lazebnik 介绍,今年除了 4 位程序主席,还安排了 172 位领域主席以及 2506 位审稿人参与论文评审,其中,每位领域主席需要评审的论文为 20 至 30 篇,而 2506 位审稿人有 68% 的研究者或高校教师和 32% 的学生组成,各自需要评审的论文分别最多达 9 篇、5 篇。
各大奖项重磅出炉:以色列理工成最大赢家
紧接着,开幕式迎来了高潮环节--公布奖项!
奖项中最受关注的最佳论文奖(Best Paper Award)、最佳学生论文奖(Best Student Paper Award)、最佳论文提名奖(Best Paper Honorable Mentions)、以及最佳论文一般提名(Best Paper Nomination)继续由 Svetlana Lazebnik 公布。
一、最佳论文奖
1、最佳论文奖(Marr 奖)
本届最佳论文奖(Marr奖)为《SinGAN: Learning a Generative Model from a Single Natural Image》,论文第一作者Tamar Rott Shaham来自以色列理工(Technion):
SinGAN: Learning a Generative Model from a Single Natural ImageSinGAN:从单张自然图像学习生成式模型

作者:Tamar Rott Shaham, Tali Dekel, Tomer Michaeli单位:Technion(以色列理工), Google
论文地址:https://arxiv.org/abs/1905.01164
论文摘要:作者们提出了 SinGAN,这是一个可以从单张自然图像学习的非条件性生成式模型。这个模型可以捕捉给定图像中各个小块内的内在分布,接着就能够生成带有和给定图像中的视觉内容相同的高质量且多样的新图像。SinGAN的结构是多个全卷积GANs组成的金字塔,这些全卷积GANs都负责学习图像中的某个小块中的数据分布,不同的GANs学习的小块的大小不同。


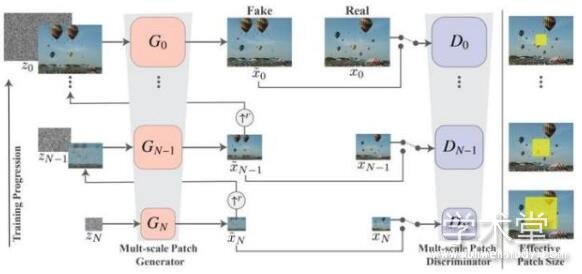
这种设计可以让它生成具有任意大小和比例的新图像,这些新图像在具有给定的训练图像的全局结构和细节纹理的同时,还可以有很高的可变性。与此前的从单张图像学习GAN的研究不同的是,作者们的这个方法不仅仅可以学习图像中的纹理,而且是一个非条件性模型(也就是说它是从噪声生成图像的)。作者们做实验让人分辨原始图像和生成的图像,结果表明很难区分。作者们也在多种图像操控任务中展示了SinGAN的作用。
2、最佳学生论文奖
最佳学生论文的第一作者 Timothy Duff 来自佐治亚理工学院。
PLMP -- Point-Line Minimal Problems in Complete Multi-View VisibilityPLMP -- 多视角完全可见条件下的点-线极小问题研究

作者:Timothy Duff, Kathlén Kohn, Anton Leykin, Tomas Pajdla 单位:Georgia Tech(佐治亚理工学院),KTH(瑞典皇家理工学院),Czech Technical University in Prague(布拉格捷克理工大学)
论文地址:https://arxiv.org/abs/1903.10008
论文摘要:极小问题(minimal problem)指在三维重建过程中根据给定图像反解出摄像头的姿态和世界坐标,而且要求随机给定的输入样本可以得到有限数目的解。在这篇论文中,作者们以观察者相机经过矫正、图中一般的点和线全部可见为条件,对所有的极小问题进行了分类。
