硕士论文

摘 要
随着智慧城市建设的发展,城市街景作为一种全新的地图服务方式应用在城市建设中,影像服务的主要方式为街景影像地图浏览服务,其中物体目标检测是目前计算机视觉研究的热门方向之一.城市街景中目标检测已经成为城市治理能力综合提升的重要环 节.但目前在街景影像中要实现良好的目标检测效果仍然存在一些问题,例如街景背景复杂性,影像检索时间长,复杂场景下的行人、车辆检测面临着尺度变化、外观姿态变化、目标重复和遮挡等.
针对街景影像中目标检测存在的问题,本文研究一种改进 Yolo V3 深度学习算法,对街景影像中的行人车辆信息进行检测,提升目标检测的速度与精度.本文主要开展的研究内容如下:
1.对目标检测的发展历程进行了系统概述.从理论部分对传统目标检测的基本流程以及框架结构进行阐述和对深度学习主要部分卷积神经网络进行介绍.并通过对深度学习中两类主要代表性算法进行分析,作为文章实验结论的对比部分.
2.根据城市街景影像的行人车辆检测的特点,提出一种改进算法,主要从精度与速度方面对 Yolo V3 算法进行改进,精度方面引入高级语义嵌入(SEB)的思想,将图像高层特征与低层特征进行融合.速度方面引入轻量级检测端的思想,提升图像输出结果的速度.在实验部分进行不同算法之间的对比,验证改进算法的真实有效性.结论为在街景影像数据集上 MAP 值达到了 66%,Mean Precision 值达到了 85%.
由于研究内容主要为城市街景影像中的行人车辆目标检测,针对实验不同深度学习算法数据集的选择需要满足场景下目标检测的要求,一类采用公开 KITTI 数据集,数据集共选择具有代表性的图像 7000 多张,并且进行图像数据集格式的转化用来进行算法的网络训练过程.另一类采用北京市西城区道路街景影像数据信息,数据集共选择具有代表性的图像 4000 多张,需要对影像数据集中的行人车辆信息进行数据集的标注参与网络训练.最后通过精度、速度评价指标以及图像输出结果得到改进算法对于街景影像中行人车辆中具有良好的检测性能.
关键字:城市街景影像,行人车辆检测,影像数据集,高级语义嵌入
Abstract
With the development of smart city construction, Urban street view images, As a new wayof map service, are applied in city construction. The main way of image service is street viewimages map browsing service. Object detection in street view images map browsing service isone of the popular directions of computer vision research. Object detection in urban street viewhas become an important part of comprehensive improvement of urban governance ability.However, there are still some problems to achieve the object detection effect in the street viewimages: the background complexity of the street view, the image retrieval time is long, thepedestrian and vehicle detection in the complex scene are faced with the scale changes,appearance and attitude change, target repetition and occlusion.
Aiming at the problems of object detection in street view images, this paper studies animproved Yolo V3 deep learning algorithm to detect pedestrian and vehicle information in streetview images and improve the speed and accuracy of object detection. The main researchcontents of this paper are as follows:
1.The development course of target detection is systematically summarized. This paperexpounds the basic flow and frame structure of traditional object detection from the theoreticalpart and introduces the convolutional neural network, the main part of deep learning. And twomain representative algorithms in deep learning are analyzed as the comparison part of theexperimental conclusion of this paper.
2.According to the characteristics of urban street view images object detection, animproved algorithm is proposed, which mainly improves the Yolo V3 algorithm from the aspectof precision and speed.This paper introduces the idea of advanced semantic embedding (SEB)in the aspect of precision, and fuses the high-level features and low-level features of the image.In terms of speed, the idea of lightweight detection end is introduced to improve the speed ofimage output. In the experimental part, different algorithms are compared to obtain the realeffectiveness of the improved algorithm. The results showed that the MAP value reached 66%and the Mean Precision value reached 85% on the street view images data set.
The main research content for the object detection is in the city street view images.According to different experimental data set deep learning algorithm to meet the requirementsof scenario object detection, One adopts the public KITTI data set, This data set choose thetypical image of more than 7000 images data sets and format conversion to the network trainingprocess of the algorithm. The other uses the road street view images data of Xicheng District,Beijing. More than 4,000 representative images are selected from the data set. It is necessary tomark the data set of pedestrian and vehicle information in the image data set and participate innetwork training. Finally, the improved algorithm is obtained by using the precision, speedevaluation index and the output result of the image. It has good detection performance forpedestrians and vehicles in street view images.
Keyword: Street view images; Pedestrian and vehicle detection; Image data set;Semantic Embedding Branch.
