演化语言学是以达尔文进化论为基础的语言学,主要关注语言的起源与发展的问题。20世纪80年代以来,受遗传学、分子人类学、数理统计学等学科发展的影响,演化语言学在国外迅速兴起,取得了许多重要的突破;同时,演化语言学在国内也开始受到重视,其理论与方法被广泛引入,在演化理论指导下的科学实践逐步展开。演化语言学理论的兴起,为语言研究打开了一个新的窗口。
一、演化语言学的理论与方法
(一) 演化论与语言学
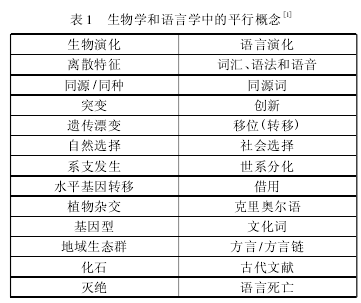
1859年,达尔文在其《物种起源》一书中首次系统地提出演化论,指出生物是进化的,自然选择是生物进化的动力。随后演化论产生巨大影响,不仅成为现代生物学的基石,还成为其他许多学科的重要指导理论。而在演化论产生之初,其思想就已与语言学联系了起来。在1871年出版的《人类的起源》一书中,达尔文就已经注意到生物演化和语言演化之间存在一种令人惊奇的对应现象,二者在许多特征上都具有相似性。他在《物种起源》一书中就提出一个设想:如果我们能够画出一张人类族群的发展树状图,就可以从中得到一张囊括现今世界上所有语言的分类图。1863年,德国语言学家施莱歇尔《达尔文理论与语言学》一书出版,该书全面接受了达尔文的进化论,并使用生物学上的种系树图方法,为印欧语系画出了第一张谱系树图,同时还提出树图中分支的长度也许可以表示时间深度的理论。树形图被用在比较语言学上,成为分析、表现语言之间谱系关系的重要方法。除了都具有类似的谱系关系外,生物学和语言学在其他许多方面也有着重要的平行对应关系。
比如,二者都可以通过同源结构推测共同祖先:生物学中可以通过蛋白质与DNA序列的相似性来确定它们是否具有共同的祖先,而语言学中则可根据同源词来推定语言的共同祖先。此外在生物遗传和语言演变过程中,都会发生突变等纵向的变化以及漂移等横向的变化:生物学中细胞在分裂时会发生基因复制错误,产生突变,而语言演变中也会出现诸如非条件音变之类的语言创新,这是语言演变中的突变。横向来看,生物学中会发生基因组在不同物种之间转移的水平基因转移(horizontal genetransfer)现象,而语言演化中则经常发生词汇、语音及语法的借用,形成语言结构的水平传递。此外,生物学和语言学之间还广泛存在着许多其他重要的对应现象,Q.D.Atkinson(2005)将这些对应现象总结为下页表1.
(二) 演化生物学理论在语言学中的应用
人类的起源与扩散和语言的产生与发展有着紧密的联系。语言是人类得以和其他动物区别开来的最重要的特征之一。近年来,遗传学界对人类mtD-NA和Y染色体DNA的研究成果显示,现在全世界的人类都是大约20万年前一位非洲妇女(线粒体夏娃)的后代,即现代人类是起源于非洲的。非洲起源说是目前国际学术界关于人类起源的主流学说。着名人口遗传学家卡瓦利(Cavalli-Sforza)认为,智人之所以能够成功地由非洲扩散至全世界,正是因为他们发明了一种极为重要的工具---人类所独有的语言。语言的扩散与人类的扩散所具有的紧密联系,使得两个学科有着共同的目标,面向共同的问题,因此演化生物学和演化语言学的理论与方法也可以互相参考与借用。
演化生物学中的谱系树理论、定性的观念以及定量的方法都已经被应用到语言学中,对历史语言学的发展起到了较大的促进作用。语言学家运用演化理论,为语言演变建立了各种理论模型,用以解释语言演变的过程。下面简要介绍几种演化语言学中来自于演化生物学的理论。演化生物学中最早被借用到语言学中的理论是谱系树理论。自演化论产生以来,树形图就被用来描述物种之间的发生学上的种系关系。而自施莱歇尔开始,语言学家们也开始运用谱系树理论,描述语言之间的谱系关系以及语言特征的纵向传递过程。
谱系树模型只能用来描述语言演化中语言特征的纵向传递(遗传特征),而实际上语言之间还通过接触广泛进行着横向传递(借用现象)。如何客观反映语言演变中的横向传递很早就受到语言学家的关注。早在19世纪,Johannes Schmidt就提出了描述语言特征地域性扩散的“波浪学说”,补充了谱系树模型在描述语言横向传递方面的不足。卡瓦利和王士元(1986)又将人口遗传学中的“脚踏石模型”应用到语言演变研究中,使用计量分析方法研究了密克罗尼西亚一系列岛链上的词汇,研究结果反映出词汇在空间上的替代速率与时间上的替代速率具有明显的正相关性。他们的研究为探索语言的横向传递与纵向传递的关系开辟了新的视角。
