搜索引擎论文


武警部队因其性质和任务的特殊性,致使武警官兵较常人更容易出现心理问题,所以有关军人心理的研究工作已是当前部队科研的一个重点 ;而结合武警部队实际,应用当前心理学最新研究成果,则是现阶段武警部队心理工作的普遍方法.但针对我军官兵心理特点的科学研究是近一时期才逐步发展并形成的,一方面我们要检索具有武警部队针对性的文献资源,另一方面武警部队自己的研究点滴也需积累.随着我军信息化进程不断深化,针对武警心理研究文献资料的检索查阅以及经验累积已不仅是科研人员的工作所需,也逐步成为基层官兵学习心理知识并调整自身心态的一个有效的途径.因此,建立武警部队心理文献索引以及心理研究数据的武警部队心理数据库具有极大的实用意义.本文将主要论述如何利用垂直深度搜索引擎技术实现心理数据库的数据采集和萃取.
1 搜索引擎技术
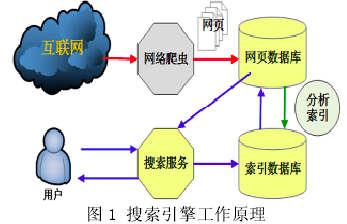
搜索引擎技术是指用户通过查询界面输入搜索信息,通过网络或数据库得到相关信息反馈的技术,搜索引擎的工作原理如图1 所示.目前常用的搜索引擎有采用通用搜索引擎技术的囊括所有学科和主题的综合性搜索(如 google、百度等)、采用垂直搜索引擎技术面向特定学科和专业的专业搜索引擎以及面向搜索引擎的搜索引擎指南.垂直搜索引擎基于结构化数据和元数据的结构化抓取,因此使抓取的数据更符合专业特点、有针对性,用户可以利用这种技术从互联网、外部数据库抓取自己需要的信息构建自己的数据库应用系统,利用垂直搜索引擎进行数据采掘的搜索引擎技术是我们实现心理数据库信息采集的基础,如图 2 所示.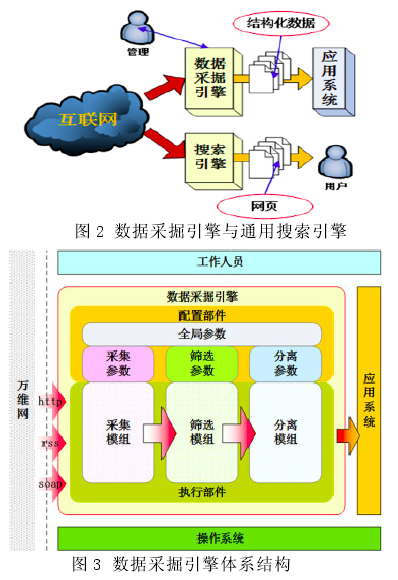
搜索引擎主要是利用爬虫(Spider)程序去自动地在互联网中搜索信息,主要有以下几个部分构成 :数据采集(抓取)、数据处理(筛选去噪去重)以及数据存储,图 3、4 分别是它的体系结构和系统结构.网页由文本、图片以及链接等元素构成,搜索引擎根据用户需求,选定一个种子,利用爬虫开始抓取页面,把符合要求的页面内容抓取到索引库 ;沿着网络上的链接从一个网页到另一个网页,遍历各个相关站点,把符合要求的页面抓取到索引库采集资料.从数据采集的角度来看,用户关心的是数据资源,Internet 上的网页以及数据库就是一个巨大的数据资源矿山,搜索引擎是开采数据资源矿山的机器,具有搜索勘探、提炼萃取、收集存储的功能.而对搜索引擎技术的研究就集中在各个采集阶段,主要涉及到爬行策略(爬虫)、分词技术、索引(存储)、排序检索算法等.