目 录
摘要..................................................... I
Abstract ................................................. Ⅱ
第 1 章 绪 论 ............................................. 1
1.1 研究背景与意义 .............................................. 1
1.2 国内外研究现状 .............................................. 2
1.2.1 行人检测研究现状....................................... 2
1.2.2 车辆检测研究现状....................................... 4
1.3 研究内容及技术路线 .......................................... 5
1.3.1 研究内容............................................... 5
1.3.2 技术路线............................................... 6
1.4 论文结构安排 ................................................ 7
第 2 章 目标检测算法理论.................................. 9
2.1 目标检测算法概述 ............................................ 9
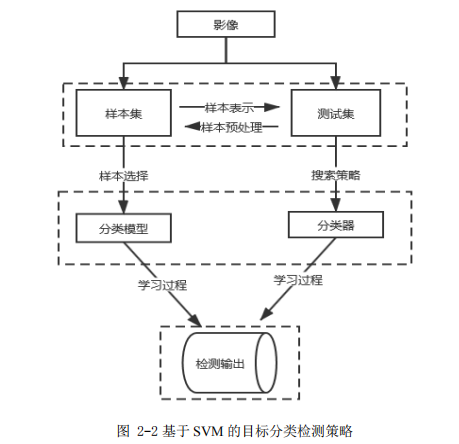
2.2 传统目标检测算法框架 ........................................ 9
2.2.1 定位目标............................................... 9
2.2.2 特征提取............................................... 9
2.2.3 分类器分类............................................ 11
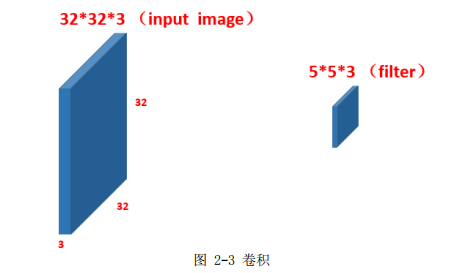
2.3 卷积神经网络介绍 ............................................ 13
2.3.1 卷积计算 .............................................. 13
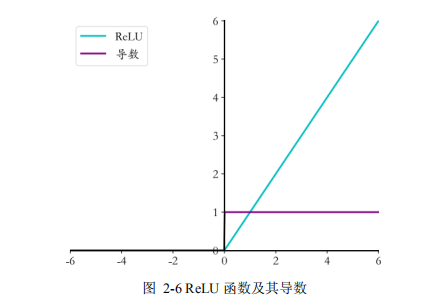
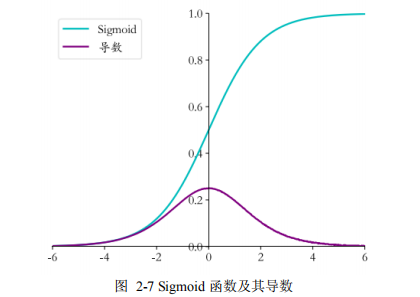
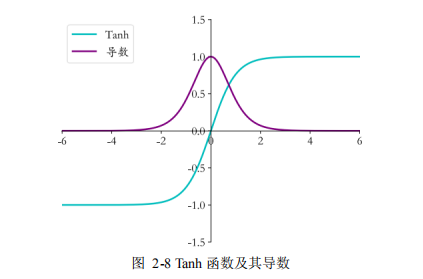
2.3.2 激活函数 .............................................. 15
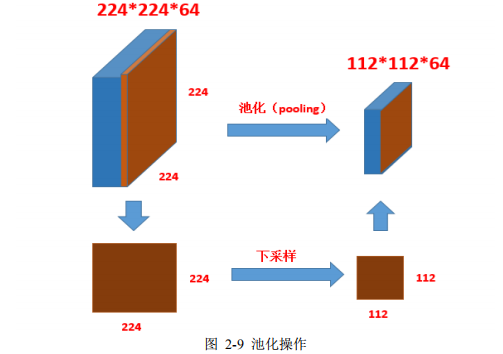
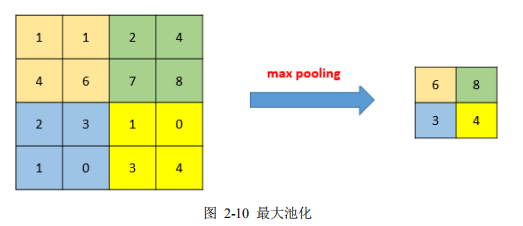
2.3.3 池化 .................................................. 16
2.4 深度学习目标检测算法 ........................................ 18
2.4.1 Two-Stage 目标检测算法 ................................ 18
2.4.2 One-Stage 目标检测算法 ................................ 19
2.5 精度评价指标 ................................................ 20
2.6 本章小结 .................................................... 22
第 3 章 行人车辆检测算法研究与改进 ....................... 23
3.1 Faster R-CNN 算法 .......................................... 23
3.1.1 CNN 特征提取过程 ....................................... 23
3.1.2 RPN 网络 ............................................... 24
3.1.3 分类与回归 ............................................ 25
3.2 YOLO 系列算法............................................... 25
3.2.1 Yolo V1 算法 ........................................... 26
3.2.2 Yolo V2 算法 .......................................... 26
3.2.3 Yolo V3 算法 ........................................... 27
3.3 现有算法局限及改进思路 ................................... 30
3.3.1 局限性 ............................................. 30
3.3.2 改进思路 ........................................... 31
3.4 改进 YOLO 算法 ............................................. 32
3.4.1 高级语义嵌入(Semantic Embedding Branch/SEB) ...... 32
3.4.2 轻量级检测端 ....................................... 35
3.5 改进 YOLO 算法实验分析 ..................................... 38
3.5.1 实验目的............................................. 38
3.5.2 网络训练框架......................................... 38
3.5.3 实验数据集........................................... 39
3.5.4 实验结果输出......................................... 39
3.6 本章小结 .................................................. 40
第 4 章 基于改进算法的街景行人车辆检测实现 ............... 41
4.1 常见数据集 ................................................. 41
4.1.1 行人数据集............................................ 41
