硕士论文写作

一篇名副其实的论文,至少要有作者自己提出的有新意的论点。而新论点不外乎是对两种现象或因素之间的关系作出的一种判断,这种判断是以往文献未曾出现过的,读者会从中受到启发。数据分析是新论点论证过程的必要环节,其基本工作内容是分析两变量(自变量和因变量)之间的关联状况,包括判断两变量间是否存在关联,一个变量变化时,另一个变量是否也随之变化,以及这种关联的趋向和强度如何。
通常采用相关系数来表征变量间的关系强度。最强的相关是完全相关,一个变量发生变化时,另一变量随之确定地发生某种变化。一个变量发生变化时,另一变量不发生变化,则不相关。两变量间的关联趋势可以是正也可是负,可以是线性也可是非线性的。正相关表示变量数值朝同方向变化,同增或同减,如果一个变量增加另一个变量减少则称为负相关,两变量增减量的比例保持不变为线性相关,非线性相关则指两变量的变化趋势和强度在不同阶段不一致一或 者部分阶段为正相关,部分阶段为负相关;或者都是正相关或负相关,但强度前后不一致。
变量间关联状况分析,一般分为三个步骤。 首先,根据变量尺度类型算出反映关联程度的相关系数。其次,根据算出的相关系数,判断两变量间是否存在统计意义上的相关关系。最后,对两变量间存在的相关关系作出判断。
一、定类变量的相关系数
不同尺度类型的变量有不同形式的相关系数。对于定类尺度的变量如性别、职业、行业等,采用指标λ来测度变量间的相关程度,λ与其他反映相关程度的指标一样,是基于误差消减比例( proportional reduction of error, PRE) 的思路,即引人另一个变量的属性数据后,某个变量预测值的误差会减少一定的比例,算式表示为:
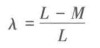
式中,L为预测失败的次数;
M为引人某自变量后,预测失败的次数。
算例 如某单位民意测验选拔领导, 有候选人甲、乙、丙,该单位有四个部门I、II、III、IV,共1 560人对候选人表态,表5-9列出各部门对各候选人的支持人数,现要判断候选人和“部门”的相关状况。
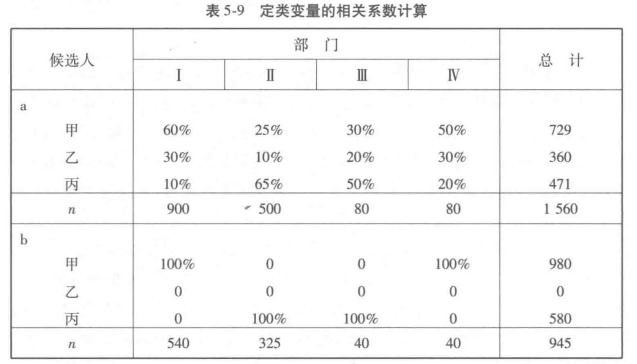
从表5-9a看出,按照民意测验的支持票数,甲得票数最多,共729票,预测甲将胜出。这样的预测意味着存在预测失败的次数,即乙丙得票数,为1 560-729 =831。当引人“部门”变量后,分别按部门来预测胜选者,预测结果会有变化,甲在部门I和IV以60%和50%胜出,丙则在II、III 部门领先(表 5-9b)。这时预测正确率增加,如部门I ,原来预测正确的次数为500x0.25= 125,现为500x0. 65 = 325,预测正确次数为( 540+325+40+40)= 945 ,而预测失败次数为1 560-945=615。 可见,引入“部门”这个变量后,预测失败次数由L=831减少到M=615,自变量“部门”和作为因变量的候选人之间的相关系数λ计算如下。
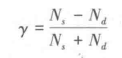
如果部门I、IV有100%的人数选甲,部门II、III 有100%人数选丙,如分别按部门预测甲、丙胜出,便不会出现预测失败的情况,此时预测失败次数为零,λ=1。定类尺度没有次序,也就无所谓正相关或负相关,λ无正负号之分。
二、定序变量的相关系数
