搜索引擎论文


1 网络爬虫的历史及现状
网络爬虫是一个自动提取网页的程序,如果把互联网比喻成一个蜘蛛网,那么爬虫就是在网上爬来爬去的蜘蛛。传统爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的 URL放入队列,直到满足系统的一定停止条件。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。随着互联网全面从 Web1.0 时代迅速进入Web2.0 时代,由于 Ajax 异步加载的特性,为减轻服务器压力,基于 Ajax 的动态加载技术方案成为了个大公司的首选。然而随着移动互联网的兴起 JavaScript 在移动端和 PC 客户端的优良特性被广泛挖掘,基于前端 MVC/MVVM 的模式逐渐进入各大互联网公司的首选解决方案。
数据显示 2011 年互联网上动态网页与静态网页的比例为12.1:1 到 2014 年动态网页与静态网页的比例攀升到 22:1.
动态网页的急剧攀升让各大搜索引擎公司愈发感觉到基于动态Web 页面的网络爬虫将越来越重要。
2 问题现状及解决方案
2.1 问题现状
传统的网络爬虫技术主要应用于抓取静态 web 网页,由于Ajax 改变了以往的单纯的 HTTP 请求 / 响应协议机制。传统的爬虫根据 url 抓取页面并解析页面内容提取新的 url 进行下一步抓取的机制很难完成。其次,如今互联网中存在许多对实时性要求比较高的网站,如股票、火车票等。这些网站包含大量的数据信息,并且在随着服务器端不断的更新。当搜索引擎抓取这些数据时,由于需要将数据下载到本地,因此永远存在数据的同步性的问题,然而这些实时性数据的商业价值却非常大。
因此简单的讲,当前的搜索引擎爬虫系统遇到动态 web 页面时的主要问题集中在:(1) 无法提取 Ajax 加载的动态页中的url.(2) 无法抓取实时性数据。
2.2 网络爬虫关键技术
(1)基于 HTTP 请求响应模型。用户在浏览器中输入一个web 页面的 url, 客户端向服务器端发出一个请求,服务器在接收到该请求后,如果没有错误将页面返回。
(2)HTML 标签及结构。用户在页面上看的展示都是基于HTML 进行展示的,因此爬虫需要对 html 页面进行解析,提取页面中的 url 信息。
(3)文本对象模型 (DOM)。DOM 是用来访问和处理HTML 和 XML 文档的。它可以将 HTML 和 XML 文档结构化。
(4)正则表达式。根据正则表达式的优良特性,可以根据条件快速提取 HTML 文本中的指定元素。
2.3 解决方案
AJAX 采用了 JavaScript 驱动的异步请求 / 响应机制。并且,在 Ajax 应用中,JavaScript 会对 DOM 结构进行大量的变动,甚至页面所有内容都是通过 JavaScript 直接从服务端读取并动态绘制出来的。因此爬虫引擎不能仅仅是基于 HTTP 的协议驱动,而必须是基于事件驱动的。
针对实时性数据, 系统的实时特性主要体现在两个方面:数据更新的实时性;数据变化后通过其它服务的实时性。
在海量的数据面前,由于抓取能力有限,根本无法满足快速地更新所有的数据信息,为了保证用户对于数据高实时性的要求,应该尽可能地优先保证热门数据的数据更新,所以实时抓取的数据点选择是比较关键的。在这里我们使用购物助手的浏览记录以及购物搜索的查询记录当作热门商品为例说明。具体流程为:用户浏览某商品,购物助手获取该用户所浏览的商品 URL 以及其它商城该商品的 URL 列表发送到任务调度服务器,任务调度服务器根据上一次抓取的价格时间等信息来进行调度,将任务分配至抓取服务器,抓取服务器解析到新的价格后发送到结果入库服务器。结果入库服务器完成数据的更新,并通知其它价格事件监听程序。这就完成了整个基于查询驱动的实时抓取的过程。这种实时抓取策略就叫做“查询驱动抓取”(简称 QTC,Query Triggered Crawling)。价格服务器除了实时抓取和管理所有商品的价格之外,还需要向其它服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何使得其它服务可以实时地得到商品的价格变化信息呢?我们首先介绍一下观察者模式。
观察者模式(也被称为发布 / 订阅模式)是软件设计模式的一种。在此种模式中,一个目标对象管理所有相依于它的观察者对象,并且在它本身的状态改变时主动发出通知。这通常透过呼叫各观察者所提供的方法来实现。此种模式通常被用来实作事件处理系统。观察者模式已经在数据变化的实时通知方面被广泛地应用,它使得服务具有高类聚、低耦合的特点。
根据不同的应用,爬虫系统在许多方面存在差异,大体而言,可以将爬虫划分为如下三种类型 :批量型爬虫(Batch Crawler):批量型爬虫有比较明确的抓取范围和目标,当爬虫达到这个设定的目标后,即停止抓取过程。至于具体目标可能各异,也许是设定抓取一定数量的网页即可,也许是设定抓取消耗的时间等。
增量型爬虫(Incremental Crawler):增量型爬虫与批量型爬虫不同,会保持持续不断的抓取,对于抓取到的网页,要定期更新,因为互联网的网页处于不断变化中,新增网页、网页被删除或者网页内容更改都很常见,而增量型爬虫需要及时反映这种变化,所以处于持续不断的抓取过程中,不是在抓取新网页,就是在更新已有网页。通用的商业搜索引擎爬虫基本都属此类。
垂直型爬虫 (Focused Crawter):垂直型爬虫关注特定主题内容或者属于特定行业的网页,比如对于在线旅游来说,只需要从互联网页而里找到与在线旅游相关的页面内容即可,其他行业的内容不在考虑范围。垂直型爬虫一个最大的特点和难点就是:如何识别网页内容是否属于指定行业或者主题。从节省系统资源的角度来说,不太可能把所有互联网页面下载下来之后再去筛选,这样浪费资源就太过分了,往往需要爬虫在抓取阶段就能够动态识别某个网址是否与主题相关,并尽量不去抓墩无关页面,以达到节省资源的目的。垂直搜索网站或者垂直行业网站往往需要此种类型的爬虫。
3 结语
针对使用 JavaScript 的动态页面的抓取,主要采用的技术方案为:(1) 基于事件驱动的爬虫机制。(2) 使用观察者模式以及查询驱动抓取方式来抓取实时性数据。并介绍了当前流行的爬虫抓取方案。