4.1.2 车辆数据集............................................ 41
4.2 数据集训练 ................................................. 42
4.2.1 KITTI 数据集简介 ...................................... 42
4.2.2 数据集格式转化........................................ 43
4.2.3 代码实现.............................................. 45
4.2.4 训练结果分析与评价.................................... 47
4.3 西城区街景影像获取 ......................................... 52
4.4 数据集标注 ................................................. 53
4.4.1 标注工具.............................................. 53
4.4.2 影像数据集类别标注................................... 54
4.5 测试数据集算法实现 ......................................... 55
4.5.1 开发环境.............................................. 55
4.5.2 Faster R-CNN 算法代码实现 ............................. 56
4.5.3 Yolo 算法代码实现 ..................................... 57
4.6 测试数据集精度评价实现 ..................................... 59
4.6.1 精度指标评定.......................................... 59
4.6.2 速度指标评定.......................................... 61
4.6.3 实验结果分析.......................................... 62
4.7 本章小结 ................................................... 65
第 5 章 结论与展望....................................... 66
5.1 研究结论 ................................................... 66
5.2 后续研究展望 ............................................... 66
参考文献................................................ 68
攻读硕士期间发表论文及科研情况.......................... 73
致谢.................................................... 74
第 1 章 绪 论
1.1 研究背景与意义
随着智慧城市建设的发展,获取当前环境的位置信息有着重要作用.目标检测从提出之初就成为了广泛研究的热点,尤其在自然场景下有更加广泛应用.图像检测技术主要通过摄像机获取图像作为原始图像,并在原始图像上进行目标检测实现[1].其中应用在城市建设中的影像服务方式主要是城市街景影像,城市街景作为一种全新的地图服务方式,从推出以来就被寄予更多关注.街景影像地图浏览服务通过对城市主要组成道路,建筑等目标进行拍摄,然后将这些照片经过处理,再根据实际需求应用于地图浏览与地图使用服务.
作为城市街景影像,同样存在大量目标检测研究内容,其中行人车辆信息构成了街景环境中重要的组成部分,针对城市街景中行人车辆检测已经成为城市治理能力综合提升的重要环节,对于提升城市品质具有不可替代的作用.城市街景影像虽然在为城市综合服务方面提供了便利,但目前在影像中要实现良好的目标检测效果仍然存在一些问题,具体在城市影像行人车辆定位中的问题有:1.街景背景复杂性:相较于普通图像,街景中存在大量的目标,如行人、车辆、建筑物、交通标志等等,在考虑实际定位过程时,需要从复杂的背景中提取出来我们想要获取的目标信息,但是由于背景复杂性,在匹配过程中容易出现匹配错误的现象.2.影像检索时间长:获取大量的街景数据信息,采用对图像的单一特征进行提取研究(例如角点、直线、纹理)导致目标检测时间更长.同 时不同大小,外观,光照遮挡等现象的存在导致在目标检测的准确性上无法保证.3.影像目标尺度变化较大:复杂场景下的行人、车辆检测面临着尺度变化、外观姿态变化和遮挡等问题.例如存在较远处的小目标行人、车辆被归为小尺度信息难以被识别.另外密集场景下目标之间互相遮挡,使得算法很难做出较为准确全面的检测,影响算法的精度,导致结果不准确.
与此同时,以机器学习、知识图谱为代表的人工智能技术逐渐变得普及.从最初的简单目标分类识别、发展到后续的图像综合应用,再到实际应用场景下的自动驾驶,逐 渐渗透到人们的日常生活中.可见计算机视觉是一门使机器"看"的学科.它使计算机和其他设备代替人眼进行目标检测和进一步的图像处理[2].图像处理和计算机视觉成为研究的新趋势,用于构建人工智能系统从图像中获取信息等智能交通监控系统.目标检测也逐渐成为计算机视觉的一个重要分支.在不断地发展中,其中基于深度学习的目标检测在速度和精度方面的表现要优于传统的特征提取算法.
基于以上背景,本文利用城市街景影像,研究一种对于街景影像行人车辆目标检测的深度学习方法.旨在解决城市街景影像中由于背景复杂,遮挡尺度变化问题带来的目标检测精度问题.
1.2 国内外研究现状
在影像目标检测课题发展的四十余年中,行业内众多学者取得了优秀的成果.本论文研究方向是在城市街景影像中利用深度学习的方法进行行人车辆检测,属于计算机视觉的目标检测任务的分支方向.因此,本节分别从影像行人检测和车辆检测两个角度分析国内外研究现状.
1.2.1 行人检测研究现状
行人检测是目标检测的一个重要研究分支,也是目标检测实例中较为基础的应用.其中主要应用在行人形态分析,行人识别等领域.此外,其在视频监控,人流量统计,自动驾驶中都有重要的地位.目前针对行人检测的相关研究方法主要分为两类,一类是基于传统特征提取的方法进行行人检测,另一种是基于深度学习算法实现行人检测.
起初,传统的行人检测的最主流的方法是基于单一特征进行影像中行人特征的选择,国内针对行人的特征选择主要是利用基于方向梯度直方图特征(HOG)[3]进行行人特征的提取,叶林[4]提出了一种基于空间梯度直方图的行人检测算法,在不降低检测效果的前提下,保证了行人检测的效率.曲永宇[6]在梯度直方图的基础上,针对检测精度有待提高、向量维数较大的问题,提出了利用梯度统计特征的直方图加上颜色频率和肤色特征来描述行人检测的实现.高修祥[5]提出了一种改进的方向梯度直方图(directionalgradient histogram)算法,将 HOG 特征向量分成两部分,然后结合残差网络进行特征融合,提高了行人检测的准确性,降低了检测的失败率.陈锐[7]提出了一种基于多特征融合的行人检测算法.利用主成分分析(PCA)对 HOG 进行降维,并与局部二值特征(LBP)融合.在 INDIA 数据库上进行了实验,以提高训练和检测的速度.
