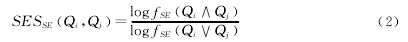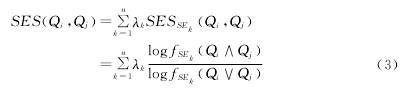1引言
作为最重要的互联网应用之一,搜索引擎是时代的产物,它的出现部分解决了互联网上信息泛滥所导致的信息检索困难问题。搜索引擎的类别也由传统的搜索引擎逐渐衍生出元搜索引擎、垂直搜索引擎、语义搜索引擎及智能搜索引擎等。
近年来,以WalformAlpha、Freebase及DBpedia等新一代搜索引擎为代表的智能搜索引擎引起了人们的极大关注,知识引擎呼之欲出。相似度计算是计算语言学领域的重要研究内容,在信息检索、文本分类、信息抽取和机器翻译等领域都得到了广泛的应用。现阶段对相似度的研究在语句相似度、语义相似度和文本分类等不同的领域均有较为成熟且有效的理论与方法,有力地推进了自然语言理解研究的进展。但不同的相似度计算方法对相似度的侧重点不同,难以形成统一的度量标准而不能全面反映对象之间的相似性,很多方面需要人的主观介入而欠缺客观性。为克服其不足,本文拟通过对搜索引擎结果的分析研 究探讨 基于搜索引擎的相似度计算方法。
2研究现状
2.1搜索引擎研究现状
搜索引擎于1990年由Archie推出以来,因其隐含着巨大的商业价值而得到迅猛发展。现阶段的搜索引擎有上千种之多,但人们对搜索引擎的研究往往集中在其商业价值及应用层面上,对其背后的科研价值却关注不足。搜索结果排序及搜索引擎评测是搜索引擎研究的两个主要方面。作为搜索引擎评测的重要内容,搜索结果排序算法是搜索引擎的核心。
PageRank作为标识网页等级的重要方法成就了Google在搜索市场的地位。元搜索引擎的核心也是排序算法。现阶段,互联网信息的爆炸式增长使得搜索引擎优化、搜索引擎营销等基于搜索引擎的研究与应用逐渐兴起并日趋显性化。
在搜索引擎结果排序方面,传统的排序算法如PageR-ank、HITS(Hypertext-Induced Topic Search)、超链分析等已得到比较广泛的应用,对上述排序算法的改进是搜索引擎排序算法研究的重点,同时也是各大搜索引擎运营商的核心机密。现有文献中已有的对搜索引擎排序算法的研究主要是对元搜索引擎排序算法的研究,如谢兴生等提出的粒子群算法在元搜索引擎结果优化中的应用、董乐等对元搜索引擎排序融合算法的改进。我们也对元搜索引擎排序建模与算法进行了研究,提出了将成员搜索引擎的市场份额引入元搜索引擎的结果排序中。
在搜索引擎评测方面,彭波等针对搜索引擎检索系统的质量评估对传统信息检索系统评估带来的新的研究问题,利用Tianwang搜索引擎查询日志,按类别构造评估查询集,用人工判别相关性的方法对3个搜索引擎进行了检索质量评估;Jansen等分析论述了9项对美国和欧洲5个搜索引擎的研究结果,其对搜索引擎的开发及网页的设计有一定的借鉴;张伟哲等针对分布式搜索引擎系统效能建模与评估问题,通过对当前分布式搜索引擎系统的建模与分类,扩展了能耗与网络开销的成本模型,并对5种构建搜索引擎系统的设计方案,从系统成本、系统规模和查询响应时间等角度进行了详尽的理论分析与评价。
作为首屈一指的搜索引擎,Google自推出以来受到越来越大的关注。人们已逐渐认识到其巨大商业价值背后隐含的科研价值。Rudi等利用词汇在Google中的搜索结果,提出了度量两 个 概 念 间 语 义 距 离 的 新 方 法,命 名 为Google距离。Google距离在语义标注、概念相关度等其他方面已得到了广泛的应用。搜索引擎的发展极大地改变了人们的观念,有力地推进了社会变革。在充分挖掘搜索引擎商业潜力的同时,人们也逐渐认识到搜索引擎的科研价值。深入挖掘搜索引擎的商业价值及科研价值,推动科技与经济的协同发展是当前搜索引擎研究的重要方向之一。
2.2相似度研究现状
度量相似性最典型的工具是距离,如传统的欧氏距离、曼氏距离、闵式距离、切氏距离等,包括Google距离在内,上述距离的取值范围均为[0,∞],不便于直接用于信息检索领域。
在信息检索领域,常用的距离度量指标有余弦相似度、Jaccard系数、Dice系数、相关系数等,上述距离的取值范围均为[0,1]。
此外,汉明距离、马氏距离、编辑距离等其他距离及各种改进也在实际中得到应用。