在计算机技术以及网络技术特别是移动通信技术不断发展的背景下给智能手机带来了极大的发展空间。目前性能过剩已经成为了当前智能手机的普遍问题之一,硬件功能过于强大的背后反而是软件不能跟上步伐,这也就导致了用户的体验性出现了一定程度的下降。在人机...
搜索引擎是我们工作、学习和生活中必不可少的实用性技术,正如一个调查中所显示的,85%的人都是通过搜索引擎获取到他们所需要的信息和所喜爱的网站,可见搜索引擎的重要性。随着智能技术的不断更新,人们的生活变得越来越智能,对搜索引擎的要求也会随之越来...

本文在原有的中文抄袭检测源检测算法的基础上, 通过实验分析比较各种分词工具和词性标注工具的优缺点, 选取针对高模糊抄袭以及网络抄袭的行之有效的关键词提取方法。CNKI虽然能检测出大部分的中文抄袭, 但面对基于web抄袭的现象显得力不从心。...
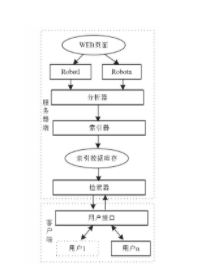
首先Web信息检索挖掘技术做了简要概念,其次对基于Web挖掘的网络搜索引擎技术的应用进行了分析,提出了一种给予Web挖掘的个性化搜索引擎,并对各系统模块的功能及实现方式进行研究,分析结果表明,此种系统具有很强的检索灵活性,而且还能实现个性化查询结果...
1引言在这个信息爆炸的时代,搜索引擎已经成为一个新兴而重要的计算机应用领域,更是成为全球资本关注的一个亮点.搜索引擎克服了数据库中存在的不足,为数据的检索提供了更为方便快捷的方式.搜索引擎是以一定的策略在指定的搜索空间上收集和查找信息,对信...

基于新的指令集架构优化倒排索引压缩算法的数据处理能够进一步提升压缩和解压性能.单纯采用高级语言提供的库函数实现的倒排索引压缩算法对数据的操作粒度较粗,不利于倒排索引压缩算法的性能优化....
在Web2.0与大规模协同计算环境当中,用户的在线信息搜索活动发生了深刻的变革作为一种新型的Weh搜索模式,从提出到现在10年左右的时间里,社会化搜索(SocialSearch)得到国内外诸多学科领域研究者们的广泛关注所谓社会化搜索,是指Weh2.0当中的用户彼此...
0引言面对着海洋似地互联网数据,用户要查询到自己所需要的信息,如同在大海里捞针,而搜索引擎技术的出现恰好解决了这一难题。搜索引擎技术目前已经成为研究开发的热点领域。一个成功的优秀的搜索引擎能够对互联网上的信息经过特定的检索策略,对各类信...