由于行人检测的影像大部分属于自然场景,往往选取单一的特征提取思路会造成结果的不准确,精度无法满足要求.在后续的行人检测工作研究中,研究者们将影像预处理与行人本身特点进行结合,对算法模型进行了优化与设计,汪成亮[8]对于快速移动人体检测,首先采用高斯混合模型进行背景剔除,减少了检测扫描的时间.最后将主成分分析与梯度直方图相结合,提高了检测窗口的分类速度.王波[9]提出了一种有效的行人特征点模型,用于街景视频监控中的行人检测,并对行人的轮廓特征进行了研究.然后利用 Canny 算子边缘检测方法对行人样本图像边缘进行检测,并结合形态学对图像进行进一步处理.从而有效、准确地获取行人轮廓.在针对行人特点进行了一系列的探索后,后续的研究者还加入了级联的思想,王奕波[10]在街景图像中,提出了基于级联特征的行人检测方法.首先确定可能包含行人的潜在区域,利用基于概率接受度的方法,根据方向梯度的直方图特征进行强化扫描分类,最后通过非最大抑制(NMS)过程对分类结果进行汇总.实验结果表明,基于级联特征的方法一方面可以使两种特征互补,提高检测精度.另一方面,基于概率接受的强化扫描分类方法使检测时间显着缩短.
国外传统行人检测的研究主要集中在区分行人与其他目标的分类算法研究与分类器使用上,David McAllester 等人[11]提出了一种基于边缘特征的数据挖掘方法,考虑行人检测中边缘特征信息,利用多尺度的学习特征提高行人检测的速度和精度.Payam 等 人[12]提出了在行人检测过程中使用 shapelet 特征的算法,这种特征有利于区分行人与非行人信息的梯度构建,使用 AdaBoost 分类器,shapelet 特性可以把行人检测的重点放在更小的特征集上,最后在 INRIA 数据集上证实了算法的有效性.在模型结构与优化方面,创新性的提出了 DPM 思想.Rodrigo Benenson 等人[13]针对过去十几年在行人检测方面的算法进行了总结,概括了主流算法包括 HOG+SVM 特征提取检测、可变形部分检测器(DPM),将传统的行人检测算法应用在 Caltech-USA 数据集上,对比不同算法的效果评价特征.
传统的行人检测算法大多在低层特征表达基础上构建复杂的模型来提升检测精度,但是仍然存在单一特征带来的精度问题,使用特征融合的方式会提升一部分的精度,但是会带来特征提取成本的增加.之后卷积神经网络应运而生,优秀的网络结构层次,更加准确的特征信息描述,高维特征提取,以及针对不同场景下特征的多元化描述都使得神经网络发挥出更大的优势.基于深度学习的行人检测的思路成功地应用在场景检测中,从 2006 年以来,大量深度神经网络的论文被发表,2012 年,Hinton 课题组通过构建 CNN网络 AlexNet[14]一举夺得图像识别比赛冠军,从此神经网络开始受到广泛的关注.
在深度学习算法获取候选框区域的研究中,夏金铭[15]在 Fast R-CNN 基础上引入了困难样本挖掘的策略,提升检测的泛化能力.王斌[16]利用深度学习网络身视觉特征提取的优越性,在此基础上设计了多种策略融合的窗口选择方法,改变传统滑动窗口耗时长的问题.采用了选择性搜索算法,提高特征提取的性能.刘芷含[17]提出了通过挖掘遗漏的负样本来充实分类器的训练样本,提出一种新的网络结构以实现多层特征融合,利用独立模块进行候选区域的选择.
针对候选区域的选择依然会带来检索时间长的问题,后续深度学习目标检测发展的进程转向了由端到端的研究中,胡振寰[18]针对遮挡行人检测问题,提出了在 SSD 算法的前置网络中加入更加先进的 SE-Inception 结构,对 SSD 的先验框进行重新设计,修改了相应的 Loss,保证遮挡情况下行人检测的精度.祝庆发[20]针对密集场景下的行人检测,改进了 Yolo 算法的网络结构和损失函数,在人工标注的实际场景中进行测试和训练.胡超超[19]以 Yolo V2 网络作为目标检测的基础模型,在获取小目标的基础上加入了残差网络,构建训练的行人样本库,并且修改网络参数,训练出更符合行人检测的网络模型,通过匹配算法进一步对行人进行分类,利用卡尔曼滤波进行跟踪,大大提升检测速度.
针对行人特征的卷积网络过程中,国外更加侧重于结合多特征进行卷积网络的实现,Shao 等人[21]结合图像的多光谱特征,提出了四种卷积网络融合体系结构,结合了不同通道的特征,针对 KAIST 数据集上的精度提高了 11%.Garrick Brazil 等人[22]提出了一种融合了语义分割和行人检测功能的分割融合网络,针对场景中遮挡和形状变化问题都有了很大的提高.Ping 等人[23]提出一种新的深度模型,从多个任务和多个数据源中学习行人高层特征,将已有的场景分割数据集中的属性信息转移到行人数据集,减少数据集之间的差异,在 Caltech 数据集上测试,失误率降低了 17%.
