心理学论文


人们在阅读词汇时,会将词汇的视觉信息转化为词汇的语音信息. 关于视觉信息是如何通达语音信息的,主要存在几种不同的理论.1 双通路理论。
1. 1 传统的双通路模型(dual route model)
传统的双通路理论假设语音通达存在两条通路———词典通路(lexical route) 和非词典通路(nonlexicalroute)[1 -2],词典通路即视觉刺激在激活词形表征后通过心理词典通达其对应的语音表征,因为假词是不发音的,所以只有真词可以以词条的形式存储在心理词典中,词典通路只能正确提取真词的语音; 非词典通路也称亚词典通路,是指视觉刺激在激活词形表征后通过亚词汇水平的形音对照规则(grapheme phoneme cor-respondence rules,GPCs) 直接通达语音而无需心理词典的激活,在拼音文字中规则性词指的是符合形音对照规则(GPCs) 的词,所以非词典通路能够正确提取规则词和非词的语音信息. 由于非词典通路是根据形音对照规则获取单词语音的,所以单词的字频、单词字形相似性和家族的大小都不会对单词识别产生影响[1],而这和已有的研究结果是矛盾的. 关于失语病人的研究支持了传统的双通路理论,但是传统的双通路模型无法解释一致性效应[3 -6],因为传统的双通路模型认为字形到语音的映射是一个词汇查找过程,这个过程假设整字发音存储在词汇系统中,单词的检索不受相似字的影响,而这是不适应于一致性效应的. 另外,传统的双通路模型也是无法解释类比观点的,GLUSHKO 提出的类比观点认为非词既可通过亚词汇形音对照规则(GPCs) (非词典通路) 通达语音,也可通过与之字形相似的真词在心理词典激活其语音表征,也就是说非词的语音通达既可通过非词典通路也可通过词典通路[7]. 最重要的是,已有研究表明汉语词汇产生中音、形、义 3 种信息不是依次独立激活的,存在交互激活即汉语词汇产生中既可由字形激活语音,也可由字形激活语义后再激活语音[8].
1. 2 双通路瀑布式模型
COLTHEART 修正了传统的双通路模型,提出了新的双通路模型即双通路瀑布式模型(a dual-route cas-cade model,DRC) ,双通路瀑布式模型认为语音通达存在 3 条通路: ①视觉词形直接通达语音,即视觉刺激直接激活心理词典中词形表征的语音信息; ②视觉词形刺激先激活语义然后由语义通达语音,即视觉刺激先激活心理词典中词形表征的语义信息,然后由词形的语义信息激活词形的语音信息; ③亚词汇通路,视觉词形通过亚词汇水平的形音对照规则(GPCs) 通达语音. 通路一和通路二实质上属于一条通路,不过通路一是语音通达的直接通路,通路二是语音通达的间接通路即语义中介通路[9 -10]. 双通路瀑布式模型修正和完善了双通路模型,可以解释一些传统的双通路理论无法解释的现象,如一致性效应. 视觉刺激激活心理词典中的词形表征以及与视觉刺激字形相似字的词条,然后词形表征激活语音输出,刺激字和字形相似字相互竞争,并激活音素系统. 相对于一致性字,不一致字会产生更大的竞争,所以不一致字命名时间更长. 但是,众所周知,汉字是具有深层正字法的表意文字,不同于浅层正字法的拼音文字,其形音对照是不规则的、任意的,或者说是不透明的,所以适用于拼音文字的双通路模型不完全适用于汉字命名过程. 如果采用双通路的观点解释汉字识别过程,则亚词汇通路是无法解释汉字命名过程的. 另外,双通路瀑布式模型假设,亚词汇通路能够正确提取非词和规则词的语音信息,而词典通路能提取不规则词的语音信息,所以可以推测汉字的假字是不发音的,而这和已有的研究是矛盾的,FANG S P 等和 LEE C Y 均发现包含声旁部件的假字是可以发音的[11 -12].
