搜索引擎论文


1、引言
1.1研究背景
搜索引擎已经成为了人们获取信息的必不可少的工具。根据CNNIC发布的2011年年度报告,截至2011年底,中国网民规模已经达到了5.13亿人,其中搜索引擎的使用率达到了79.4%,在互联网应用中排名第二。与此同时,网络资源也在迅速膨胀,如何准确理解用户的检索需求并快速而有效的帮助用户找到信息目标仍然是搜索引擎面临的挑战,而搜索性能的评价也就受到越来越多的重视。
目前,作为一种主流发展方向,基于用户行为分析的方法已经开始被应用到搜索引擎查询性能的评价上。然而,目前已有的搜索引擎性能评价的研究还只是主要集中于查询频度比较高的查询词上,对于长尾查询来说,缺少大量的用户检索行为的数据,因此简单照搬用户行为分析的方法并不可靠,这也是长尾查询性能评价的难度所在。
实际上,由于高频查询词随着时间的变化不大,很多商业搜索引擎通过人工标注的方法对高频查询词进行了优化,或者通过用户反馈不断调整高频查询的结果排序,在高频查询上各个搜索引擎已经做得非常好了。因此,真正影响用户的体验很大程度上取决于低频查询的搜索性能。我们知道,搜索引擎的查询的分布遵循幂律分布,而同时其也遵循齐普夫定律。据前人的统计发现,几乎所有搜索引擎用户都有长尾查询的需求。因此,长尾查询的搜索性能的评价也逐渐被搜索引擎重视起来。
本文工作就是在长尾查询的评价这一挑战性问题方面的一个探索和尝试。我们通过大规模的数据分析,结合内容和用户行为两个方面的信息,提出包括来自搜索引擎排序、结果呈现、以及用户点击行为等多种类型的、适用于搜索引擎长尾查询评价的特征,并将它们用于搜索引擎结果的自动评价,取得了令人鼓舞的效果。
1.2相关研究
在19世纪五六十年代,英国的Cranfield工程建立了Cranfield的评价体系,应用于信息检索等相关的领域。该评价体系的一项重要工作是标注人员需要在语料库中标注出查询样例对应的答案集合。标注人员可以根据需要进行不同等级的标注(比如5级标注)。
针对搜索引擎的性能评价,人们又提出了用户满意度的概念。然而,到目前为止,仍然没有一个明确的用户满意度的定义和标准。一方面,用户满意度仍然是基于结果的相关性,使用NDCG等指标进行评价;另一方面,也有研究提出用户满意度是一个主观变量,要综合考虑检索系统的各种指标以及用户个性化的因素来进行衡量,但是在实际的实验中,仍然是通过对用户检索出的结果分别评价来进行最终评判。
然而,由于搜索引擎具有海量数据,同时数据资源还在不断爆炸式增长,人工标注有着明显的缺点:耗费时间、人力、财力。鉴于人工标注有着巨大的困难,人们开始研究自动标注以替代人工标注。其中用户行为分析起到了重要的作用,主要包括用户查询需求分析和用户点击行为分析。当前一些基于用户行为分析的方法已经能够实现搜索引擎的自动 性能评价,例如,Liu等在2007年的 工 作等。但是在这些工作中,均首先排除了长尾查询,而只关注查询频度较高的热门或常见查询。
在长尾查询方面,由于被人们关注的时间不长,在这方面的研究并不多。目前主要相关研究工作体现在三个方面,广告搜索,查询推荐,以及长尾查询的用户行为分析。在长尾查询的用户行为分析方面,Yao等人对长尾查询及热门查询的用户行为进行了较全面的对比分析,得到了一些有意义的结论,这对本文工作也有一定的启发。
分析以上的相关工作可以发现,在搜索引擎的高频查询性能评价方面,前人已经做了很多工作,相应的评价技术已经较为成熟。而对长尾查询的研究也只是体现在查询推荐和广告搜索的扩展上,在长尾查询性能评价方面的工作还非常缺乏。长尾查询与高频查询相比,在特征方面存在着很大的差异。例如,长尾查询的查询词长度会更长,长尾查询返回的结果数目会相对较少,长尾查询返回的结果列表上的用户首次点击位置会更偏下等等。由于存在着这些差异,评价高频查询的特征也很难直接用来评价长尾查询,因此,我们的工作首先要通过对长尾查询的数据进行分析和调研,找到影响长尾查询搜索性能的因素,提取出相应的特征,从而建立起对长尾查询搜索性能的评价体系。
