计算机应用技术论文

机器学习论文范文第六篇:一种基于机器学习的入侵检测模型研究
摘要:本文针对网络流量数据规模较大、攻击与入侵样本分布不平衡等特点,提出了一种基于机器学习的入侵检测模型。该模型结合深度降噪自编码器与马氏距离差值算法,可以提取更为关键的特征,提高了神经网络进行入侵检测的性能。通过实验表明,本文所提的两种方法在入侵检测任务中呈现出更高的准确性,与原始自编码器相比提高了8.1%.
关键词:机器学习;入侵检测;自编码器;
作者简介:屈耘野(1999-),男,浙江省台州市人。大学本科在读。研究方向为计算机科学、数据科学与机器学习。;姜咏琪(2002-),女,黑龙江省齐齐哈尔市人。大学本科在读。研究方向为深度学习、信息与计算科学。;

1 引言
网络攻击与入侵很可能会带来广泛的负面影响,包括数据损失、经济损失和多维度的安全威胁。网络攻击与入侵所导致的业务中断,很可能引发数据泄露,面临敲诈勒索等威胁。对医疗系统的攻击,使非法入侵者获取关键信息,更是让医疗检测和器械的准确性大打折扣;无人驾驶系统中的攻击与入侵,更关乎每个公民的人身安全。
近年来,基于机器学习的检测技术在诸多领域进行了应用。2017年,Litjens[1]等人调查了在医学领域使用机器学习技术的状况,特别是在医学图像分类、目标检测、分割和其他任务中的应用。2018年,Mohammadi[2]等人提供了用于物联网大数据的机器学习算法与框架背景。Kiran[3]等人总结了应用于时空数据检测的机器学习模型,并研究了相关评估标。
这些应用的实际成果表明,机器学习可能拥有超越传统算法的优势。本文提出通过数据噪音和马氏距离差值项改进最新深度自编码器(Autoencoder,AE)的方法,能够更为有效的进行高维流量降维与入侵检测,有助于弥补自编码器难以学习深层特性和克服数据损坏的缺点,并为日后希望实现或研究入侵检测技术的研究人员和工程师们提供经验与参考。
2 自编码神经网络算法
2.1 神经网络结构
自编码器的结构分为编码器和解码器两部分。它将输入编码并降维,提取数据关键的特征,然后解码并重建原始的高维输入数据,使得解码后的数据与输入本身尽可能一致[4].
本文中自动编码器使用分别具有42、24、12、12和42个神经元的5个全连接层。第一层是输入层,与数据原始输入的维度一致,与之后两层一同用于编码。最后两层用于解码,由于数据原始输入维度的要求,输出层的神经元个数与其一致。
其中编码部分每层之间分别使用双曲正切(Tan H)激活函数与整流线性单元(Re LU)激活函数。最后两层为解码层,同样使用Tan H激活函数与Re LU激活函数,能够更好地重构输入数据。
2.2 数据加噪
受整体结构复杂程度、数据集规模和噪声损坏等因素限制,原始自编码器训练生成的神经网络过拟合可能性较高。考虑对输入数据加入噪音,使学习得到的编码器具有较强的稳定性,提高其泛化性能。本文噪音使用标准正态分布(Standard Normal Distribution)函数:

服从该概率分布的噪音将添加到输入数据的每一个值上:
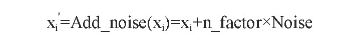
其中函数Add_noise用于加噪,n_factor为噪音权重系数,xj'为加噪后的单个数据样本在该维度上的值。
2.3 马氏距离差值项
马氏距离(Mahalanobis Distance)是一种度量样本之间相似程度的距离指标,既考虑到了各种特性之间的互相联系又独立于测量尺度[5].
设输入数据集的均值为:
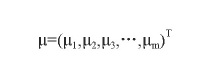
且数据集的协方差矩阵为∑,则其马氏距离表示为:

马氏距离计算过程中使用了数据集的均值,而均值会放大少量攻击入侵数据的影响[6].因此本文采取不受攻击入侵数据变化影响的训练集正常数据均值μN和协方差矩阵∑N,函数表示如下:
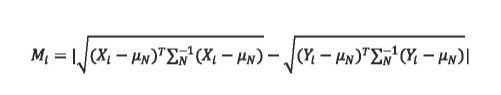
加入马氏距离差值项后改进的自编码器损失函数表示如下:
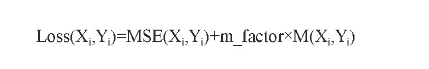
其中函数MSE是均方误差损失函数,m_factor为马氏距离差值项权重系数,M(Xi,Yi)为马氏距离差值。
3 实验与结果
3.1 环境与数据集
本文实验使用Ubuntu18.04.5操作系统,计算机CPU为Intel Core i7-10750H,RAM容量为40GB,基于Keras框架使用Python3.6.9与Tensorflow1.2.0底层实现;数据集使用基于KDD99数据集重采样的NSL-KDD数据集。
KDD99数据集源于美国政府国防部于1998年在马萨诸塞州林肯实验室(MIT Lincoln Laboratory)进行的一项网络攻击与入侵实验[7].其中训练集已经完成超过20种攻击入侵行为的标记,测试集中则包含了10余种未曾出现的新型入侵。KDD99数据集在第五届知识发现与数据挖掘国际会议发布,之后在事实上成为了网络攻击与入侵领域检验模型效果的测试工具。
NSL-KDD数据集对KDD99数据集进行了重采样[8].其中带标记的训练集与测试集均为41个维度。本次实验根据需要对相关标签进行了映射与转换,并排除了部分未知和错误的数据。处理后样本分布正常连接样本数量60179,占比54.50%;攻击入侵样本数量50231,占比45.50%.
3.2 实验配置

