数字图像处理论文

随着科学技术的进步,越来越多的高新技术被应用在了人们的生产生活当中,这在推动现代社会发展的同时,也让人们的生产,生活方式发生了很大的改变,特别是人脸识别技术以及视频处理技术的发展和应用,将会对现代社会的发展产生更为深远的影响。下面是搜索整理的图像识别论文6篇,供大家参考阅读。
图像识别论文第一篇:基于ResNet算法的垃圾图像识别分类研究
摘要:伴随着社会发展和生活质量稳步提高,垃圾如何处理问题显得尤为重要。该研究采用深度神经网络算法对实际生活场景中的40种垃圾图片进行识别分类,通过优化ResNet算法提升识别精度,识别率为99.4%。为合理解决垃圾分类的难题,有效提升资源利用率,减少环境污染提供一定的理论依据。
关键词:垃圾分类; ResNet算法;图像识别;
Abstract:with the development of society, the quality of people's life has been steadily improved, and the problem of garbage disposal has become increasingly apparent. In this study, the deep neural network algorithm is used to recognize and classify 40 kinds of garbage images in real life scenes. The recognition accuracy is improved by optimizing RESNET algorithm, and the recognition rate is 99.4%. In order to solve the problem of waste classification, improve the utilization rate of resources and reduce environmental pollution, a certain theoretical basis is provided.
0 引言
根据有关部门的统计分析,我国每年产生生活垃圾逾4亿吨,成为世界垃圾大国之一。就当前形势而言,不管是焚烧、填埋或者生物处理都存在着很多困难。2019年6月,习总书记就垃圾分类工作做出明确指示,着重强调实施垃圾分类是社会文明水平的一个主要体现。国内各个地方生活垃圾分类标准虽然不同,但一般可以分成以下四类,分别是可回收垃圾、有害垃圾、厨余垃圾和其他垃圾,而且每个类别下又包含若干子类别,种类繁多且十分复杂[1]。因此,如何实现垃圾自动识别分类已然变成急于解决的首要问题。
早期,国内外学者们只是将经典的图像分类算法应用于垃圾图像分类中,但是这种方法需要手动获取图像的部分特征,例如:形状、颜色、纹理等,再利用分类器识别。随着卷积神经网络的迅速发展,深度学习的相关算法被应用于机器视觉、模式识别等领域。在国内,郑海龙等人使用SVM方法对建筑垃圾识别分类做了大量研究;向伟等利用分类网络CaffeNet,通过改变卷积核的大小和网络层数,令它应用在采集的1500张水面垃圾数据集上识别,最后正识率为95.75%。2019年,华为通过举办垃圾图像分类竞赛组建了容量为一万多张的数据集,进而加快此领域的发展速度。国外方面,2012年,Alex Net[2]获得了Image Net图像分类竞赛的第一名,这也表示深度学习在图像领域的迅猛发展。随后,Google Net、VGGNet、Res Net[3]等算法提高了图像识别分类的准确度,同时在人脸识别、车辆检测等多个领域取得了很好的应用效果,而垃圾识别分类在深度学习算法的帮助下也获得了很大的突破。美国斯坦福大学的Yang等人构建了Trash Net Dataset公开数据集,其中包括6个类别共2527张图片。Ozkaya[4]等利用将不同CNN网络的分类效果进行比较,然后构建神经网络模型并对相关参数优化,最后在数据集Trash Net Dataset上进行实验,识别率为97.86%,是目前这一数据集上最佳分类网络。在非公开数据集方面,Mittal[5]等采集了2561张的垃圾图片数据集GINI,利用Garb Net模型获得了87.69%的正识率。
就我国发展情况而言还处于初期阶段,目前使用的图像分类算法还没有很好的应用于垃圾处理相关领域,一些应用的算法还存在很多问题,如识别精度不高、泛化性能较差、处理速率低下等。面对以上问题,应该在网络结构中融合注意力机制模块和特征融合模块用于提高垃圾图像分类的精准性与鲁棒性。本文提出一种基于Res Net50网络结构的深度卷积神经网络算法来对40种垃圾图片进行分类,从而提高垃圾分类的效率。
1 数据预处理
1.1 数据来源