1.2.2 车辆检测研究现状
车辆识别同样作为场景应用中常见的检测目标,在相关目标检测研究中具有重要的意义.保证车辆识别速度快,得到准确率高的车辆检测信息,决定了能否更好地服务于城市发展管理工作中.车辆信息检测作为当前图像处理领域正在研究和广泛关注的课题, 在衡量城市综合发展水平中具有良好的发展前景.
最初针对传统的车辆检测算法中主要是采用人工特征提取的检测方法.钱晋[24]研究了基于背景差法的昼间视频车辆检测算法的相关问题,提出了背景提取与更新算法,满足视频车辆动态检测的要求.郭磊[27]提出了一种应用单目视觉进行车辆检测的方法,以车辆阴影以及边缘作为检测的主要特征并且结合雷达探测数据,提高车辆检测的准确率.张涛[25]研究了车辆检测区域设置特定模型,在 Haar 特征的基础上,修改了遍历逻辑,提高了系统检测的实时性.金立生[26]提出了一种将图像特征与分类器融合的思想识别算法,实现了对前方车辆的准确识别.
在国外进行车辆检测的研究中研究者们多侧重于车辆进行实时检测的思路上,Amirali Jazayeri 等人[28]介绍了一种在多种环境条件下对视频目标车辆进行定位的综合方法.从视频中提取的几何特征被连续地投射到一维剖面上,根据场景特征和车辆运动模型,对视场中的运动进行概率建模,实现实时检测车辆的效果.Jun-Wei Hsieh 等人[29]研究了 SURF 算法特征,提出了一种新的车辆检测方案来检测移动摄像机中的车辆.该方案的优点是不需要背景建模,就能实现良好的检测结果.Margrit Betke 等人[30]提出了一种实时视觉系统,使用颜色、边缘和运动信息的组合来识别和跟踪道路边界、车道标记和道路上的其他车辆,利用多种特征融合的思路进行车辆的检测.Tehrani 等人[31]提出了一种基于 HOG 特征和 SVM 的车辆检测方法来实现城市道路中的车辆检测.
传统的学习方法只支持对少量数据的训练,因此对车辆多样性的检测仍然存在不足.近年来,随着 CNN 的发展,物体的分类和检测方法也相应飞速发展.利用神经网络训 练对于图像的精确度有了明显的提升.网络特征的使用摆脱了传统目标检测方法的限制,受外界环境变化小,不易受图像基本特征的影响,应用在复杂场景中也有较好的检测识别效果.
刘敦强[33]在 Faster R-CNN 基础上进行了改进,使用多尺度预测分支,增加样本挖掘机制,适当的选取正负样本,满足车辆检测的精度要求.黄皓宇[32]对 Mask R-CNN 算法模型进行改进,在进行预处理操作后,车辆检测的精度达到了 80%左右.宋焕生[34]在进行车辆检测过程中选取了不同的分类情况与构建不同视角下的数据测试集与验证集, 将检测的精度提升了近 10%.
王宇宁[36]提出一种基于 Yolo 算法的车辆实时检测方法,选择交通监控视频作为数据集进行车辆检测试验.达到了 89.3%的查准率.卞山峰[35]针对传统的车辆检测算法存在鲁棒性差、检测速度慢和准确率低等问题,提出基于改进 Yolo V2 模型的车辆实时检测算法.通过目标框维度聚类、网络结构改进以及输入图像多尺度变换等方法对 YoloV2 算法进行改进,明显提升了检测的精度和速度.Moran Ju 等人[37]提出了一种基于 YoloV3 的多尺度目标检测方法.基于 IOU 的数学推导方法,为改进的 Yolo V3 的每个尺度选择候选锚盒的数量和长宽比维数,同时将输出检测层前的 6 个卷积层转化为 2 个残差单元, 最后在 PASCAL VOC 数据集和 KITTI 数据集上进行了对比实验,改进后的网络能提高目标检测的平均精度.Chi Ma 等人[38]提出了一种基于 Yolo 深度学习算法的航空图像车辆检测方法.集成了一个适合 Yolo 训练的航空图像数据集.该训练模型特别是对小目标、旋转以及紧凑密集目标,满足实时性检测的要求.
1.3 研究内容及技术路线
1.3.1 研究内容
本文针对城市街景影像中的行人、车辆目标信息,利用深度学习的算法实现街景影像中行人车辆检测.在已有研究的基础上针对城市街景影像数据来源大,数据量丰富,影像尺度特征变化大的特点,提出了改进的 Yolo V3 算法,保证检索速度提高的情况下,同时对图像中行人,车辆数量多,存在遮挡及尺度变化明显等问题,进行了精度的提升.最后进行了不同算法的对比,得到改进的算法在检测目标上精度与准确度上的提高.具 体研究内容主要包含以下部分:
(1)解决街景中行人车辆检测中数量多、尺度变化大的问题
针对城市街景影像中行人车辆目标数量多,重复目标出现的特点,结合街景数据集本身的特征,由此带来的目标检测尺度变化大,存在遮挡的问题.主要思路为利用深度学习适用于处理图像视觉中目标检测识别的思想.