表1:网络攻击与入侵检测实验结果
训练数据集为基于实验数据集随机采样的约70%数据,测试数据集为剩余的约30%数据。其中噪音分布概率为标准正态分布,噪音权重系数n_factor为0.05.
由于需要用来训练自编码器神经网络的是正常流量数据,因此将训练集中的攻击入侵样本排除在外,测试集则保留所有正常和攻击入侵样本来提供评估模型性能的方法。训练集中的攻击入侵样本可视情况添加到测试集中,扩大测试集规模从而使实验结果更具参考性。
为了从不同的角度更好地评估本论文提出的两种算法改进所取得的异常检测效果,分别构建四个自编码器神经网络:原始自编码器、降噪自编码器、含马氏距离差值的原始与降噪自编码器。除了所提到的参数外,其余参数保持一致。
另有两个较为重要的超参数:batch是在每次更新模型参数之前处理的数据样本数量,epoch是训练过程中训练集完整的读取与训练次数。它们都是学习算法的整数超参数之一。本论文实验中,超参数epoch为150或300,超参数batch为32或64,将性能最佳的模型保存到文件中。每个参数进行10次完整实验取平均结果。
3.3 评价标准
本文选用混淆矩阵体现的准确性指标、接受者操作特征(ROC)曲线下方面积(Area Under Curve,AUC)作为评价标准。
混淆矩阵把所有类别的预测结果与真实结果按类别放置到了同一个表里,可以计算得到真负类率(True Negative Rate,TNR)指标,由预测为负样本、实际上也是负样本的结果数除以实际上负样本的总数得出。
对网络攻击入侵检测任务而言,在一定的范围内将正常连接识别为攻击入侵更能让人接受,因为这只是让需要详细审查的连接数量增加,而反过来可能直接导致攻击入侵的发生。因此考虑采用真负类率来衡量检测准确性,即下文所提准确性指的是真负类率指标。
ROC曲线的横坐标为假正类率,纵坐标是真正类率。AUC是ROC曲线下方所覆盖的面积,反映了ROC曲线表达的自编码器异常检测的能力。其值越接近于1,异常检测效果越好。
3.4 实验结果
由混淆矩阵可以计算出真负类率,也就是特指度,用来代表训练结果的准确性,同时由ROC曲线可以计算得到面积指标AUC,用来客观判断和比较自编码器异常检测的性能。四个自编码器方法的准确性(TNR)与AUC如表1所示。
由表1中四个实验的对比,可知降噪自编码都较原始自编码器针对攻击入侵具有更高的异常检测准确性,对于网络攻击入侵具有更好的特征学习能力,获得的隐层表达效果更好。马氏距离差值项的引入,也较为显著地增加了网络攻击入侵检测的准确性。实验表明了通过数据加噪与马氏距离差值项的加入都可以较为显著地提升异常检测效果,两者同时使用的异常检测效果最佳。
4 结语
本文改进机器学习中的深度自编码器技术,结合网络攻击入侵数据集,对神经网络的输入数据加入正态分布的噪声构成降噪自编码器,改进现有的均方误差函数,将马氏距离差值项添加到损失函数中。实验表明,改进后的自编码器能够更好地学习网络攻击入侵数据的关键特征,提高了神经网络学习的鲁棒性和稳定性,较原始自编码器具有更好的综合性能。本文在一定程度上为基于机器学习的网络攻击入侵检测做出了贡献。
参考文献
[1] Litiens G, Kooi T, BejnordiB E, et al. A Survey on Deep Learning in Medical Image Analysis[J]. Medical Image Analysis, 2017,42(9):60-88.
[2]Mehdi M, AlaA F, Sameh S, et al. Deep Learning for 1oT Big Data and Streaming Analytics:A Survey[J]. IEEE Communic ations Surveys&Tutorials, 2018:
[3]Kiran B,Dilip T,Ranjith P. An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos[J]. Journal of Imaging.2018.
[4]贾文娟,张煜东自编码器理论与方法综述[J]计算机系统应用,2018,27(05):1-9.
[5]李玉榕,项国波-种基于马氏距离的线性判别分析分类算法[J].计算机仿真,2006(08):86-88.
[6]吴香华,牛生杰吴诚鸥,秦伟良马氏距离聚类分析中协方差矩阵估算的改进[J].数理统计与管理2011 ,30(02)-240-245.
[7]Tallaee M, Bagheri E, Lu W, et al. A detailed analysis of the KDD CUP 99 data set. IEEE, 2009.
[8]Revathi S, Malathi A. A Detailed Analysis on NSL-KDD Dataset Using Various Machine Learning Techniques for Intrusion Detection ESRSA Publications,2013.

1我国的入侵检测系统面临的挑战及亟待解决的问题近年来,我国的网络安全受到各行各业人士的普遍关注。许多相关学者致力于维护网络安全的研究当中,导致我国网络安全技术得到普遍提升。但是有关网络攻击的情况还是不断出现。其中有一个很重要的原因就是,...
广义上的金融工程不仅为银行面临市场、信用等风险的企业贷款工作提供新的测量工具,其在金融科技的应用更为缓解小微公司融资压力提供了有效的传导路径。...
前言:近几年,我国教育规模在不断扩大,学生对于学校也提出了更高的要求,希望学校制度能够更加灵活,并且适合学生。学校需要为学生提供机房,满足学生对于学习进度、指示导向等等学习内容的要求,提高学校为学生服务质量。但是学生的这些需求对于学校机房...

重点阐述了如何利用决策树和神经网络筛选奶牛疾病风险因子、预测疾病和疾病分类。同时,综述了机器学习预测代谢性疾病、跛行、乳房炎、热应激和传染性疾病的进展。...

随着互联网金融行业的兴起,银行和贷款机构通过互联网为有贷款需求的客户提供线上金融服务。在带来更好服务体验的同时,也存在着诸多信用风险问题,急需建立信贷风险检测模型提高风控水平。...

近年来随着生物医学研究的发展,对于脑卒中的研究日益深入,在基于"组学"数据[8,9]、实时风险预测等方面的研究对统计学工具的要求不断提高。...