模因论是另一个受生物演化理论影响而产生的文化传递模型。1976年,道金斯(Dawkins)在其《自私的基因》一书中,将文化传承、发展的过程和生物演化过程进行类比,提出模因理论。他认为文化“演化”中的基本单位模因(Meme)同生物演化中的基因一样,都是通过复制实现传播与遗传的,复制过程中的“突变”导致变体的产生,变体通过竞争实现自然选择。道金斯还特别指出文化演化与生物演化具有明显的差异,即生物演化是通过基因的代际纵向传递实现的,而文化演化中模因的复制则是通过人的模仿而横向扩散传播的。道金斯的模因论适应面非常广泛,包含了文化现象的方方面面,而在语言学方面,已有学者使用该理论来研究语言演变的模式。
如Ritt(2004)认为语言作为一种文化现象也可以用模因论来解释:音素、词素及语音规则等是语言中的基本的演化单位,因此都是模因。语言模因通过说话人的模仿而复制传播,复制过程中的缺陷(类似基因突变)导致了变体的产生。语言模因变体在各种选择压力的推动下相互竞争,模因之间的相互适应就是一种选择压力,他尝试使用这种选择压力理论解释了英语中音步结构与元音演变之间的互动关系。
(三) 演化语言学的研究方法
达尔文提出进化论,孟德尔发现基因,极大地促进了演化生物学的发展。20世纪中叶,Watson和Crick阐明了DNA的精确结构,随后DNA序列被测出,由此产生了大量待分析的数据,促使生物学家们积极地引入了数学统计和计算方法。目前生物学中已经形成了许多成熟的种系计算方法,这些方法也逐渐被应用到语言学中,用来精确地计算语言之间的距离关系,使得语言谱系的建立得以突破传统的依赖于经验的定性分类法,开始进入可验证的实证性研究阶段。
斯瓦迪士的“词源统计法”是最早引入语言学中的一个距离算法。词源统计法通过语言间同源词的比例建立它们的距离矩阵,然后通过距离矩阵推理出语言谱系结构。虽然他因其词汇替代速率是恒定的假设等问题而广受批评,但是其引入的定量方法却为计算语言分裂年代及时间深度的研究开辟了新的思路。最近几十年来,其他距离法,系统发生学中的最大简约法(Maximumparsimony)①、统计学中的贝叶斯法等都开始被引入语言演化的研究中。比如,MinettandWang(2003)使用一种距离法和一种特征法试图区分语言间的同源和借用情况。他们首先通过比较树枝长度和词汇距离的方法检验了词源统计法中基于距离的方法,发现该方法无法将借用和同源区分开来。随后,他们又使用了一种基于特征的最大简约法来分析中国几种主要方言的数据,发现该方法可以确定汉语中相似和借用的情况。
这类新的数学方法的应用,为解决传统历史比较法难以区分同源和借用的问题指明了新的方向。此外,随着计算机处理能力的飞速发展,计算机建模也成为演化语言学中的一种重要的研究方法。对于人类语言起源等无法直接观察的问题,计算机建模的作用非常明显,因为“它是可以透视这个问题的少数几个窗口之一”,通过计算机模型“我们可以虚构一个简单的世界,专门来研究个别的问题。”
王士元、柯津云(2001)建立了一个模型用来模拟语言产生之初的场景,该模型设计了人群大小、信号和概念数量等3组变量及人们互相之间模仿的5种策略,用以观察这些因素对语言起源场景下共同信号系统形成的影响。通过对模拟仿真结果的数学分析,他们发现人数和声音数目(信号)越少,人群越容易形成统一的信号系统。而在人群规模不大的时候,“为跟随大多数或者减少同音词而模仿对方”的策略是形成共同信号系统的最优方案。这类计算机仿真模型可以将复杂的语言问题简单化,针对性地研究复杂语言现象中的某些具体因素,同时还可以通过增加、修改参数的方式,了解各种因素之间的相互关系,进而深入了解各种语言现象的本质。
二、演化语言学在中国语言及方言谱系研究中的实践
目前,演化语言学在国内也开始迅速发展,以演化理论为指导和运用新的演化语言学方法的研究也逐渐丰富。我们在中国的语言和方言的分类问题上,采用新的理论与方法,做了有益的探索。传统的关于中国语言及方言分类的研究,都是通过音韵、词汇、音变类型等特征及规则进行的定性描写,并以这些特征和规则作为分类标准来建立语言间的谱系分类关系。因此传统的谱系分类研究存在两个问题:一是分类标准的确立主观性较强,使得分类结果可信度不高;二是缺乏对分类特征权重的计算,无法量化语言及方言间的亲疏程度,无法确定各语言由原始母语分裂出来的时间深度。
为克服传统谱系分类研究的不足,我们引入了最新的生物学种系发生理论和方法,结合语言学中的词源统计分析法,使用计算机算法程序,对中国的语言及方言的谱系分类重新进行了研究。在研究材料上,我们收集了汉藏语系的苗瑶语族、壮侗语族、藏缅语族各12支语言、南岛语系和南亚语系的6种语言以及汉语闽、客方言中各6-10个方言点的基本词汇数据,并以斯瓦迪士100核心词为基础,结合各语言(方言)的人文特点,对100核心词加以优选、增补,确定研究的基本核心词。同时为了解决词目与义项相纠葛的问题,我们采用了“词根词源统计法”,使用较严格的语义对应原则确立核心词。