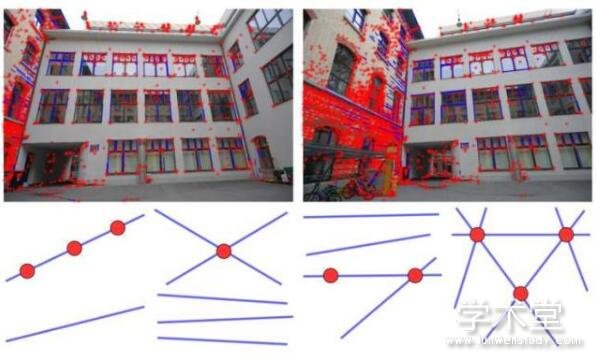
作者们表明,极小问题一共只有30种,对于有超过6个相机、或者超过5个点、超过6条线的情况,极小问题都是可解的。作者们进行了一系列检测极小性的测试,从对自由度计数开始,最终对有代表性的样本进行了完整的符号和数值验证。对于所有发现的极小问题,作者们都给出了它们的代数度数,即解的数目,这也是问题的本征难度的衡量指标;从这里可以看出随着视角数目的增加,问题的难度是如何变化的。一个重要的点是,一些新出现的极小问题其实只有很小的代数度数,这意味着它们可以在图像匹配和三维重建任务中得到实际应用。
3、最佳论文荣誉提名(Best paper Honorable Mentions)
共有两篇论文被荣誉提名,如下:
最佳论文荣誉提名 1
Asynchronous Single-Photon 3D Imaging非同步单光子3D成像

作者:Anant Gupta, Atul Ingle, Mohit Gupta单位:University of Wisconsin-Madison(威斯康星大学麦迪逊分校)
论文地址:https://arxiv.org/abs/1908.06372
论文摘要:单光子雪崩二极管(SPAD)在基于飞行时间(time-of-flight)的深度测量中得到了越来越多的应用,因为它们具有以皮秒精度捕捉单个光子的独特能力。不过,环境光照(比如阳光)会对基于SPAD的3D相机产生干扰,给捕捉到的波形带来严重的非线性失真(连续命中),总而造成深度测量错误。作者们在论文中提出了新的非同步式单光子3D成像,这是一类可以缓解光子捕捉过程中的连续命中问题的新的捕捉模式。非同步捕捉捕捉模式会根据预定义的、或者随机设定的偏移量,故意短期错过激光发射到SPAD测量的时间窗口。
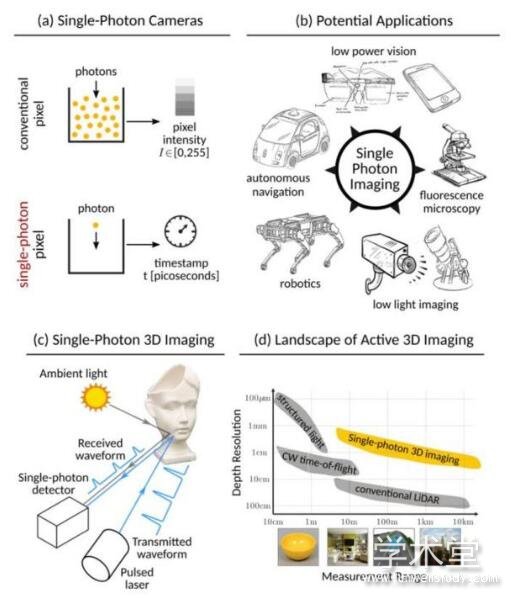
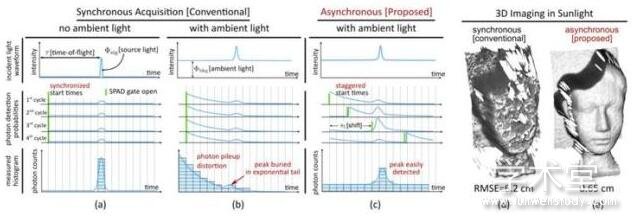
作者们这样做的考虑是,如果选择一系列时间窗口的偏移量,让这些偏移量可以对应全部的测量深度,那么他们就可以根据没有发射激光的时候收集到的信号(看作本底噪声)把正常采集信号中的干扰部分抵消掉。作者们开发了一个通用的图像成像模型,并进行了理论分析,探索非同步采集模式的各种可能的做法,并找到具有很好表现的模式。作者们的仿真实验和实际实验都表明了他们的方法相比于当前最优秀的方法可以在各种成像条件下(尤其是具有强烈环境光照的)都带来深度检测精度提升,最高可以提升一个数量级。
最佳论文荣誉提名 2
Specifying Object Attributes and Relations in Interactive Scene Generation从交互性的场景生成中指定物体属性和关系

作者:Oron Ashual, Lior Wolf单位:Tel-Aviv University(以色列特拉维夫大学)
论文地址:https://arxiv.org/abs/1909.05379
论文摘要:作者们提出了一种从场景图(scene graph)输入生成图像的方法。这个方法会分别生成一个布局嵌入和一个外观嵌入。在两个嵌入的共同作用下,生成的图像可以更好地匹配输入的场景图,有更高的视觉质量,而且能支持更复杂的场景图。
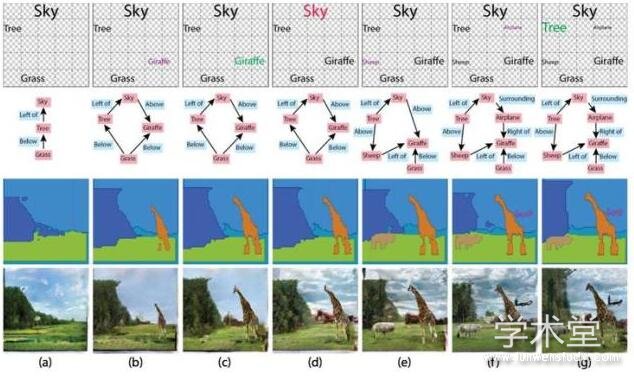
除此之外,这个嵌入方法支持为同一个场景图生成多个不同的输出图像,用户也能控制这个生成过程。作者们展示了两种控制图像中的物体的方法:1,参照其他的图像中的元素;2,在物体空间中导览,找到外观原型。作者们把代码开源在了 http://github.com/ashual/scene_generation.