2 垂直深度搜索引擎技术与部队心理数据库
随着互联网信息化的深入发展,出现了大量业务型 Web 应用系统即 Web 数据库.这些数据库的 web 面之间的关系是非平行的垂直逻辑关系,垂直搜索引擎应运而生.它针对某一特定行业对网页库中的某类专门信息进行整合,可以定向挖掘专用数据进行处理,再以用户需要的某种形式返回给用户.武警部队心理科研成果、资源数据及心理学文献材料通常分散收录于多个文献数据库以及某些特殊数据库内,不但检索查阅不便效率低下,其覆盖范围也不足,经常存在"坏链""死链"现象 ;采取通常方法检索,其搜索结果均是基于关键字的简单拆分查询,不具备高级关键字分析处理功能,更达不到心理领域的专需效果,而且各文献数据库产品不同形式的人机交互界面(UI)也为科学检索带来了不便,因此利用垂直搜索引擎技术完成心理学专业相关的信息采集,设计并研究开发一套武警部队心理领域专需数据库,包括文献、成果、数据资源是我们的出发点.
分析搜索引擎的工作过程以及实际建库需要,其要完成的是一个人工智能系统,就是借助爬虫技术反向解析网络数据库大海中最原始的数据,取出数据,组织建立自己的数据库.也就是说爬行策略的核心是以用户关注的内容为根本,通过一种有效的方法将内容相关的 WebPage 重新分类,这需要爬虫通过多路径搜索对网页进行遍历,制定爬行策略,对每个工作步骤进行优化设计.
武警部队心理数据库所需数据目的明确、专业特性非常强,适合使用垂直搜索.在实际操作过程中,我们使用了垂直深度搜索引擎技术利用聚焦爬虫获取心理文献数据.其原理是 :爬虫要访问的文献数据库一般比较固定(如中国知网),爬取数据时,外层采用通用方法进行主题聚焦,对爬取到的数据进行特征分析,定位分析,制定爬虫爬取深度,通过一层层定位分析,将数据从最底层爬取出来.
3 性能优化的技术实现
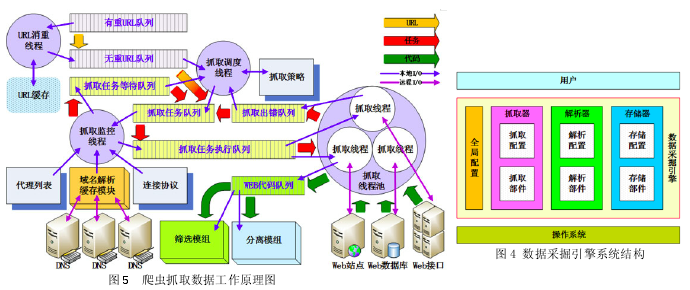
由于心理数据库主要是针对特殊站点爬取大量的原始数据,其速度、爬全率以及稳定性是我们考虑的重点,因此在我们的实验中重点做了数据采集阶段爬虫性能上的改进研究.通常数据采集阶段的爬虫使用多线程并行采集(图 5),由于这种同步方式线程太多,发一次请求响应一次,若采集量较大则需要等待挂起,会引起阻塞,造成死机现象,因此我们采取了异步非阻塞的单线程方法进行采集.这种串行异步单线程采集方式,可以连续发送请求,一次发送多个请求,进入队列进行等待回答,因此不会引起阻塞 ;另外由于抓取 URL 后系统要通过 DNS 解析分析对 URL 进行分析、消重去噪,在 DNS 解析时采取多线程分析,可以缩短系统解析时间 ;对垂直深度聚焦爬虫,由于采取的是针对某类服务器进行数据抓取,其 ip 地址固定,将 DNS 进行缓存,可以实现一次解析多次抓取的通道全连接模式,直到完成所有请求之后才断开连接,大大提高了采集性能.另外在此过程中,增加容错设计,若某一 URL 抓取不成功,设定阈值,防止死锁,并将其缓存到另一台服务器上,必要时再重新抓取.经过上述技术处理后,数据采集爬虫的性能得到了大幅提高.以下是抓取结果对比 :
4 结论与改进
搜索引擎技术的发展使得大数据时代的专需数据不至于被淹没在信息大海中采集不到,但要想数据采集的准确、全面需要在搜索引擎工作的各个阶段进行深入研究提高性能.本文采取异步非阻塞的爬行策略对心理数据库所需资源进行了垂直深度搜索,数据采集性能上有很大提高,下一步将要进行的工作是心理专用分词技术以及排序检索算法的研究.