管理研究中常遇到定序变量之间的相关关系分析,大学排名榜或企业竞争力排名就有这类分析问题。人们关注大学排序名次与哪些因素关联密切,是论文发表数、科研经费还是博士生规模等,这时须运用相关分析。定序变量间相关状况的度量指标设计,同样是基于误差比例消减的思路,不同的是,上述定类数据所用的相关系数λ,分析的是正确和错误判断的次数,而定序数据的相关系数指标为y,计算时要分析正确和错误的次序,算式表示为:
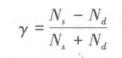
式中,Ns为同序对数目;
Nd为异序对数目。
分子越大,说明误差比例消减越多,两变量之间相关性越强。
设有两个分析对象甲和乙,并按两个变量的属性排序,如分析对象甲按两个变量排序都高于或低于乙,称之为同序对;异序对则指分析对象甲,按一个变量排序时高于(低于)乙,而按另一变量排序时则低于(高于)乙。若分析的对象总数为N,则一共可组成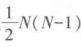 对级序。
对级序。
算例 表5-10 的分析对象为5个应聘人员,应有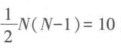 对级序,其中AC、AD、AE、BC、BD、BE、CD、CE为同序对,其余两对AB、DE为异序对,Ns=8,Nd=2。
对级序,其中AC、AD、AE、BC、BD、BE、CD、CE为同序对,其余两对AB、DE为异序对,Ns=8,Nd=2。

于是,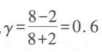 相关系数为0.6说明笔试成绩和录取排名正相关,笔试成绩靠前的,很可能录取排名也在前。
相关系数为0.6说明笔试成绩和录取排名正相关,笔试成绩靠前的,很可能录取排名也在前。
三、定距、定比变量的相关系数
两个变量的取值都是定距或定比数据时,采用最常见的相关系数r测量变量间关联强度。
相关系数表示两变量相关程度,其值在0和+1.00或0和-1.00之间。如以两门课程成绩为变量,学生甲课程A考高分,课程B也是高分,反之,课程A考低分,课程B也低分,这种情况表示正相关,两课程成绩的相关系数接近+1.00。相关系数接近-1.00则表示课程A高分,课程B为低分,一个变量增加,另一变量减少。相关系数-1.00和+1.00表示同样的关联强度,只是趋势不同。相关系数为0,表示两变量间不相关,课程A的成绩对课程B的成绩没有任何预示作用。
表5-11是10位管理人员4项指标的测试分数:业务能力、绩效、体重和笔试20题中答错的题数。从观察对比表中的数据可以直观看出,业务能力与绩效两列数据变异趋势相同,业务能力测试分数高,绩效分亦高,两者变异趋势呈现正相关。正相关并非说不存在其他影响业务能力的因素,如情商等因素也可能与绩效相关。不能认为绩效完全是由业务能力决定的,只能说业务能力是引起绩效变异的一个主要关联因素。表中的业务能力分数对于体重的变异看不出任何趋势,说明业务能力测试分数与体重不相关。业务能力、绩效分数与答错题数是负相关,能力分数增加,可推测出答错题数减少,两者呈负相关。绩效与业务能力类似,绩效分越高,答错题数越少,两者呈负相关。
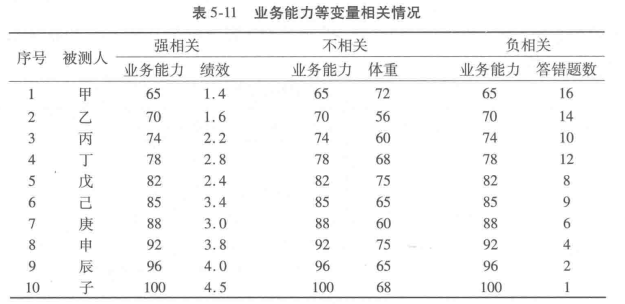