2、数据集
我们在某公司的协助下获得了2011年3月至2012年3月的部分查询结果的标注数据,以及相应时间段内的用户点击日志。其中每个月有约1 000个查询词,每个查询词对约15个文档进行5级相关度人工标注,标注分值为0,2,3,4,5,其中分值越高相关度越高,标注为0的表示不相关。这些查询既包括了长尾查询,也包括了中频查询和高频查询(依照惯例,将半年内查询频度大于100的分为高频查询,查询频度在20~100之间的分为中频查询,查询频度小于20的分为长尾查询。如果没有特殊说明,在后续实验中我们对于不同频度查询的定义均按照此标准)。同时,我们也抓取了这些查询词的搜索引擎结果展示页面以及搜索引擎排序值结果页面,作为特征分析的候选集合。
3、搜索引擎长尾查询评价方法
对于查询结果的评价主要可以从两个方面进行,一个是查询粒度结果满意度评价,另一个是查询-文档对粒度的文档相关度评价。在目前的搜索引擎性能评价方法,主要是基于查询-文档对粒度的相关度评价。长尾查询在查询粒度上并没有特别突出的特征,因此,我们的工作也是从查询-文档对的相关度评价展开的,这也是查询粒度满意度评价的基础。
3.1特征提取
3.1.1点击特征
用户点击行为在高频查询的评价中是非常有效的。对于长尾查询,虽然其点击数据非常稀疏,但是我们还是希望能够从其中获取一些有效信息。我们提出使用如表1所示的两个点击特征,并统计了两个点击特征在不同相关度文档上的分布情况,给出了点击特征1(Click_Attr1)的箱形图。
从图1中可以看出,相关度为5的特征值明显要高于其他相关度的特征值,这应该和相关度为5的文档的质量明显非常好有关。从整体趋势来看,随着相关度的升高,特征值的均值和中位数都有升高的趋势。不过相关度为0的文档的特征值虽然是最低的,但是其与相关度为2和3的文档差异并不是十分明显,这说明,我们的特征虽然能体现相关度,但是特征的区分度并不是很大。
3.1.2标红特征
在以前的工作中发现,搜索引擎结果列表的展示对用户体验是有影响的,而标红部分覆盖查询词的比例有比较明显的影响。为此,我们从标红部分这一指标中进行了特征提取。
搜索引擎给出结果的同时,标题和摘要中与查询词重叠的部分会标红。为此,我们提取了体现标红部分覆盖比例的三个特征,在提取过程中,这些标红信息都进行了去重处理。同时,也发现标红部分的顺序也会影响其与原查询的相关度,因此,我们采用标红部分与查询词的编辑距离相关的特征来体现标红部分与查询的匹配度及顺序的影响。表2给出了标红特征的描述,分别统计了每个特征下相关的结果文档与不相关的结果文档的相应特征值分布,图2给出了部分标红特征的分布图。
结合考察特征过程中统计得到的分布图,我们发现,相关的结果文档和不相关的结果文档在这6个特征上的分布的差异是比较明显的。在体现标红部分覆盖查询词的比例的三个特征中,标题中标红部分覆盖查询词的比例与标题中最大连续标红部分覆盖查询词的比例相对来说更加明显,而后者尤为显著。同样,在体现标红部分与查询词的顺序关系的三个特征中,也具有类似的结果。因此,我们可以看出,标题中最大连续标红部分对结果文相关性影响是最大的,其次是标题中的标红部分,而摘要中的标红部分影响最弱。
3.1.3排序特征
搜索引擎在返回用户结果文档列表时,会根据每个文档与查询的相关度对文档进行排序。这种排序(Rank)是搜索引擎系统中最核心的一个模块。
我们获取了每个结果文档的一系列重要排序值,包括PageRank值、正文匹配度值、点击排序值、综合排序值等。这些排序值体现了该文档与相应查询的相关度,从而用于结果的排序。我们将每一个排序值作为一个特征,用这些特征对我们的结果文档进行相关度分类,也是作为我们相关度评价的一个基线。我们做出了各个排序值在不同相关度上的分布箱线图,多数排序值的分布随着相关度的增加有升高的趋势,但很不明显。这也从反映出搜索引擎对于长尾查询结果的排序值计算并不准确,体现了长尾查询相关度评价的难度。