4、最佳论文提名
本届最佳论文提名共有 7 篇文章,其中仅有两篇一作为华人,其一是来自中山大学的Ruijia Xu,另一位则是斯坦福大学的Chengxu Zhuang.当然何恺明团队也获得了提名。

最佳论文一般提名1:
Larger Norm More Transferable: An Adaptive Feature Norm Approach for Unsupervised Domain Adaptation更大的常态有更好的可迁移性:用于无监督领域适应的一种自适应特征常态方法
作者:Ruijia Xu, Guanbin Li, Jihan Yang, Liang Lin
单位:Sun Yat-sen University(中山大学)、DarkMatter AI Research
链接:https://arxiv.org/abs/1811.07456
最佳论文一般提名 2:
Deep Hough Voting for 3D Object Detection in Point Clouds用于点云中的三维物体检测的深度Hough投票方法
作者:Charles R. Qi, Or Litany, Kaiming He(何恺明), Leonidas J. Guibas单位:Facebook AI Research,Stanford University
链接:https://arxiv.org/abs/1904.09664
最佳论文一般提名 3:
Unsupervised Deep Learning for Structured Shape Matching用于结构形状匹配的无监督深度学习方法
作者:Jean-Michel Roufosse, Abhishek Sharma, Maks Ovsjanikov单位:LIX,Ecole Polytechnique(巴黎综合理工大学)
链接:https://arxiv.org/abs/1812.03794
最佳论文一般提名 4:
Gated2Depth: Real-time Dense Lidar from Gated ImagesGated2Depth:从门图像实时生成雷达质量的密度图像
作者:Tobias Gruber, Frank Julca-Aguilar, Mario Bijelic, Werner Ritter, Klaus Dietmayer, Felix Heide 单位:Daimler AG(戴姆勒), Algolux, Ulm University(德国乌尔姆大学), Princeton University
链接:https://arxiv.org/abs/1902.04997
最佳论文一般提名 5:
Local Aggregation for Unsupervised Learning of Visual Embeddings视觉嵌入中无监督学习的局部聚合
作者:Chengxu Zhuang, Alex Lin Zhai, Daniel Yamins单位:Stanford University
链接:https://arxiv.org/abs/1903.12355
最佳论文一般提名 6:
Habitat: A Platform for Embodied AI ResearchHabitat:一个实体AI研究平台
作者:Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, Dhruv Batra单位:Facebook AI Research, Facebook Reality Labs, Georgia Institute of Technology, Simon Fraser University, Intel Labs, UC Berkeley
链接:https://arxiv.org/abs/1904.01201
最佳论文一般提名 7:
Robust Change Captioning鲁棒的场景变化说明
作者:Dong Huk Park, Trevor Darrell, Anna RohrbachUniversity of California, Berkeley
链接:https://arxiv.org/abs/1901.02527
二、PAMI TC 奖项
这几项重磅奖项揭晓后,PAMI 服务主席 Bryan Morse 上台颁布四大 PAMI TC 奖项,包括 Helmholtz 奖、Everingham 奖、Azriel Rosenfeld 终身成就奖以及杰出研究者奖。
1、Helmholtz Prize
该奖项以 19 世纪物理学家赫尔曼·冯·赫姆霍兹(Hermann von Helmholtz)命名,每两年颁发一次,旨在表彰在计算机视觉领域做出的基础性贡献,且只颁发给 10 年前在 ICCV 上发表且产生重大影响的论文。本届共有两篇发表于 2009 年的论文入选,分别为:
1)Building Rome in a Day(华盛顿大学)
2)Attribute and Simile Classifiers for Face Verification(哥伦比亚大学)
2、Everingham Prize
该奖项用来纪念 Mark Everingham,并鼓励其他研究者和他一样推动整个计算机视觉领域的进步。这个奖会颁发给一位研究人员,或者是一个研究团队;评奖标准是,他们为计算机视觉大家庭中的别的成员作出了重大的、无私的贡献。这次也颁发了两个奖。
第一个奖颁发给了单个研究员,获奖者是 Gerard Medioni
颁奖词:他在过去的几十年中为 CVPR 和 ICCV 会议的组织提供了充分的、持续的帮助,还为整个 CV 大家庭提供了很多其它的服务。除此之外,他设计了会议和 workshop 使用的统一护照注册系统,还是计算机视觉基金会 CVF 的联合创始人之一。
第二个奖项颁发给了 2007 年提出了 LFW 人脸识别数据集,并在此后举办 LFW 人脸识别比赛并持续维护的团队。LFW 数据集帮助整个领域向着更缺乏条件控制的、更面向真实世界情境的人脸识别技术进行研究。
3、Azriel Rosenfeld 终身成就奖
Azriel Rosenfeld 终身成就奖是在里约热内卢举办的 ICCV 2007 上设立的,以表彰那些在长期职业生涯中对计算机视觉领域做出了杰出贡献的研究人员。该奖章以纪念已故的计算机科学家和数学家教授 Azriel Rosenfeld.