本研究所采用的训练和测试图片都来源于实际生活垃圾,共有40个类别,图片中垃圾的类别格式为“一级类别/二级类别”,其中二级类别为具体的垃圾物体类别,即训练数据集里标注的类别,例如一次性快餐盒、果皮果肉、旧衣服等。一级类别有四种类别:可回收物、厨余垃圾、有害垃圾和其他垃圾。垃圾数据集中包括训练集(有标注)和测试集(无标注),训练集的所有图片被存储在train文件夹下面的0-39个文件夹内,文件的名称就是类别标签,测试集内共有400张待分类的垃圾图片在test文件夹里。
1.2 预处理
在数据处理上,采用了数据增强的策略,以一定的概率(0.5)对图片进行数据增强处理,具体的增强策略包括:颜色增强、随机角度、裁剪、水平翻转等,还采取了中值滤波方法进行降噪。
中值滤波法[6]作为一种非线性平滑技术,它的作用是采用排序统计理论降低图片中的噪声。它把每一个像素点相邻区域的全部像素点灰度值的中值作为这个点的灰度值,即把中心像素的值用全部像素值的中间值(不是平均值)替代。中值滤波采用选取中间值的方式来减轻图像孤立噪声点的干扰,对图像中的噪声有很好的的降低效果,与此同时,中值滤波不仅降低了噪声还能够使图像中的目标便捷更加清晰。以上优势是线性滤波方法所不能实现的,而且中值滤波方法实现过程相对简单,对硬件环境的要求也不高。
2 算法描述
2.1 Res Net算法
深度残差网络[7](deep residual networks,Res-Net)是一种基于卷积的、通过加深网络层次来提高精度的网络模型结构,通过采用几个小的卷积核替换一个大的卷积核的方法来减少Res Net模型参数,同时增加Res Net网络模型非线性激活函数的数量,这使得Res Net模型的计算量减少,进而提高计算效率。如果卷积层中输入与输出特征图的大小一致,那么滤波器数量是保持不变的;如果特征图大小变为原来一半时,滤波器的数量会加倍,特征图的池化层步长设置成2。深度不同的Res Net模型的主要区别表现在卷积层的层次数量,一些图像识别分类项目能够获得很高的识别精度都因为其网络模型具有较深的网络结构。网络结构通过增多卷积层数量来提取到的更加丰富的特征,这样识别效果也会更好。但是如果只是简单的堆叠网络会造成梯度消失,为了解决这个问题,深度残差网络采用标准初始化(nor-malized initialization)和正则化(intermediate nor-malization)来保留所有的特征变量,使网络模型不会损失精度。当网络结构层次更深时,会出现过拟合现象导致识别效果变得不好。就以上问题,Res Net网络结构采取与残差学习方法相结合并优化深度网络来提高识别精度和学习速度。从公式来看,初始的最优映射为H(x),通过令非线性层与其他映射F(x)=H(x)-x整合后最优映射变成H(x)=F(x)+x。如果原映射的效果不及残差映射好,那处于特殊情况下残差有可能设置为0,这样比较容易将映射逼近另一个映射。如下图。F(x)+x还可以通过其他方法表示,比如在前馈网络中增加一个能够实现恒等映射的物体。这样的话网络参数的数量会不发生变化,计算也不会繁琐,网络模型仍然能够采用SGD与反向传播来进行端到端的训练。
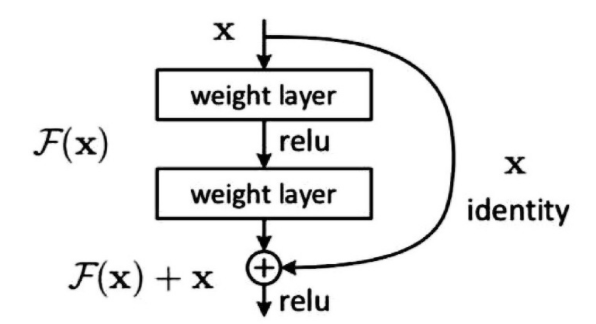
图1 残差网络示意图
Res Net算法把残差网络映射的每一组网络看作是一个构造块(residual block),定义为y=F(x,{Wi})+x(1),公式中x表示输入向量,y表示输出向量;F(x,{Wi})作为待训练的残差映射对公式中x与F的维度存在一定的要求,需要二者相同,否则需要增加线性投影来修改配维度,表示如下:
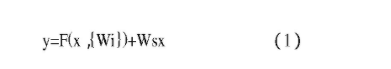
传统的卷积神经网络和Res Net算法存在着一些区别,ResNet算法为了能让网络层更好的进行学习残差,它将网络输入与其它层直接连接有。传统卷积神经网络卷积在进行训练时会出现数据损失等情况,造成识别精度下降;针对这种情况,ResNet算法为了保证数据完整性,在卷积层把输入信息绕道传给输出,减少了一些繁琐的工作,提高算法的准确度。Res Net算法具有如下网络设计原则:特征图大小一致的层具有相同的卷积核;当进入池化层后,特征图大小变为原来的一半。在残差网络中,用虚线和实线的连接方式来区别网络维度是否匹配。如果网络出现维度不匹配的情况,有两种可选的方案:第一种为直接采用零填充来增添维度,第二种为乘以W矩阵投影到新的空间。Res Net算法提高了基础网络结构的性能,特别是在机器视觉领域的应用,深度卷积神经网络表现出极大的优势。
2.2 softmax分类器