2 连接主义模型
2. 1 连接主义模型
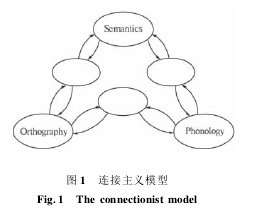
连接主义模型认为单词识别涉及 3 种水平的计算编码: 正字法水平、语音水平及因素的声旁特征(如摩擦音、唇音,字母的位置也必须表征,如 lap 不同于 pal ) 、语义水平. 正字法和语音层之间有一系列存储单元,存储单元的存在可使网络表征更复杂地映射[13]. 连接主义模型假设这 3 种水平的信息是分布表征的,即一系列单元分别表征单词的正字法、语音和语义信息. 每个表征单元都有一个激活值(0 -1) ,不同的词条表征编码为不同的激活模式,简单地说,即最初时单词的正字法单元、语音单元、语义单元间的连接比重都是相等的,学习法则的应用会使单元间的连接比重发生变化,如视觉呈现刺激“棉”,棉的字形信息不仅激活了棉自己的形态表征,还会激活与棉字形相似的其他字的形态表征,如“锦”,已有的经验告诉我们目标字读“mian”而不是读“jin”,这就会使表征“棉”的正字法单元和语音单元间的连接比重大于“锦”的正字法单元和其语音单元的连接比重,单元间的连接比重就会发生变化. 另外,单元间连接比重的改变又会影响下一级水平的激活,如“棉”字语音激活水平大于“锦”字,这就会使“棉”的语音和语义之间的连接比重大于“锦”,即“棉”的语义激活水平大于“锦”.连接主义模型假设该模型的加工是交互作用的,也就是说 3 种水平的表征系统相互影响,至少语音、语义水平的表征会对语义水平的加工产生影响,而这又会直接或间接地影响其他水平(语音、语义) 的加工,也就是说单词识别时正字法水平的信息会影响语音语义的加工. 由于单元间反馈网络(从存储单元到正字法单元) 的存在,单词的语音语义信息也会影响正字法水平的加工,这也同时说明连接主义模型由前馈网络(输入单元→存储单元→输出单元) 和反馈网络(从存储单元到正字法单元) 组成.如图 1 所示,存储单元和表征单元都用椭圆表示,不同水平间单元的连接用箭头表示,因为连接主义模型假设不同水平间是交互作用的,所以箭头是双向的.连接主义模型可以很好地解释一致性效应,但不能解释规则性效应. 根据连接主义模型,单词的频率高,其字形、语音和语义之间的连接就强,所以单词识别快. 根据一致性效应,一致性字即包含某个声旁且发音都相同的字,不一致性字即是指包含某个声旁但发音不相同的字,所以一致性字的发音不仅可由刺激字本身的形态表征激活,也可以由与刺激字形态相似的其他字的字形表征激活,这样命名速度就会很快,而不一致性字、刺激字的字形表征则会和其字形相似字的形态表征相互竞争,干扰刺激字正确的语音表征,所以命名时间会长于一致性字. 规则性效应指的是命名声旁和整字读音相同的低频形声字快于命名声旁和整字读音不同的形声字,说明规则性效应只在低频字中出现,而连接主义模型则认为单词频率高,则命名快,而且连接主义模型中既不存在心理词典也不存在亚词汇水平的形音对照规则,所以无法判断声旁发音是否和整字相同,也无法解释规则性效应.
2. 2 双通路模型和连接主义模型的区别
阅读加工中涉及的加工阶段的本质不同; 阅读时必须要激活的信息类型不同; 阶段内和阶段间的动态加工不同; 加工通路不同,双通路模型本质上有两条通路: 词典通路和非词典通路,而连接主义模型本质上只有一条词汇加工通路: 正字法单元→存储单元→语音单元。
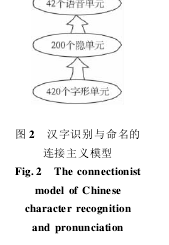
3 汉字识别与命名的连接主义模型
汉字识别与命名的连接主义模型是由陈鹰、彭聃龄在 SEIDENBERG 和MCCLELLAND 的并行分布发展模型的基础上提出的[14 -15]. 如图 2,该模型的理论框架和并行分布发展模型相似,由 3 层单元组成: 字形单元,隐单元和语音单元. 在该模型中只有前馈网络组成(字形→隐单元→语音) 无反馈网络(语音→存储→字形) ,也就是说 3 层单元之间不会相互影响,激活只能由字形传递至语音,而语音水平的表征不能影响字形水平的激活,字形单元的激活只能由外界输入决定. 彭聃龄等用该模型成功模拟了汉字识别与命名时的一系列现象,如频率效应与规则性效应、低频形声字命名的促进效应和命名技能的习得等.
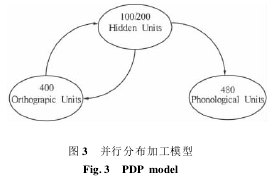
4 并行分布加工模型
4. 1 并行分布加工模型
并行分布加工模型(parallel-distributed processing,PDP) 由 SEIDENBERG和 MCCLELLAND[13]在连接主义模型的理论框架下提出的,删除了连接主义模型中语义水平的表征,是连接主义模型的简化,因此也是连接主义模型的一个子模型. 如图 3 所示,PDP 模型只有正字法水平、语音水平及二者之间的存储单元,反传算法(back - propagation) 学习法则调节单元间连接的比重. 模型中不存在从语音到存储单元的反馈,表明语音水平的表征不能影响正字法水平的表征,而存储单元到正字法单元的反馈是为了保持、增强或者是清除输入到正字法水平的信息. PDP 模型有 3 种类型的假设: 加工假设(说明单元间交互激活的路径) 、学习假设(说明学习是如何调节单元间连接比重的) 和表征假设(说明单词的正字法和语音是如何表征的) . 该模型认为词汇阅读时不涉及心理词典的表征,也不包括亚词汇水平的形音对照规则,所以单词命名不涉及发音规则,词汇判断也无词汇水平的表征. 模型中存在的是一系列节点—单元,结点分布表征词汇的正字法信息和语音信息,这表明单词的正字法、语音信息由一系列单元表征,而每个单元又可表征一些单词的正字法语音信息. 单词的语音加工是从字母串的呈现开始的,字形输入信息激活模型中相应的形态表征节点. 由于节点是分布表征的,所以被激活的相关形态表征节点不仅表征了当前的输入刺激,同时,也表征了与当前输入刺激形态相似的其他词汇的知识,这些词汇的语音表征节点进而被激活. 在 PDP 模型中,语音信息的计算决定于节点之间的联结强度,而节点之间的联结强度决定于项目出现的次数,即学习与使用频率.