文章中采用目前深度学习主流的不同代表算法应用于街景影像中的行人与车辆目 标检测中,即采用 Two-stage 算法代表 Faster R-CNN 算法与 One-stage 算法代表 Yolo V3算法实现.在基于 One-stage 算法的快速检索的前提下,本文同时也选取一种轻量级主 干网络的 Yolo 算法最后结果的对比.最后采用改进算法与其他三类算法进行对比分析.
(2)改进 Yolo 算法实现行人车辆检测
本文在已有深度学习算法基础上,提出了一种改进的 Yolo V3 算法,在保证检索速度的同时,能够将街景场景中的尺度变化明显导致识别精度不高的行人车辆能够准确检测.文章最后通过精度速度评价指标对比以及不同算法影像输出结果,进行四种不同深度学习算法的比较,得出改进算法具有良好的实验结果,验证算法的有效性.
…………由于本文篇幅较长,部分内容省略,详细全文见文末附件

第 5 章 结论与展望
5.1 研究结论
随着智慧城市建设的发展,获取当前环境的位置信息有着重要的作用.同样作为城 市街景影像也存在大量的目标检测的研究内容,城市街景中目标检测已经成为城市治理能力综合提升的重要环节.本文针对目前城市街景影像中存在目标尺寸变化大、数量多的特点,影像数据中目标类别存在遮挡等问题,提出一种改进 Yolo 算法,引入高级语义嵌入与轻量级检测端的思路,分别从检测的精度与速度对算法的性能进行提升.通过街景影像数据集的输出结果进行性能分析对比,得到改进算法的正确有效性.
本文选取深度学习算法中两类主流算法中的代表算法作为本文结果对比,在 YoloV3 算法的基础上提出了一种改进算法,通过引入高级语义嵌入与轻量级检测端思想,从理论部分对算法的性能进行阐述与介绍,并对改进算法进行了实验分析.
其中文章主要实验部分为利用公开数据集与北京市西城区城市街景影像进行不同算法对比分析,对于公开 KITTI 数据集进行训练,共选取 7000 多张影像数据集进行网络训练过程,对比输出图像数据结果进行算法的训练.然后,在获取北京市西城区街景影像数据,利用标注工具对影像数据进行行人车辆类别的 VOC 格式转化.对比分析影像网络训练输出结果的精度指标与速度指标,通过影像的定性与定量分析,验证改进Yolo 算法在解决城市街景影像中存在的目标尺寸变化大、数量多的特点,影像数据中目 标类别存在遮挡问题,实验证明,改进算法在两个数据集上均有精度与速度的提升.
5.2 后续研究展望
利用深度学习进行影像目标检测应用领域广泛,如自动驾驶、视觉学习、定位技术等,本文所做的研究是利用改进深度学习算法的思路对影像中的特定物体类别进行识别检测.在论文中难免仍有许多不足之处.在今后研究中,还可以进行以下方面改进:
(1)更优秀的深度学习网络结构
目前深度学习发展迅速,应用于不同场景领域的算法越来越具有针对性,一种优秀的主干网络设计能对场景中的目标物体有更加精确的识别与认知,在网络训练过程中可以使用更加良好的激活函数,损失函数等.本文只采用了代表性的算法进行目标检测识别.
(2)更丰富的数据集
本文在训练测试的数据集数量中只涉及到了 10000 多张影像,在基于后续更加优秀的网络结构,可以通过扩大数据集的数量,让样本的训练更加充分.学习更多图像相关的特征.对于检测结果的提升,有更加重要的意义.
(3)数据集标注
由于本文在数据集的标注方面采用传统的标注工具进行标注,耗时较长,当影像中目标较多时,标注信息容易出现误差,会影响图像标注的质量,可能会对后续工作产生一定的影响.
参考文献
[1] Girshick R. and Donahue, et al. Rich feature hierarchies for accurate object detection andsemantic segmentation[J]. The IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2014, pp. 580-587
[2] Tao J. and Wang, et al. An object detection system based on YOLO in trafficscene[J].International Conference on Computer Science and Network Technology(ICCSNT),2017.
[3] N Dalal and B Triggs. Histograms of oriented gradients for human detection[J]. In CVPR,2005.
[4] 叶林, 陈岳林,林景亮.基于 HOG 的行人快速检测[J].计算机工程,2010(22):206-210.
[5] 曲永宇,刘 清,郭建明,等.基于 HOG 和颜色特征的行人检测[J].武汉理工大学学 报,2011.
[6] 高修祥,瞿成明. 基于 HOG 与残差网络的行人检测算法[J].黑龙江工业学院学报(综合版) 2019 (04): 72-77.
[7] 陈锐,王 敏,陈 肖. 基于 PCA 降维的 HOG 与 LBP 融合的行人检测[J].信息技术(02),2015101-105.
[8] 汪成亮,周 佳,黄 晟. 基于高斯混合模型与 PCA-HOG 的快速运动人体检测[J].计算机应用研究,2012(06): 2156-2160.
[9] 王波.街景监控视频中车辆和行人检测技术研究[D].浙江工业大学,2012.
[10] 王奕波,高 辉,张茂军. 街景图像中基于级联特征的行人检测方法[J].计算机应用31 (S2),2011:129-132.
[11] Felzenszwalb, P. and D. McAllester, et al. A discriminatively trained, multiscale,deformable part model[J]. IEEE Conference on Computer Vision and PatternRecognition,2008.