3.2数据不平衡处理
在我们的数据集中,每一个查询-文档对都是带有五级相关性标注的,而一般在性能评价中通常更关注不相关或非常相关的结果,因此,我们将这一数据集划分为了三个类别:4和5划分为非常相关,称为类别2;2和3划分为一般相关,称为类别1;0划分为不相关,称为类别0(后文实验中如无特殊说明,均采用这样的类别划分)。
我们知道,一般的分类方法都会在假设类分布平衡,样本数据大致相当时,具有较好的精度。而我们的数据中,不同相关度的文档数目有着非常大的差异,一般相关的数据数目是不相关数据数目的近10倍,如果直接使用这些数据去训练分类器,必然会存在很大的偏置。为此,我们必须要进行数据平衡的处理。
在处理数据平衡方面,有两种较为常用的方法。
一种是通过增加正类样本数目(样本数目少的称为正类,数目多的称为负类),来弥补与负类的差距以达到数据平衡。增加正类样本数目的方法是通过随机抽取正类中的样本增加到正类中;另一种方法是进行多次抽样,得到多个训练集,每一个训练集包括全部的正类样本和从负类样本中随机抽取的相同数量的样本加入到训练集。然后对每一个训练集分别学习一个分类器,通过投票的方式对测试集进行分类。其中抽样的训练集数目与数据不平衡的程度有关。通过在数据集上分别测试两种数据平衡方法,在样例数目较少的不相关文档上的精度有比较明显的提升,在后续工作中,我们采取了第二种平衡方法。工作中,我们仅对训练集进行了数据平衡处理,测试集仍保留原来的正负类比例,因此,并不影响我们的方法应用于真实标注的数据。
3.3评价算法的优化
基于上述分析,不难看出对于长尾查询评价这一挑战性问题来说,虽然不同的特征都具有一定的区分度,但是每个特征的效果并不足够理想,而每个特征所能够识别和区分的查询也有所差异。因此我们采用集成学习的思路,将每个特征(或每组特征组合)看作是一个弱分类器,总体上在数据平衡的基础上进行多分类器的融合。同时,我们也对算法进行了优化,每个分类器的权重并不是一样的,而是取其在训练集上的精度作为其权重。表3介绍了优化后评价算法的流程。


4、实验结果与分析
4.1特征叠加的结果
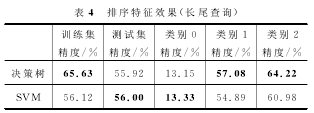
排序特征的评价效果是我们实验的基线。在这一部分,我们分别测试了三类特征各自的效果,两两组合的效果以及三类特征叠加起来的效果。测试时,对数据进行了归一化处理,采用了数据平衡方法,多次采样训练了50个分类器,以投票结果作为分类结果,使用了决策树和SVM两种分类算法,记录了训练集和测试集的精度,以及测试集上每一个类别的精度。
这里我们给出了搜索引擎排序特征的结果如表4所示以及三类特征叠加的结果如表5所示,可以看出测试集上的精度有大概2%的提升。虽然我们的精度只有不到60%,但是相对于基线(基于搜索引擎排序特征的效果)是有提升的,这也是长尾查询的特征稀疏性明显,评价难度大的结果。
4.2评价算法的投票方式优化结果
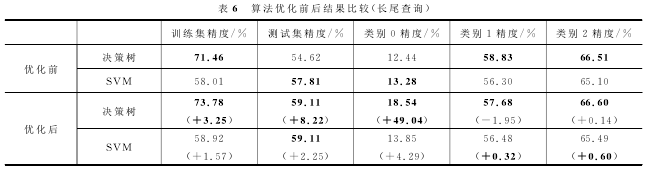
如表6所示,优化后的算法相比之前使用SVM在整体精度上有了2.25%的提升,使用决策树在整体精度上有了8.22%的提升,类别0的精度也有了明显的提高,使用决策树在类别0上的精度有了近50%的提升。其中,提升幅度=(优化后精度-优化前精度)/优化前精度,在优化之后,决策树的结果有了明显的改善,甚至比SVM更好。
4.3二分类效果分析的结果
考虑到在搜索引擎的实际应用中,找出相关度最差的结果文档是更有意义的。为此,我们也考察了长尾查询性能评价工作中对挑出最不满意的查询的效果。因此对数据集重新分为了两个类别,即原标注为0的定义为不相关,记为类别0;其他的为相关,记为类别1。对于找出的不相关的文档,我们更关注其准确率,即找到的不相关文档确实就是不相关的,尽可能少的把相关的文档误分为不相关。
