软件工程论文

卷积神经网络论文范文第四篇:卷积神经网络在无人驾驶中行人检测中的应用
摘要:随着近年来5G与人工智能的崛起,无人驾驶技术在不断突破,行人检测作为无人驾驶中的重要任务之一,是一个具有重要研究意义的课题。文中采用深度学习框架Pytorch和目标检测网络YOLO进行行人检测,分别搭建了YOLO v3、YOLO v3轻量版YOLOv3-Tiny、YOLO v3与SPP-Net融合版本YOLOv3-SPP行人检测平台,并对小型目标和大型目标识别进行了详细的测试对比。测试结果表明,YOLO v3和YOLOv3-SPP平均置信度较高;YOLOv3-Tiny实时性较高,适用于计算量小的行人识别场景。
作者简介:付友(1988-),男,本科,工程师,研究方向为智能识别和神经网络。;*杨凡(1983-),男,博士,副教授,研究方向为人工智能技术。;
关键词:行人检测;深度学习;目标检测;卷积神经网络;
基金:重庆市基础科学与前沿技术研究专项面上项目基金资助项目(cstc2019jcyj-msxmX0233);重庆市教育委员会科学技术研究计划(KJQN201901125);国家电网公司科技项目资助(SGCQSQ00BGJS2000453);
Abstract:With the rise of 5 G and artificial intelligence in recent years, unmanned driving technology is constantly making breakthrough. Pedestrian detection is one of the important tasks of unmanned driving, and it is an important research topic.This project will use deep learning framework Pytorch and target detection network YOLO for pedestrian detection, YOLO v3, YOLO v3 lightweight version YOLOv3-Tiny, YOLO v3 and SPP-Net fusion version YOLOv3-SPP are establised to test and being compared in terms of small and large targets. Experiment results show that YOLO v3 and YOLO v3-SPP has higher average confidence, while YOLOv3-Tiny has a low real-time performance which suits the pedestrian recognization situation of a small amount of calculation.
Keyword:pedestrian detection; deep learning; target detection; convolution neural network;
0 引 言
随着科技的进步,交通工具愈来愈发达,人们出行也更加便利,但与此同时也带来了许多安全隐患,安全事故频频发生,造成这一现象的直接原因是疲劳驾驶、酒后驾驶等。究其根本原因是驾驶员不能及时准确判断道路状况以及不能在发生紧急状况时采取最优措施。因此,为了减少交通事故的发生,出现了无人驾驶系统,利用计算机快速、稳定、准确的计算能力,在车辆行驶过程中提供安全行驶保障,极大地降低了交通事故的发生率。
在无人驾驶系统中,行人检测是一大关键点。不仅要检测出前方行人的数量和距离,还要检测出行人的具体位置,为驾驶系统中央处理器提供可靠的数据,以此采取措施,保证车辆的安全通行,同时也保证了行人的安全。行人检测属于目标检测的分支。如今目标检测已经成为越来越热门的方向,它可以被广泛应用于工业产品检测、智能导航、安防监控等各个实际应用领域,帮助政府机关和广大企业提高工作效率,实现"向科技要人力".
1 基于深度学习卷积神经网络模型
目前,行人检测方案主要分为两类。第一类方案是基于背景建模,首先找出前景运动的目标,然后根据特定区域进行特征提取,然后利用分类器进行分类,判断出是否有行人,但该方法主要存在以下问题:① 环境变化大,例如光照会对图像色度造成影响;② 当画面中出现密集的目标时,检测效果急剧下降;③ 分类器必须对背景物体的改变做出正确的判断,而不能将其分类为目标物体。第二类方案是基于统计学习的方法,这是目前行人检测常用的方法,根据提前准备好的大量的行人样本以及对应标签构建行人检测分类器,主要代表有深度学习。目前深度学习在行人检测方向有大量应用,主要分为一阶检测和二阶检测,二阶检测比一阶检测先提出,主要有算法生成一系列样本并作为候选框,再利用卷积神经网络分类,主要代表有R-CNN[1]、Fast R-CNN[2,3]、Faster R-CNN[4,5].而一阶检测是直接回归预测目标的类别和位置坐标信息,精度相对二阶检测略低,但速度更快,主要代表有YOLO[6]系列和SSD[7].