本届获奖者为以色列魏兹曼科学研究所(Weizmann Institute of Science, Israel)的 Shimon Ullman 教授。
Ullman 出生于 1948 年,并于 1977 年在 MIT 获得博士学位,师从计算机视觉之父 David Marr.其主要研究领域为人与机器视觉处理的研究。具体来说,他专注于物体和面部识别,并在该领域取得了许多重要见解,包括与 Christof Koch 一起在哺乳动物视觉系统中建立了视觉显着图,以调节选择性的空间注意力。
4、杰出研究者奖(Distinguished Researcher Award)
杰出研究者奖(Distinguished Researcher Award)授予 MIT 的 William T. Freeman 与哥伦比亚大学的 Shree Nayar 两人。
William T.Freeman 现就职于 MIT.研究领域包括应用于 CV 的 ML、可视化感知的贝叶斯模型、计算摄影学等。其最有影响力的研究成果是与 Alex Efros 在 2001 年 SIGGRAPH 上发表了」Image quilting for texture synthesis and transfer」,其思想是从已知图像中获得小块,然后将这些小块拼接 mosaic 一起,形成新的图像。该算法也是图像纹理合成中经典中的经典。
Shree Nayar 现就职于哥伦比亚大学。其研究领域主要在新型相机的创建、基于物理的视觉模型和图像理解算法。Nayar 曾提出了计算摄影学的概念,也是计算摄影领域的先驱人物。曾于 1990 年和 1995 年先后获得两次 Marr 奖,是当时计算机视觉领域炙手可热的青年学者之一。
最后,Kyoung Mu Lee 再次站上舞台专程为各参会者介绍了一份「官方参会指南」,包括整个会场的分布情况、社交活动、注意事项,乃至于去哪里用餐、如何连接 WIFI 等等事宜,让人倍感温暖。
总结
在会议召开之前,随着华人学者在 ICCV 2019 再度取得的一系列傲人成绩的相关消息相继出炉,各位关注 ICCV 动态的同学们想必也对今年将于中国邻国--韩国召开的 ICCV 2019 充满了期待。而本次会议中,无论是在各大议程和竞赛中频频刷脸的华人面孔,还是张贴在展厅各个角落的写着华人作者姓名的 poster,更是让今年在异国参会的华人研究者们在心底涌流着一股浓浓的自豪感。记者站在人潮如流的参会人群中,也切身地感受着这一切。
然而,在与去年「何恺明包揽全部两项最佳论文奖」光环的比照下,今年华人在奖项上的表现略显惨淡:除了中山大学的《Larger Norm More Transferable: An Adaptive Feature Norm Approach for Unsupervised Domain Adaptation》和何恺明参与的一篇论文《Deep Hough Voting for 3D Object Detection in Point Clouds》入选最佳论文一般提名,其他获奖者都为非华人学者。这也给所有参加会议的华人学者心中留下了些许的遗憾。
接下来,还将在现场与一系列计算机视觉领域的大佬级研究者进行交流,例如今年 CVPR 最佳学生论文一作王鑫,去年包揽大会全部两项 Best Paper Award 的何恺明,以及颜水成、孙剑、林达华、程明明、卢湖川等一众大家熟悉的「老面孔」们,为大家带来特别报道,请大家持续关注!