实验结果表明在不相关文档这一类别上,我们使用二分类的精度达到了75%,相比之前的18.54%有了很大的提升,也说明我们的算法能够更加准确的找出不相关的结果文档。
5、结论
本文旨在研究长尾查询的评价方法,对长尾查询结果文档进行更加有效的相关度评价。由于长尾查询方面没有工作基础,从长尾查询数据分析入手,提取了三种类别的特征,并进行分析,分析过程中,对不同特征组合进行了测试。针对数据集存在的严重不平衡问题,提出了数据平衡方法和基于集成学习的评价算法,并对算法进行了改进,使评价精度有了一定的提升。进行二分类评价,对不相关文档的评价精度能达到一个较高的水平。
就目前的工作来看,我们的评价方法比搜索引擎自身的评价有了一定的提高,虽然准确率提高的幅度并不大,但是在长尾查询的特征如此稀疏的情况之下,能达到这样的效果已属不易。在接下来的工作中,我们一方面需要继续通过特征提取或算法优化来提高整体的评价精度,另一方面,对于找出相关度最差的文档有着更重要的意义。如果能够在保证准确率的前提下,提高相关度最差的文档的召回率,那么对于评价长尾查询的查询性能和改善搜索引擎的用户体验是有很重要意义的。

经过3~5年的飞速发展,目前桌面搜索和移动搜索几乎各占半壁江山,移动搜索大有赶超桌面搜索,成为主要搜索途径之势。2013~2014年中国搜索引擎行业竞争持续升级,百度独领风骚的同时,几大追随者毫不懈怠,持续练就内功,同时借助外力,以期对百度构成威胁...

本文从卷烟企业对信息数据检索的需求出发,论述了基于Solr开发出符合自身企业的搜索引擎的可行性,介绍了有关搜索引擎及Solr的相关知识。...
0引言信息检索系统主要为互联网用户提供对资源的检索服务,用户通过输入自己想要寻找的资源信息(诸如资源的部分名称,资源内容中相关关键词等),信息检索系统根据用户提供的检索需求进行资源匹配和资源定位,并按照一定的顺序将匹配的资源反馈给用户。搜...
1引言互联网的深入发展带来了各种类型信息资源数量的快速膨胀。截至2014年6月,我国拥有273万个网站,3.3亿个IPv4地址[1].面对浩瀚巨量的网络资源,用户通过搜索引擎快速获取所需信息尤为重要。目前,我国搜索引擎用户达4.9亿;网民平均使用...
1、引言近年来,随着数字化教育浪潮的不断推进,我国在教育资源建设方面已经取得了巨大的成就,各类教育资源的数量巨大且呈现几何级数增长。随着搜索引擎技术的发展,通用搜索引擎的功能变得日益强大,取得了很大的成功,但其仍有局限性,如搜索的深度不够,...
上世纪中页,传播学家麦克卢汉曾在《理解媒介:论人的延伸》中提出:媒介是人感觉能力的延伸或扩展。这一经典概念的重要意义,在于将人的单一感官和媒体的传播特征进行了对应。例如,从视角延伸到印刷媒介,从听觉延伸到广播以及视、听觉共同延伸到电视。而...

搜索引擎经历近30年的发展,目前在使用的有几种类型,如全文搜索引擎、分类目录搜索引擎、多元搜索引擎、集成搜索引擎等。但这些都是网络上的公用商业搜索引擎,它们往往不能满足企业的需要。...
第4章模型构建及假设提出。本章在前两章文献综述和理论分析的基础上,结合访谈的结果提出了搜索引擎优化方法和效果的维度,并构建了两者的概念模型,提出了各研究变量之间的假设关系。4.1访谈。访谈法是指研究者通过面对面、QQ等访谈方式,与受访者...
在搜索引擎技术的发展之下,智能检索作为一个新型的检索方式已经渗透到了网络数据的设计中,该种检测方式能够帮助人们检测出高质量的信息,是检索方式发展的一种必然需求,将数据挖掘技术应用在网络资源可以实现智能检索的发展,也能够为人们提供出更加具有针对性...
引言随着因特网中搜索引擎的发展和进步,油田数据的资源共享以及信息的集成都较之前更加便捷和有效了。从因特网搜索引擎的思想出发,借助SES系统的数据采集和搜索的机制,并且结合油田的信息和数据的共享的特点,制定了一套从结构体系好以及安全智能为主要...