相关系数的含义可以这样通俗地理解:相关系数的平方标志着两变量协同变异的比重。协同变异指一个变量变化另一变量也相应地按一定比例变化。如两变量不相关,一组变量值的变化与另一组变量值的变化状况毫无关联,两者之间协同变异的部分为零。如果完全相关,即相关系数为1,则两变量的两列数据之间,百分之百地都是按同一趋势同一幅度变异。表5-11的业务能力与业绩两列数字,虽是强相关,变异趋势也有不一致之处,如4、5项的变异趋势,戊的业务能力分比丁高4分(82 ,78) ,业绩分却低0.4(2.4,2.8),而其他各项都符合业务能力分高,业绩分亦高的趋势。同时,即使趋势相同,变异幅度也不一样,以前三项来说,乙比甲的业务能力多5分,业绩分提高0.2(1.6,1.4),而丙比乙业务能力多4分,业绩分却提高0.6(2.2,1.6)。这些趋势和变异幅度的不同,都说明两变量间的不协同变异。这些不协同变异在两列数据间占的比重越大,相关系数越小。统计分析中两变量完全按同一趋势同一幅度变异,即相关系数为1的情况很少,一般都会有不协同变异的部分。
两变量协同变异部分的比重并不等于相关系数,它通常小于相关系数值,相关系数的平方值才是协同变异部分。如相关系数为0.8,表示协同变异的程度有64%,相关系数0.5看似相关程度不低,实际上协同变异的程度只有25%。
表5-11所列数据,如用点图来表示,两变量间的相关情况可以看得更清楚。
横纵坐标各表示一变量的值, 一组数据构成图上一个点。如相关系数为1,则所有观测数据将连成直线,如相关系数为0,所有观测数据将成圆团状。相关系数小于1越多,则游离于直线之外的观测点越远、越多。所以在研究工作中常用点图来初步判断两变量间相关关系的趋势和强弱。
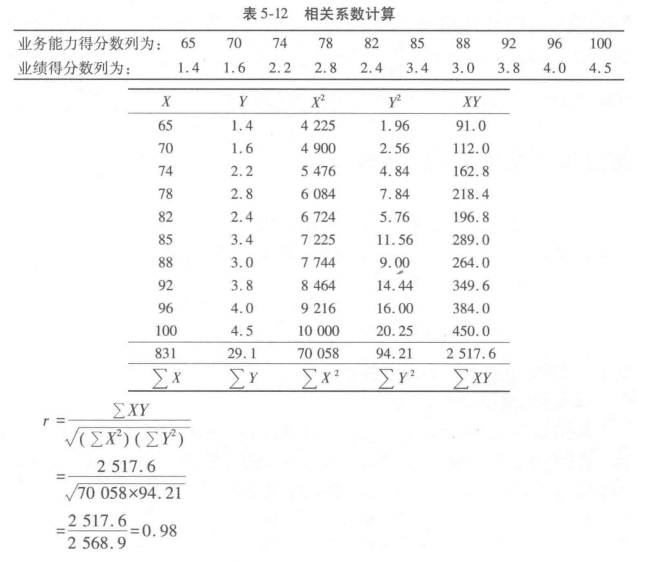
定距和定比变量的相关系数,即常用的皮尔逊相关系数r,可由公式算出,下面按表5-11所示的数据,计算业务能力与业绩两变量强相关算出的相关系数r=0.98。计算过程参见表5-12。
四、定类和定比变量的相关系数
管理研究中还可能碰到一种情况,自变量为定类数据,因变量为定比或定距数据,如性别对捐赠额的影响,某项政策对居民收人的影响等。男、女属性或两种政策都属于定类数据,而捐赠额和收入均属于定比数据,在这种情况下,可先按自变量的属性将因变量数据分类,分类后的状况不外乎两种,一种是两类数据无明显差异,一种是有明显变化,说明自、因变量之间存在相关。
对于这类变量间关联判断采用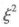 , 它的含义与其他关联指标类似,表示数据按自变量分类后总体误差的减少程度。
, 它的含义与其他关联指标类似,表示数据按自变量分类后总体误差的减少程度。

算例 设自变量为性别,因变量为捐赠额。10个样本中,5位男性捐赠额分别为10,10,15,15,20,得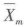 。 该值表示因变量60%的变异可以由自变量来解释,这表示捐赠额与性别有较强程度相关。
。 该值表示因变量60%的变异可以由自变量来解释,这表示捐赠额与性别有较强程度相关。
五、定序和定比变量的相关系数
一个定序变量,另一变量系定距或定比数据,两种序列之间的相关情况,也是常遇到的问题。这时,可将定距或定比数据转换成定序数据,并用斯皮尔曼系数(Spearman's rho)来表示相关程度。
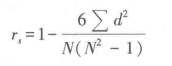
式中,d为两组数据排序序号数值的差异;
N为两组数据成对的数量。