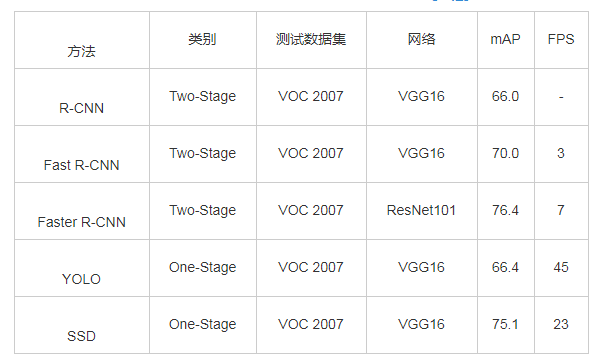
行人检测从传统检测方法到深度学习的应用,在准确率和计算量上,都有了较大的改善。从Two-Stage系算法代表作R-CNN、Fast R-CNN、Faster R-CNN到One-Stage系算法代表作SSD、YOLO,甚至是近两年的SqueezeNet[8]和MobileNet[9],无论是在准确率、实时性还是模型轻量化程度上,都有了突破性的进展[10,11].在SSD和YOLO算法出现以前,虽然目标检测的准确率比较可观,但实时性还不能达到要求。表1为不同方法在PASCAL_VOC数据集上的实验结果。
表1 不同方法在VOC 2007数据集上的实验结果对比
考虑到行人检测在工程应用中对实时性要求较高,本文采用YOLO算法实现行人检测。目前,YOLO系列算法一共发布了三个大版本,即YOLO v1、YOLO v2、YOLO v3,也发布了一些派生版本,例如YOLOv3-Tiny、YOLOv3-SPP.YOLOv3-Tiny是在YOLO v3的基础上,裁减了特征提取网络中的一些特征层,在速度上更快,但精度有所降低。YOLOv3-SPP是YOLO v3与SPP-Net[12]网络的融合。本文采用深度学习框架Pytorch和目标检测网络YOLO实验了行人检测系统,并分别搭建了YOLO v3、YOLO v3轻量版YOLOv3-Tiny、YOLO v3与SPP-Net融合版本YOLOv3-SPP行人检测平台,并对小型目标和大型目标识别进行了详细的测试对比。
2 实验与分析
2.1 实验系统设计
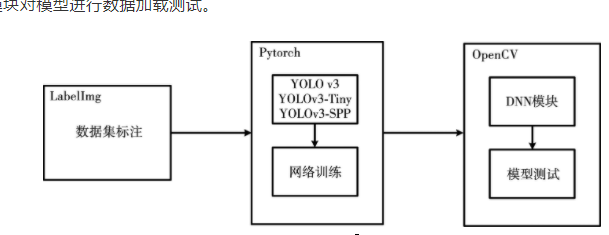
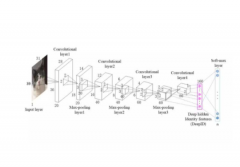
本文将采用深度学习框架PyTorch进行YOLO v3整体目标检测网络结构搭建。具体做法是:首先通过人工使用LabelImg软件对行人数据集进行行人标注,然后从YOLO官网下载三个网络结构cfg文件,通过PyTorch提供的内置库函数,将三种网络结构信息cfg文件进行解析,并搭建出深度学习模型,其次将图片进行数据增强等预处理操作,按批次送入网络进行前向传播和反向传播训练,最后得到模型的权重文件。利用OpenCV提供的解析深度学习模型的接口DNN,加载训练好的模型,通过输入图片和笔记本电脑内置摄像头进行测试。整体设计框架,如图1所示。
2.2 行人检测效果测试
本节将在CPU为i5-6300HQ、GPU为GTX960M的笔记本电脑进行本文纵向与横向的测试对比,即分别在单独使用CPU和GPU加速的情况下对YOLO v3、YOLOv3-Tiny、YOLOv3-SPP网络进行输入图片和摄像头测试,其中图片测试分为小型目标和大型目标测试,并将测试结果进行准确率、测试速度对比。具体采用OpenCV提供的DNN深度学习模块对训练好的模型进行加载。DNN模块最早来自Tiny-dnn, 可以加载Caffe预训练模型数据,OpenCV在3.3版本中将DNN模块迁移到OpenCV正式发布模块中,并扩展支持包括Tensorflow、PyTorch和Caffe等所有主流的深度学习框架。本文也将采用DNN模块对模型进行数据加载测试。
图1 系统整体设计框架
2.2.1 图片测试
本小节将对模型进行输入单张图片测试,先使用小目标图片进行测试,观察目标在图片中占比小的情况下的检测效果;再使用大目标图片进行测试,观察目标在图片中占比大的情况下的检测效果。
① 小型目标测试。
检测小型目标主要依靠浅层特征图,浅层特征图比深层特征图感受野小,有利于检测小型目标,这都归功于YOLO v3的网络结构,相比于YOLO v1和YOLO v2对小型目标检测效果不佳的现象,YOLO v3增加了浅层、中层、深层特征图的融合,提高了对小型目标检测的能力。
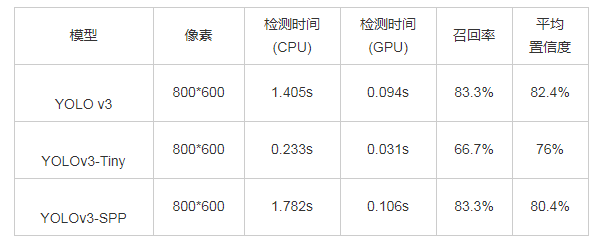