参考文献
[1] 李晓明 , 闫宏飞 , 王继民 . 搜索引擎--原理、技术与系统(第二版)[M]. 科学出版社 .2012.5
[2] 王晓艳 , 于光华,刘双春 . 经典搜索引擎排序算法的比较与分析 [J]. 产业与科技论坛 .2012.(11).24:49-51
[3] 马慧 . 面向特定网页的 Web 爬虫的设计与实现 [D]. 吉林大学大学 .2012.12
[4] 邱晓俊 . 面向特殊主题的排序与检索算法研究 [D]. 江西理工大学 .2011.12
[5] 焦赛美 . 网络爬虫技术的研究 [J]. 琼州学院学报 .2011.(18).5:28-30
[6] 罗武,方逵,朱兴辉 . 网络搜索引擎排序算法研究进展 [J].湖南农业科学 .2010.7 :137-140
[7] 刘喜亮 . 面向主题的网络爬虫设计与实现 [D]. 湖南大学 .2009.6

经过3~5年的飞速发展,目前桌面搜索和移动搜索几乎各占半壁江山,移动搜索大有赶超桌面搜索,成为主要搜索途径之势。2013~2014年中国搜索引擎行业竞争持续升级,百度独领风骚的同时,几大追随者毫不懈怠,持续练就内功,同时借助外力,以期对百度构成威胁...

本文从卷烟企业对信息数据检索的需求出发,论述了基于Solr开发出符合自身企业的搜索引擎的可行性,介绍了有关搜索引擎及Solr的相关知识。...
0引言信息检索系统主要为互联网用户提供对资源的检索服务,用户通过输入自己想要寻找的资源信息(诸如资源的部分名称,资源内容中相关关键词等),信息检索系统根据用户提供的检索需求进行资源匹配和资源定位,并按照一定的顺序将匹配的资源反馈给用户。搜...
1引言互联网的深入发展带来了各种类型信息资源数量的快速膨胀。截至2014年6月,我国拥有273万个网站,3.3亿个IPv4地址[1].面对浩瀚巨量的网络资源,用户通过搜索引擎快速获取所需信息尤为重要。目前,我国搜索引擎用户达4.9亿;网民平均使用...
1、引言近年来,随着数字化教育浪潮的不断推进,我国在教育资源建设方面已经取得了巨大的成就,各类教育资源的数量巨大且呈现几何级数增长。随着搜索引擎技术的发展,通用搜索引擎的功能变得日益强大,取得了很大的成功,但其仍有局限性,如搜索的深度不够,...
上世纪中页,传播学家麦克卢汉曾在《理解媒介:论人的延伸》中提出:媒介是人感觉能力的延伸或扩展。这一经典概念的重要意义,在于将人的单一感官和媒体的传播特征进行了对应。例如,从视角延伸到印刷媒介,从听觉延伸到广播以及视、听觉共同延伸到电视。而...

搜索引擎经历近30年的发展,目前在使用的有几种类型,如全文搜索引擎、分类目录搜索引擎、多元搜索引擎、集成搜索引擎等。但这些都是网络上的公用商业搜索引擎,它们往往不能满足企业的需要。...
第4章模型构建及假设提出。本章在前两章文献综述和理论分析的基础上,结合访谈的结果提出了搜索引擎优化方法和效果的维度,并构建了两者的概念模型,提出了各研究变量之间的假设关系。4.1访谈。访谈法是指研究者通过面对面、QQ等访谈方式,与受访者...
在搜索引擎技术的发展之下,智能检索作为一个新型的检索方式已经渗透到了网络数据的设计中,该种检测方式能够帮助人们检测出高质量的信息,是检索方式发展的一种必然需求,将数据挖掘技术应用在网络资源可以实现智能检索的发展,也能够为人们提供出更加具有针对性...
引言随着因特网中搜索引擎的发展和进步,油田数据的资源共享以及信息的集成都较之前更加便捷和有效了。从因特网搜索引擎的思想出发,借助SES系统的数据采集和搜索的机制,并且结合油田的信息和数据的共享的特点,制定了一套从结构体系好以及安全智能为主要...