在计算语言学中,相似度的研究主要集中在词法分析及句法分析方面。在词法分析方面,现有的词语相似度计算方法主要有基于语义网的方法、基于知网的方法、基于同义词词林的方法、基于大规模语料库的方法、基于本体的方法、基于百度百科的方法以及其他方法。在句法分析方面,现有的语句相似度计算方法主要有基于词形词序匹配的方法、使用语义依存的方法、基于模式的方法、多特征融合的方法、基于动态规划的方法、频率增强的方法等。对文本相似度的研究由于其固有的复杂性,尚无成熟且公认的理论与方法,是相似度研究的重点与难点。
词语相似度的计算是语句、文本相似度计算的基础。《知网》采用新的数据组织方法处理词语之间的关联,符合人们的思维方式,其在词语相似度中的研究与应用近年来受到人们极大的关注。但与同义词词林类似,其词语是有限的,即只能用于分析处理词库中已有词语之间的相似度,对未登录词的处理还有待完善。
从词语相似度、语句相似度到文本相似度的计算来看,抽象层次越来越高,逻辑关系越来越复杂,相似度的度量也越来越困难。由于搜索引擎是现阶段最大的信息源,完全可以考虑在搜索引擎领域研究词语、语句乃至文本的相似度,这是本文研究的主要动机。
2.3搜索引擎在相似度中的研究现状
搜索引擎是当下信息检索的高级形式,搜索引擎的实现从某些方面来说也是基于相似度的,可以将搜索引擎应用于相似性度量中。但自Rudi等提出Google距离而首次将搜索引擎应用于相似性度量以来,对搜索引擎在相似度中的研究与应用还有待深入。
式中,f(Qi)表示在Google中搜索Qi时返回的匹配记录数;f(Qj)表示在Google中搜索Qj时返回的匹配记录数;f(Qi,Qj)表示在Google中搜索词组(Qi,Qj)时返回的匹配记录数;N表示Google索引的Web页面数。
NGD(Qi,Qj)是词条Qi和Qj共现的对称的条件概率,即假设给定一个页面含有Qi(或Qj),那么NGD(Qi,Qj)就表示这个页面同时含有Qj(或Qi)的概率。
显然,NGD满足非负性、同一性、对称性,且与相似度负相关。
NGD对将搜索引擎应用于信息检索做了有益的探索,它的提出极大地推进了对搜索引擎及自然语言理解等其他领域的研究,但其也存在不足,即不能直接用于度量不同概念之间的相关性及不同概念相对于同一概念相关性的差异等。
3基于搜索引擎的相似度研究与应用
3.1传统相似度计算方法的缺陷与不足
相似度是个数值,一般取值范围在[0,1]之间。以最受关注的词语相似度为例,传统的词语相似度计算方法主要有两类:一类是通过统计语料上下文中词语之间的相关性来得到其相似性,另一类是基于某种世界知识或者分类体系的方法来得到其相似性。前者主要关注词语共现,侧重于物理相似,后者主要关注词语语义,侧重于逻辑相似。随着词语相似度研究的深入,后者得到了越来越多的关注。
基于《知网》的相似度计算方法是根据整体相似度可由部分相似度合成而来的思想,通过寻找两个词语义原集合间的最相似元素来进行一一匹配,词语的相似度就等于各匹配对的加权均值,由于较多的加权值和参数,使得最终的结果或多或少地会带有一些主观因素。基于同义词词林的相似度计算方法从词语的语义出发,同时考虑了词语的相似性和词语的相关性,并根据词语的义项在同义词词林的位置和编码计算出词语的相似度,准确率较基于《知网》的相似度有一定程度的提高。本体、百度百科等其他工具的使用使得相似度的计算日臻完善。
由于《知网》及同义词词林均是人工编制的,规模有限,如《知网》仅 包 含96744个 中 文 词 语,同 义 词 词 林 仅 包 含77343个词语,这相对于海量的词语来说还是太少,必须在更大的范畴内分析计算相似度,尤其是词语的相似度。作为最大的信息源及最重要的信息检索工作,借助搜索引擎基于互联网信息计算相似度成为相似度计算的另一种选择。在此方面,Google搜索引擎的使用及百度百科的使用为基于搜索引擎的相似度研究与应用做了有益的尝试,下面给出基于搜索引擎的相似度计算方案。
3.2一种新的基于搜索引擎的相似度———搜索引擎相似度
鉴于不同搜索市场的实际情况,若直接将NGD用于度量中文、俄文及其他语种词语之间的相似度显然不适,需要结合具体情况进行扩展与改进。借鉴集合论中集合相似度的思想,我们定义一种新的基于搜索引擎的相似度计算方法,命名为搜索引擎相似度SES(Search Engine Similarity),表述如下:
式中,Qi及Qj意义同上,fSE(Qi∧Qj)表示在搜索引擎SE中含有Qi及Qj的匹配记录数,fSE(Qi∨Qj)表示在搜索引擎SE中含有Qi或Qj的匹配记录数。依此类推,可以定义不同搜索引擎的SES。
fSE(Qi∧Qj)及fSE(Qi∨Qj)可以通过搜索引擎的高级应用较为方便地获取。
显然SES满足非负性、同一性、对称性,且取值范围为[0,1]。与NGD相比,SES的主要优势在于计算简洁,切合常理,可直接用于相似性度量与相似性比较。
我们在文献[4]中提出将成员搜索引擎的市场份额引入元搜索引擎的结果排序中,这里同样将搜索引擎的市场份额引入搜索引擎相似度计算中,于是得到搜索引擎相似度SES的具体表达式如下:
式中,n为搜索引擎数目,λk为搜索引擎SEk的市场份额,显然
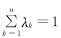
。由于搜索引擎数量较多,在实际计算中,可以选取有代表性的适当数量的搜索引擎用于计算SES,以降低复杂性。
3.3基于搜索引擎的相似度实验评测
利用上述相似度计算方法,可以较为简单地计算出词语、语句乃至文本的相似性。在上述定义的搜索引擎相似度SES的基础上,下面给出SES的简单应用。国内及国外的分析结构与评测机构如Hitwise、SearchEngine Watch等会定期或不定期地发布研究报告,公布各个搜索引擎的市场份额。现阶段全球搜索市场份 额为:谷歌65.2%,百度8.2%,雅虎4.9%,Yandex2.8%,必应2.5%1);全国搜索市场份额为:百度65.7%,360综合搜索8.7%,搜狗6.2%,谷歌香港4.2%,百度图片3.9%,搜搜3.3%,谷歌(英文)1.7%,必应1.2%,谷歌中国0.5%,有道搜索0.5%2)。可以针对实际情况采用不同的搜索引擎相似度计算方案,如在全球范围内选用所列举的5个搜索引擎或在全国范围内选用所。
列举的全部或部分搜索引擎计算搜索引擎相似度等。在全国范围内,选用足够数量的搜索引擎固然可以得到较好的结果,综合考虑实际情况及其他因素,此处选用的搜索引擎及对应的市场份额为:百度69.6%(包括百度图片),360综合搜索8.7%,搜狗6.2%,谷歌香港6.4%(包括谷歌(英文)及谷歌中国),搜搜3.3%,必应1.2%,有道搜索0.5%,共7个。
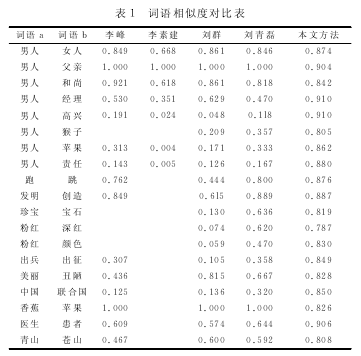
由于语句及文本尚无公认的测试集且缺乏统一的评测标准,这里选用一些公开发表的且具有代表性的基于《知网》的词语相似度研究成果进行对比。
表1是本文提出的相似度计算方法与文献[12]等其他文献中的相似度计算结果对比表。从表中可以看出,选用的测试词语对的相似度计算结果符合常理,精度高,可信度高,能较全面地反映词语之间的相似性,与参与对比的其他方法相比有一定的优势,可以直接或改进后应用于词语的相似性度量中。
需要说明的是,大部分搜索引擎几乎实现了实时更新,搜索引擎结果随之也在动态变化,采用上述方法在不同时刻相似度计算的结果会略有不同,但差别不大。
另外,本文提出的相似性度量方法的主要不足在于未考虑到各搜索引擎结果的重要性差别。由于各个搜索引擎结果的重要性并不对等,且作为搜索引擎基础数据的分词库及相应的算法并不完全相同,单纯地采用搜索结果交集基数的对数值与并集基数的对数值的比值作为对象相似度的评价标准还有待后续改进,而且对一些敏感词汇的处理也需要进一步完善。尽管如此,本文所提出的方法能够充分利用搜索引擎信息丰富、与时俱进的优势,采用简洁但合理的方法度量对象之间的相似性,对研究词语、语句和文本等概念及对象之间的关联有一定的借鉴意义。
结束语针对现有相似性度量方法的局限即不能全面反映词语、语句乃至文本之间的相似性,基于搜索引擎提出了一种新的相似性度量方法,其计算方便、简单,能够较为客观、合理地度量概念之间的相似性,可以应用于词语、语句及文本的相似性度量中。实验结果表明,该相似度计算方法与其他方法相比有一定的优势。由于语句并是词语的简单堆砌,文本并不是语句的简单罗列,对该方法在语句及文本相似性度量中的应用与推广尚需进一步深入研究。
参 考 文 献