测试图片为行人占整幅图像比例比较小的图片,背景等其他目标干扰较大,图片像素为800*600.分别使用三种不同网络进行检测,检测效果如图2所示,一共有6个person, 在CPU运行下,使用YOLO v3模型的检测时间为1.405s, 检测出5个person对象,在召回率约83.3%前提下,平均置信度为82.4%;使用YOLOv3-Tiny模型的检测时间为0.233s, 检测出4个person对象,在召回率约66.7%前提下,平均置信度为76%;使用YOLOv3-SPP模型测试的检测时间为1.782s, 检测出5个person对象,在召回率约83.3%前提下,平均置信度为80.4%.在GPU加速下,三个模型检测时间分别为0.094s、0.031s、0.106s, 分别同比提升约1394.1%、651.6%、1578.6%.各模型测试指标对比如表2所示。
② 大型目标测试。
对于大型目标主要通过深层特征图进行检测,深层特征图具有窗口小,感受野大,通道数多的特点,在YOLO v3中,深层特征图大小为13*13*255.
图2 小型目标测试

表2 小型目标测试指标对比
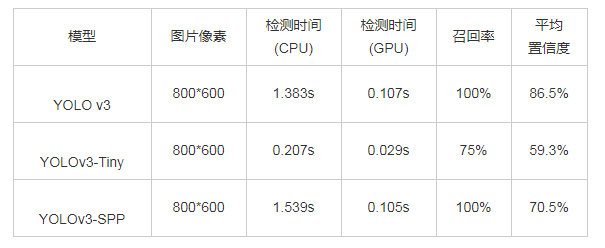
测试图片为行人占整幅图片比例较大的图片,背景等其他目标干扰较小,选取的图片像素为800*600,分别使用三种不同网络进行检测,检测效果如图3所示。从检测效果图看出,图中一共有4个person对象。在CPU运行下,使用YOLO v3模型的检测时间为1.383s, 成功检测出4个person对象,在召回率为100%前提下,平均置信度为86.5%;使用YOLOv3-Tiny模型的检测时间为0.207s, 成功检测出3个person对象,在召回率为75%前提下,平均置信度约为59.3%;使用YOLOv3-SPP模型测试的检测时间为1.539s, 成功检测出4个person对象,在召回率为100%前提下,平均置信度为70.5%.在GPU加速下,三个模型检测时间分别为0.107s、0.029s、0.105s, 分别同比提升1192.7%、613.9%、1365.2%.各模型测试指标对比如表3所示。
图3 大型目标测试

表3 大型目标测试指标对比 导出到EXCEL
2.2.2 实时摄像头测试
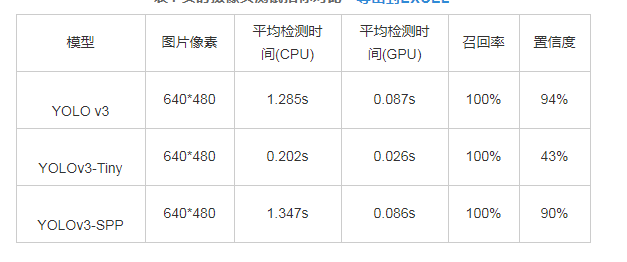
在实际应用里,智能安防、自动驾驶等领域都需要用到行人检测,尤其是自动驾驶,对行人检测的速度、实时性有极高的要求。因此,本节将对该检测器的实时性进行测试,通过笔记本电脑内置摄像头进行测试,由于内置摄像头为VGA摄像头,因此分辨率最大为640*480,并且由于开启实时摄像头时,图像内前景与背景无法做到完全一致,因此测试结果存在一定偏差。测试效果如图4所示。从测试结果图看出,一共只有1个person对象,三个网络都检测出目标,召回率都达到100%,但三者的置信度和测试速度不同。在CPU运行下,使用YOLO v3网络的置信度为94%,取其中连续十帧的检测时间,分别为1.281s、1.288s、1.295s、1.281s、1.279s、1.291s、1.280s、1.277s、1.290s、1.287s, 平均值约为1.285s, 帧数约为0.78帧,画面明显卡顿,不能满足实时检测任务。使用YOLOv3-Tiny网络的置信度为43%,取其中连续十帧的检测时间,分别为0.203s、0.203s、0.202s、0.200s、0.204s、0.202s、0.201s、0.202s、0.204s、0.201s, 平均值约为0.202s, 帧数约为4.95帧,勉强满足实时检测任务。使用YOLOv3-SPP网络的置信度为90%,取其中连续十帧的检测时间,分别为1.346s、1.341s、1.346s、1.348s、1.343s、1.346s、1.348s、1.352s、1.341s、1.352s, 平均值约为1.347s, 帧数约为0.74帧,不能满足实时检测任务。在GPU加速下,同样取连续十帧,计算平均检测时间,三个模型平均检测时间分别约为0.087s、0.026s、0.086s, 帧数分别约为11.49帧、38.46帧、11.63帧,帧数分别同比提升约 1373.0%、677.0%、1471.6%.三个模型进行实时摄像头测试的指标对比如表4所示。
图4 实时摄像头测试效果图

表4 实时摄像头测试指标对比
3 结束语