[12] Sabzmeydani P. and G Mori.Detecting Pedestrians by Learning Shapelet Features[J]. IEEEConference on Computer Vision and Pattern Recognition,2007
[13] Rodrigo Benenson and Jan Hosang ,et al.Ten Years of Pedestrian Detection, What HaveWe Learned[M]// Omran M: Computer Vision - ECCV 2014 Workshops,2014:613-627 .
[14] A. Krizhevsky, I. Sutskever, and G. E. Hinton, Imagenet classification with deepconvolutional neural networks[J]. in Advances in neural information processing systems,2012, pp. 1097-1105.
[15] 夏金铭,柳昌志,段高辉,等.一种基于 Faster R-CNN 的行人检测算法[J]. 电脑知识与技术,2019 (24): 218-221.
[16] 王斌.基于深度学习的行人检测[D].北京交通大学,2015.
[17] 刘芷含.基于深度学习的行人目标检测方法[D].南京理工大学,2018.
[18] 胡振寰. 基于深度学习算法的遮挡行人检测[D].广西科技大学,2019.
[19] 胡超超,刘军,张凯,等.基于深度学习的行人和骑行者目标检测及跟踪算法研究[J].汽车技术,2019(07): 19-23.
[20] 祝庆发.基于改进 YOLO 算法的密集人群场景下的行人检测[J]. 电脑知识与技术,2019 (22).
[21] J Liu, S Zhang, S Wang, Multispectral Deep Neural Networks for PedestrianDetection[D].2016.
[22] Garrick Brazil and Xi Yin., Illuminating Pedestrians via Simultaneous Detection &Segmentation[J]. The IEEE International Conference on Computer Vision (ICCV), 2017,pp. 4950-4959.
[23] Tian, Y. and P. Luo, et al. Pedestrian Detection aided by Deep Learning Semantic Tasks[J].The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp.5079-5087.
[24] 钱晋. 基于背景差法的视频车辆检测算法研究[D].上海交通大学,2007.
[25] 张涛,陈万培,乔延婷,等. 一种 Haar 特征车辆检测速度的提升方法[J].无线电工程,2019 (05): 393-396.
[26] 金立生,王 岩,刘景华,等. 基于 Adaboost 算法的日间前方车辆检测[J]. 吉林大学学报(工学版) 2014(06): 1604-1608.
[27] 郭磊,李克强,王建强,等.一种基于特征的车辆检测方法[J].汽车工程,2006.
[28] Jazayeri A. and H Cai, et al. Vehicle Detection and Tracking in Car Video Based on MotionModel[J].IEEE Transactions on Intelligent Transportation Systems 2011 (2): 583-595.
[29] Hsieh, J. and L. Chen, et al. Symmetrical SURF and Its Applications to Vehicle Detectionand Vehicle Make and Model Recognition[J]. IEEE Transactions on IntelligentTransportation Systems 15 (1),2014,pp: 6-20.
[30] Betke, M. and E. Haritaoglu, et al. Real-time multiple vehicle detection and tracking froma moving vehicle[J].Machine Vision and Applications 12 (2),2000,pp: 69-83.
[31] Tehrani, H.and Mcallester, D.A.et al. On-Road Multivehicle Tracking Using DeformableObject Model and Particle Filter with Improved Likelihood Estimation[J]. IEEETransactions on Intelligent Transportation, 2, 2012,pp:748-758.
[32] 黄皓宇. 基于 Mask R-CNN 的街景车辆目标的检测方法研究与应用[D]. 华中师范大学,2019.
[33]刘敦强. 基于 Faster RCNN 的道路车辆检测算法研究[D].南京航空航天大学,2018.
[34] 宋焕生,张向清,郑宝峰,等. 基于深度学习方法的复杂场景下车辆目标检测[J]. 计算机应用研究,2018 (04): 1270-1273.Detection[J]. Applied Sciences 9(18),2019,pp: 3775.
[35] 卞山峰,张庆辉 基于改进 YOLO v2 的车辆实时检测算法[J]. 电子质量,2019(10): 19-22.
[36] 王宇宁, 庞智恒,袁德明.基于 YOLO 算法的车辆实时检测[J].武汉理工大学学 报,2016.
[37] Ju and Luo, et al. The Application of Improved YOLO V3 in Multi-Scale Target
[38] Lu, J. and C. Ma, et al. A Vehicle Detection Method for Aerial Image Based on YOLO[J].Journal of Computer and Communications 06(11),2018,pp: 98-107.
[39] Lowe D G. Distinctive Image Features from Scale-Invariant Keypoints[J]. InternationalJournal of Computer Vision, 2004, 60(2):91-110.
[40] 杜金辉. 基于快速 SIFT 匹配的行人信息检测[J].电子器件,2012 (05): 601-606.
[41] 付若楠.基于深度学习的目标检测研究[D].北京交通大学,2017.
[42] S. Ren, K. He, R. Girshick, and J. Sun, Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks[J]. NIPS, 2015.
[43] 范丽, 苏兵,王洪元. 基于 YOLOv3 模型的实时行人检测改进算法[J]. 山西大学学报(自然科学版) ,2019 (04): 709-717.
[44] Redmon, Joseph, et al. You Only Look Once: Unified, Real-Time Object Detection[J]. TheIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779-788.
[45] Redmon Joseph, and A Farhadi. YOLO9000: Better, Faster, Stronger[J]. The IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7263-7271.
[46] Zhenli Zhang, Xiangyu Zhang,et al. ExFuse: Enhancing Feature Fusion for SemanticSegmentation[J]. The European Conference on Computer Vision (ECCV), 2018, pp. 269-284..