表5-13a是人员招聘的数据,包括6名候选人的业务能力测试成绩及测试成绩转换后的定序数据。同时,这6名候选人还经过面试,面试结果与成绩排序名次并不相同(表5-13b)。表中列出各对数据的差异值d及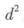 ,代入上式得
,代入上式得
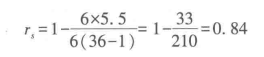
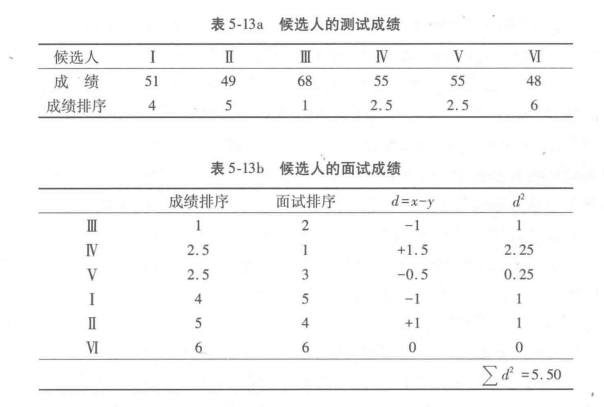
计算结果说明考试成绩与面试结果具有较强相关性,考试名次在前的,面试结果也很可能排名较前。
六、相关系数的临界值
相关系数应该是多大才说明实际存在相关关系,这涉及相关系数的临界值设定问题。
在假设检验中,要结合显著度及样本数给出相关系数的临界值,用以判断所得相关系数是否真正与零有差异,是相关关系还是随机关系。如算出的相关系数大于临界值,说明可能存在相关关系,支持“某项相关关系存在”的假设。
在给定的显著度条件下,样本量是影响判断的重要因素。样本越小,相关系数值应该越大,100个样本得出的相关系数要比30个样本令人放心。30 是相关关系研究所需的最小样本。当显著度为0. 05,样本量为10时,相关系数至少要到0.631 9才说明存在相关关系,样本量为102时,相关系数则只需要0.1946。如果能收集到总体每个样本的数据,就不存在推论问题,不管相关系数怎样小,都能代表变量间的实际相关程度,即使小如0.11,仍表示存在相关关系。样本数越是接近总体,则某个相关系数更接近真实关系。
在给定样本量的情况下,相关系数的临界值随着显著度大小而有不同要求,例如,10个样本(df=8),a=0.05,相关系数的临界值为0.6319,当a=0.01,临界值则增加到0.764 6。系数越大对判断的正确性就越有信心。但是显著度和强度不能混淆,显著度不管选择大或小,都与两变量相关强弱无关。
临界值还与计算相关系数的目的有关。预测研究对相关系数的要求更高,如样本数为102,a=0.05时,按表查出的相关系数临界值为0.1946,但对于预测研究而言,这个相关系数偏低,价值不大,协同变异部分只有(0.194 6)平方=0. 037 9,即3. 8% ,这样小的百分比用于预测另一个变量的变化值,意义甚小。相关系数小于0.5,一般起不到多大的预测作用,除非若干变量组合预测,才可能有意义。
相关系数用于估计测试问卷的信度和效度时,还要求提高标准,相关系数为0.4,在假设关系的判断中尚可接受,在预测研究中已不大合乎要求,若用于信度效度分析,这个系数离要求更远。相关系数0.6在预测中尚可接受,在问卷信度效度中却是不合要求的,后者要求达到0.9,最低也不能小于0.7。
相关系数分析只是讨论一种相关关系,而非因果关系。强相关可能存在因果关系,但并非必然。相关系数高,也可能是由于第三个变量引起的。例如公司社会责任和财务状况之间的关系,可能是公司财务状况好以致承担更多的社会责任,也可能是反过来,公司更多地承担社会责任导致财务状况改善,也不能排斥其他原因,如高素质、有社会责任感的高层领导才是引起两者均情况良好的真正原因。相关分析回答不了这类归因问题。
在问题辨识和提出假设阶段,研究者往往会考虑许多变量,这时,相关分析可以起到辨识变量的作用。不相关或相关系数很小的变量可以排除,研究者可以集中注意那些强相关的变量,深人分析它们之间的因果链。在论证阶段,若发现有些研究假设没有涉及的变量却与因变量强相关,就要加以控制,在进一步的论证中将它们作为控制变量来对待,使之保持不变,凸显自变量的变化对于因变量的效应。