本文利用Pytorch框架,将YOLO v3、YOLOv3-Tiny、YOLOv3-SPP在行人检测方面进行了横向和纵向对比。YOLO v3和YOLOv3-SPP网络在能保证较高召回率的前提下,平均置信度能达到70%以上,使用CPU处理每张图片的时间通常在1s以上,主要是因为YOLO v3和YOLOv3-SPP使用了完整的YOLO v3网络结构,计算量相比YOLOv3-Tiny大了许多,但在GPU加速下,帧数能达到10帧左右,勉强能满足实时性,效果提升明显。使用YOLOv3-Tiny作为输入网络,在召回率和置信度两个方面都略逊于另外两个网络,但由于YOLOv3-Tiny更轻量级的网络结构,使得在执行检测任务时,计算量小,处理图片和视频的速度更快,在实时性上要优于另外两个网络。
参考文献
[1]姜星宇,辛兰,刘卫铭基于压缩轻量化深层神经网络的车辆检测模型[J].信息技术, 2020,44(7):23-27.
[2]王纪军,靖慧,冯曙明,等基于Faster R-CNN的仓库视频监控目标检测方法研究[J].信息技术, 2019,43(7):92-96.
[3] Girshick R.Fast R-CNN[J].Computer Ence,2015.
[4]罗靖遥,黄征基于CNN分类器和卷积的目标检测[J].信息技术, 2017.41(9)-:101-104.
[5] Ren S Q,He K M,Ross G,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J]IEE Transactions on Pattern Analysisand Machine Intelligence,2017,39(6)。1137-1149.
[6] Redmon J,Divvala S,Girshick R,et al.You only look once:unifled,real-time object detection[C].Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Rec ognition(CVPR)。Las Vegas ,NV,USA:IEEE 2016:779-788.
[7] Liu W,Anguelov D,Erhan D,et al.SSD:single shot multibox detector[C].Proceedings of the 14th European Conference on Computer Vision(ECCV)。Amsterdam,Netherlands: Springer,2016:21-37.
[8] landola F N,Han S,Moskewicz M W,et al. SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and <0. 5MB model size[C].5th International Conference on Learning Representations, Toulon,Fr,2016:1-13.
[9] Sandler M,Howard A,Zhu M,et al.Mobilenetv2:inverted residuals and linear botlenec ks[C].Proceedings of the IEE Conference on Computer Vision andPattern Recognition,2018:4510-4520.
[10]胡瑞雪,曾曦基于BERT-LSTMCNN的立场分析[J].信息技术, 2020,44(2):93-97,102.
[11] Wang X.Wang s,Cao J,et al.Data-driven based tiny-YOLOv3 method for front vehicle detection inducing SPP-net[JIEEE Access,2020(99)-1.
[12] He K M,Zhang X Y,Ren S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J.IEE Transactions on Pattern Analysis and Machine Intelligence ,2015,37(9):1904-1916.
本文建立了一种基于注意力机制的双向特征金字塔的安全帽检测卷积神经网络。为兼顾卷积神经网络中的浅层位置信息和深层语义信息的表达能力,实现对弱小安全帽目标的检测能力....

伴随着交通行业的飞速发展,车牌识别技术已然成为一项非常重要的研究课题,并在日常生活中有着广泛的应用。...