[47] P. Doll ar, C. Wojek, B. Schiele, and P. Perona. Pedestrian detection: An evaluation of thestate of the art. TPAMI[J]. IEEE Transactions on Pattern Analysis and MachineIntelligence,2012.
[48] Xiaotian Sun.A deep learning framework for road marking extraction, classification andcompletion from mobile laser scanning point clouds[J]. International Society forPhotogrammetry and Remote Sensing.,2018.
[49] Dai, J. and Y. Li, et al. R-FCN: Object Detection via Region-based Fully ConvolutionalNetworks[J]. Advances in Neural Information Processing Systems 29.2016.
[50] Tao, J. and H. Wang, et al. An object detection system based on YOLO in traffic scene[J].6th International Conference on Computer Science and Network Technology,2017.
[51] Yang, D. and Y. Zou, et al. C-RPNs: Promoting object detection in real world via a cascadestructure of Region Proposal Networks[J]. Neurocomputing ,2019,pp: 20-30.
[52] 何玲.基于 TensorFlow 框架的目标检测与细分系统研发[D]. 东南大学,2018.
[53] Geiger A, Lenz P, Urtasun R. Are we ready for autonomous driving?the kitti visionbenchmark suite[C]. 2012 IEEE Conference on Computer Vision and Pattern Recognition,Rhode Island, 2012, pp:3354-3361.
[54] Collions R T,Lipton A J,Kanade T.Introduetion to the Speeial Seetion onVideoSurveillanee[C]. In:IEEE Computer Soeiety,eds.Proceedings of the IEEE Transaetionson Pattern Analysis and Maehine Intelligenee,2000.22(8):745-746.
[55] 陈 超.基于卷积神经网络的目标检测算法及应用研究[D].山东师范大学. 2018.
[56] 范 丽. 基于 YOLOv3 模型的实时行人检测改进算法[J]. 山西大学学报(自然科学版),2019(04): 709-717.
[57] 郭明玮, 赵宇宙, 项俊平,等. 基于支持向量机的目标检测算法综述[J]. 控制与决策,2014(02): 193-200.
[58] 何 霞, 汤一平, 王丽冉,等.基于 Faster RCNN 的多任务分层图像检索技术[J]. 计算机科学,2019(03): 303-313.
[59] 刘志成,祝永新,汪 辉,等. 基于卷积神经网络的多目标实时检测[J].计算机工程与设计 2019(04): 1085-1090.
[60] 唐 诗.基于车载视频的道路车辆及行人检测[D].电子科技大学,2018.
[61] 谢娟英 刘然.基于深度学习的目标检测算法研究进展[J].陕西师范大学学报(自然科学版),2019(05): 1-9.
[62] 徐 亮,黄李波,白洁.基于 Faster RCNN 和 YOLO 的交通场景下的车辆检测[J].佳木斯大学学报(自然科学版) ,2019.
[63]杨娜娜.基于特征的大规模图像检索算法研究[D]. 安电子科技大学,2018.
[64] 张富凯,杨 峰,李 策.基于改进 YOLOv3 的快速车辆检测方法[J].计算机工程与应用 2019(02): 12-20.
[65] 赵 琼,李宝清,李唐薇.基于改进 YOLOv3 的目标检测算法[J].激光与光电子学进展,2019:1-16.
[66]周 腾.交通场景下的行人和车辆实时检测算法[J].现代计算机,2019(21): 50-55.
[67] Hays, J. and A. A. Efros. IM2GPS: estimating geographic information from a singleimage[J]. IEEE,2008.
[68] Philbin, J. and O. Chum, et al. Object retrieval with large vocabularies and fast spatialmatching[J]. IEEE,2007.
[69] Rublee, E. and V. Rabaud, et al. ORB: An efficient alternative to SIFT or SURF[J].IEEE,2011.
[70] Sattler, T. and M. Havlena, et al. Large-Scale Location Recognition and the GeometricBurstiness Problem[J]. The IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2016:1582-1590 .
[71] Schindler, G. and M. Brown, et al. City-Scale Location Recognition[J]. 2007 IEEEConference on Computer Vision and Pattern Recognition,2017.
[72] Stewénius, H. and S. H. Gunderson, et al. Size Matters: Exhaustive Geometric Verificationfor Image Retrieval Accepted for ECCV 2012. Berlin, Heidelberg, Springer BerlinHeidelberg,2012: 674-687.
[73] Yan, W. Y. and A. Shaker, et al. Potential Accuracy of Traffic Signs' Positions ExtractedFrom Google Street View[J]. IEEE Transactions on Intelligent Transportation Systems14(2): 1011-1016.
[74] Du, M.; Wang, J.; Jing, C.; Jiang, J.; Chen, Q. Hierarchical data model for storage andindexing of massive street view. In Proceedings of the International Archives of thePhotogrammetry, Remote Sensing and Spatial Information Sciences - ISPRS Archives;Enschede, Netherlands, 2019; Vol. 42, pp. 1295-1299.
[75] Zamir, A. R. and M. Shah, et al. Large-Scale Visual Geo-Localization[M]. CH,Springer,2016.
[76] Zhang, W. and J. Kosecka. Image Based Localization in Urban Environments[J]. ThirdInternational Symposium on 3D Data Processing, Visualization, and Transmission ,2006.