[1]Bizera C,Lehmannb J,Kobilarova G,et al.DBpedia-A Crystalli-zation Point for the Web of Data[C]∥Proceedings of Web Se-mantics:Science,Services and Agents on the World Wide Web.2009:154-165
[2] 谢兴生,张国梁,李斌.利用粒子群算法优化多源检索融合结果的方法[J].模式识别与人工智能,2012,25(3):527-533
[3] 董乐,谢红薇.元搜索引擎中排序融合算法的优化研究[J].计算机应用与软件,2012,29(10):188-190
[4] 刘胜久,李天瑞,贾真,等.元搜索引擎排序方法建模与算法研究[J].计算机科学,2012,39(11A):197-199
[5] 彭波,闫宏飞.搜索引擎检索系统质量评估[J].计算机研究与发展,2005,42(10):1706-1711
[6]Jansen B J,Spink A.How are We Searching the World WideWeb?A Comparison of Nine Search Engine Transaction Logs[J].Information Processing and Management,2006,42(1):248-263
[7] 张伟哲,张宏莉,许笑,等.分布式搜索引擎系统效能建模与评价[J].软件学报,2012,23(2):253-265
[8]Rudi L,Paul M B.The Google similarity distance[J].IEEETransactions on Knowledge and Data Engineering,2007,19(3):370-383
[9] 张玉芳,艾东梅,黄涛,等.结合编辑距离和Google距离的语义标注方法[J].计算机应用研究,2010,27(2):555-557
[10]连宇,彭进业,谢红梅,等.基于Google与KL距离的概念相关度算法[J].计算机工程,2011,37(19):291-292
[11]刘群,李素建.基于《知网》的词汇语义相似度的计算[C]∥第三届汉语词汇语义学研讨会.中国台北。2002
[12]李峰,李芳.中文词语语义相似度计算———基于《知网》2000[J].中文信息学报,2007,21(3):99-105
[13]荀恩东,颜伟.基于语义网计算英语词语相似度[J].情报学报,2006,25(1):43-48
[14]刘青磊,顾小丰.基于《知网》的词语相似度算法研究[J].中文信息学报,2010,24(6):31-36
[15]田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报:信息科学版,2010,28(6):602-608
[16]石静,吴云芳,邱立坤,等.基于大规模语料库的汉语词义相似度计算方法[J].中文信息学报,2013,27(1):1-6
[17]刘宏哲.一种基于本体的句子相似度计算方法[J].计算机科学,2013,40(1):251-256
[18]詹志建,梁丽娜,杨小平.基于百度百科的词语相似度计算[J].计算机科学,2013,40(6):199-202
[19]鲁松,白硕.词距离的计算方法[M].北京:清华大学出版社,2001
[20]吕学强,任飞亮,黄志丹,等.句子相似模型和最相似句子查找算法[J].东北大学学报:自然科学版,2003,24(6):531-534
[21]李彬,刘挺,秦兵,等.基于语义依存的汉语句子相似度计算[J].计算机应用研究,2003,20(12):15-17
[22]王荣波,池哲儒.基于词类串的汉语句子结构相似度计算方法[J].中文信息学报,2004,19(1):21-29
[23]张培颖.多特征融合的语句相似度计算模型[J].计算机工程与应用,2010,46(26):136-137
[24]冯凯,王小华,谌志群.基于动态规划的汉语句子相似度算法[J].计算机工程,2013,39(2):220-224
[25]廖志芳,邱丽霞,谢岳山,等.一种频率增强的语句语义相似度计算[J].湖南大学学报:自然科学版,2013,40(2):82-88
[26]金博,史彦军,滕弘飞.基于语义理解的文本相似度算法[J].大连理工大学学报,2005,45(2):291-297[27]董振东,董强.《知网》[P].