4. 2 并行分布加工模型的优点
PDP 模型可以模拟人类行为的许多方面: ①单词间加工难度的差异; ②新颖词的发音; ③阅读者词汇加工技巧的差别; ④阅读新手到阅读熟练者的转变; ⑤词汇判断和命名任务的区别. PDP 模型中,模型早期的学习阶段,词汇加工技巧和儿童无异,少部分存储单元的训练,其输出特点和阅读障碍者一样; 模型表现主要由3 个因素决定: 输入性质、书写英语的有效部分和学习规则.5 交互激活竞争模型交互激活竞争(interactive activation and competition,IAC) 模型由 MCCLELLAND,RUMELHART 等提出[16]. IAC 模型是 PDP 模型的先驱,二者的主要区别是: IAC 模型说明功能表征水平,主要依赖单元间兴奋和抑制的交互作用; PDP 模型是一个网络,网络由不同层级组成(输入单元、存储单元、输出单元) ,并主要依赖学习法则调节单元间连接的比重.大量研究表明汉字加工过程涉及其组成成分的加工,如部件的加工采用交互激活竞争模型论述汉字的词汇加工过程,词汇加工系统包括正字法系统、语音系统和语义系统. 当视觉刺激呈现时先激活字词的最低水平的特征———正字法系统(如笔画数、笔画组合及笔画间的关系等) ,然后激活由词形表征传递至语音系统、语义系统,最后激活字或多字水平的表征. 因此,字水平的加工受到字的成分属性的影响(如笔画、部件、部件位置等) . 规则性和一致性效应既可以在部件水平上得以解释: 当命名整字时,如果整字发音和其包含声旁发音相同,那么命名时间短,如果整字发音和声旁发音不同,则命名时间长(规则性效应) ,也可在整字水平上得到解释: 命名整字时,不仅刺激字的语音信息被激活,与刺激字包含相同声旁的字也被激活,如果该声旁在所有字中的发音都相同,那么刺激字的命名时间短,反之则会产生竞争,命名时间长(一致性效应)[17].
参考文献:
[1] 毕鸿燕,翁旭初. 出声阅读中语音通达的双通路模型[J]. 生物物理学报,2006,22(5) : 325 -330.
[2] 蔡厚德,齐星亮,陈庆荣,等. 声旁位置对形声字命名规则性效应的影响[J]. 心理学报,2012,44(7) : 868 -880.

1978年Shepard曾提出过一个视觉表象外在化的研究设想。亦即研制一套装置,这种装置既能检测出被试观看某种客体时的知觉象,同时也能检测出客观事物消失后出现在头脑中的记忆表象和想象表象。检测出来的视觉表象可以转换为电信号呈现在荧光屏上供研究者进...
自古以来,人们都无法摆脱以貌取人的影响,这究竟是一种偏见,还是有其真正的道理激发了很多学者的兴趣,从而展开了许多关于面部呈现的人格信息的探究。中国古代的面相术很可能是最早有关于面部特征与人格信息之间关系的研究。中国古代面相术包含了五官、颧...

认知心理学论文精选范文10篇之第九篇:儿童认知心理下的儿童网站的视觉设计策略 摘要: 信息时代网络已经渗透到儿童生活的方方面面。目前, 国内公共平台和媒体的网页在视觉设计上很少为儿童考虑或仅仅停留在添加装饰元素的层面, 只运用视觉传达专业或平面...
1引言自我相关信息由于其具有社会学以及进化理论上的重要意义,自我加工机制问题一直是心理学研究的焦点之一.自从鸡尾酒会效应(Moray,1959)提出以来,大量相关研究证实,个体普遍反映出自我加工优势,即与他人相比,自我相关信息(例如,自我名字,自我...
1引言人类的大脑并非被动接受外部信息的刺激,而是通过以往的经验去主动预测即将发生的事件(Kveraga,Ghuman,&Bar,2007)。视觉预期(visu-alanticipation)是一种运用视觉信息的部分资源和先行资源对即将发生的事件进行预测的能力(王东石,杨昭宁,朱婷...