在以上核心词的基础上,我们使用“词源统计分析法”进行分析、计算,绘制出了语言种系发生的树状图,并计算汉藏语系各语言及方言从祖语分裂出来的时间。“词源统计分析法”的操作过程主要分为几步:(1)根据核心同源词,编制出同源词表,并计算出各对语言之间的同源百分比,形成相似矩阵(SimilarityMatrix)。相似矩阵的确立是计量研究的基础,也是决定各方言间关系最关键的一步。(2)为能够反映各语言间的距离,我们通过公式d=-logs将相似矩阵转换为距离矩阵(DistanceMa-trix),以距离数据作为树状图分支长度计算的数据基础。(3)将距离矩阵转换成无根树的过程计算量巨大,为此我们借用了生物学中为种系发生分类设计的计算程序,通过计算各对语言之间的距离,优选生成最合理的树形图。(4)通过语言间共用核心词的不同比例来计算各语言及方言从祖语分裂出来的时间。同时我们还计算了树图中各个分离点的时间深度,可以形成对整个语群演化过程的整体认识。
我们的研究结合了分子人类学与词源统计分析法等先进的研究方法,结合定性分析与定量分析,对中国的语言及方言的发生学关系做出了科学的测定和分类。跨学科理论与方法结合的研究在国内尚处于开创时期,但是这方面的探索有望在语言学领域突破。
三 小结
演化论作为现代科学最重要的基石之一,已经成为许多学科的基础理论。近几十年来,随着演化生物学、分子人类学、数理统计学以及计算语言学的发展,演化语言学兴起的条件已经成熟,关于人类语言的起源与演化等曾经被束之高阁的问题也有了新的研究途径。演化语言学的研究需要积极引入遗传学、分子人类学、统计学等相关学科的先进理论、方法,结合考古学、体质人类学和人口遗传学的材料与证据,与各学科合作,共同推进对语言起源与演化问题的研究。
【参考文献】
[1]Atkinson Q D,Gray R D. Curious Parallels and Curious Con-nections: Phylogenetic Thinking in Biology and HistoricalLinguistics[J]. Systematic Biology,2005,54( 4) : 513 - 526.
[2]Cavalli - Sforza L L. 追踪亚当与夏娃---从演化历史看基因、民族和语言的关系[M]. 中国台北: 远流出版事业股份有限公司,2003: 96.
[3]Kimura M,Weiss G H. The stepping stone model of popula-tion structure and the decrease of genetic correlation withdistance[J]. Genetics,1964,49( 4) : 561.
[4]Cavalli - Sforza L L,Wang W S Y. Spatial Distance and Lex-ical Replacement[J]. Language,1986,62( 1) : 38 - 55.
[5]Dawkins R. The Selfish Gene[M]. Oxford University Press,1976.
[6]Ritt N. Selfish sounds and linguistic evolution: A Darwinianapproach to language change [M]. Cambridge UniversityPress,2004.
[7]Minett J W,Wang W S Y. On detecting borrowing: distance- based and Character - based approaches[J]. Diachronica,2003( 2) : 289 - 330.
[8]王士元。 演化语言学中的电脑建模[J]. 北京大学学报: 哲学社会科学版,2006( 2) : 17 -22.
[9]王士元,柯津云。 语言的起源及建模仿真初探[J]. 中国语文,2001( 3) : 195 -200.
[10]邓晓华,王士元。 壮侗语族语言的数理分类及其时间深度[J]. 中国语文,2007,321( 6) : 536 -548.
[11]邓晓华,王士元。 中国的语言及方言的分类[M]. 北京:中华书局,2009: 4 -6.