本文研究的是多个类别的分类实验,所以采用了softmax分类器[8]。该分类器与全连接层完全连接,输出输入目标所对应的每个种类的概率值。假设有N个输入目标,每个目标的标记,k为模型输出类别的种类数(k≥2)。本文做的是垃圾图像的分类工作,共分为40个类别,k的取值为40。对于给定的输入xi,用假设函数估计出其对应类别j的概率值。是softmax分类器的参数,为保证概率和为1,使用进行归一化。Softmax分类器的损失函数为:
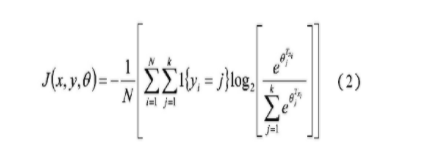
公式中1(yi=j)表示指示性函数,函数的取值与括号内的真值相同,当yi=j成立时函数值为1,不成立时函数值为0,最后通过adamoptimizer优化器最小化误差函数。
3 实验结果与分析
3.1 数据集的选用
本研究的工作是在基于垃圾识别分类中两个数据集上来进行实验的,两个数据集分别是:训练集train和测试集test。训练集包含了40个类别,共1000张垃圾图像,测试集包含了40个类别,共400张垃圾图像。此次实验采用1000张采集到的图片对Res Net网络进行训练。首先对图像进行预处理,考虑到网络模型结构把图像裁剪为224*224,然后对图像进行中值滤波操作,按批训练样本数对数据进行划分,为网络训练奠定基础。
3.2 实验结果与分析
Res Net算法中网络模型的训练性能和识别效果的好坏影响因素之一就是超参数。试验中将网络模型中的学习率设置为0.002,批训练样本数设置为4,训练集图片数量设置为1000,验证集数据量设置为400,迭代次数设置为6000次,结果显示在验证集上的正确率为98.9%,实验结果表明该模型整体识别效果很好。无论是训练集还是验证集,Res Net算法都具有收敛速度快、正识率高的优点;同时在验证集上的识别效果比训练集上好,说明网络避免了过拟合现象。当设定学习率为固定值0.0002时在验证集上正识率为99.4%,ResNet50模型在不同学习率不同时的准确率、误差如图2所示。
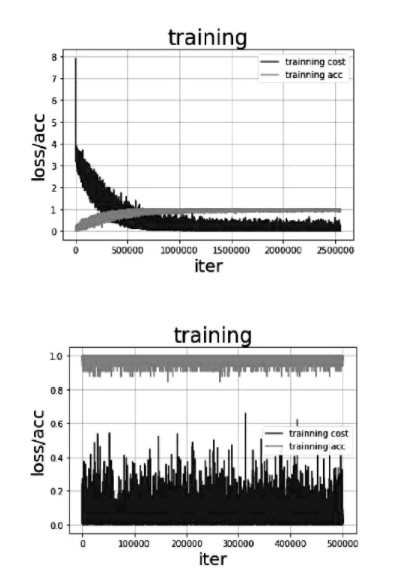
图2 准确率、误差图
4 结语
本研究通过阅读大量的文献,总结多个相关的实验经验,结合深度卷积神经网络在模式识别中的突出表现,提出了一种基于Res Net算法的垃圾图像识别分类算法。本研究的ResNet网络由5部分组成,分别是卷积层、池化层、全连接层以及softmax层。该模型与传统的卷积神经网络相比,具有以下优点:避免过拟合,收敛速度快,残差学习网络使深度网络训练变得容易。垃圾图像正识率为99.4%,Res Net算法具备较好的识别效果和鲁棒性,在其他机器视觉的应用领域具有一定的推广作用。虽然Res Net算法达到了预期的分类识别效果,但仍有不足之处,比如实验所用到的图像都是自己拍摄的,目的性明确,所以喜好片相对噪声较少,而且数据量不是很大。后续会继续采集图像,加大噪声干扰,以求做出更加精准和更具实用效果的网络模型。
参考文献
[1]董子源韩卫光.基于卷积神经网络的垃圾图像分类算法[J].计算机系统应用,2020,29(08):199-204.
[2] Krizhevsky A, Sutskever I, Hinton GE. Image Net classific ation with deep convolutional neural networks .Advances in Neural Information Processing Systems. Lake Tahoe, NV,USA 2012.1106-1114.
[3] He KM,Zhang XY,Ren sQ,et al.Deep residual learning for image recognition.Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas,NV,USA. 2016.770-778.
[4] Ozkaya U,Seyfi L.Fine-tuning models comparisons on garbage classific ation for recyclability ar Xiv:1908 .04393,2019.
[5] Mittal G,Yagnik KB,Garg M.et al.Spot Garbage Smartphone app to detect garbage using deep learning. Proceedings of2016 ACM International Joint Conference .Heidelberg,Germany.2016.940-945.
[6]邹倩陆安江李春红.一种中值 滤波和改进阈值函数的图像去噪算法[J]智能计算机与应用,2020, 10(08):124-126+130.
[7]朱超平,杨艺于YOLO2和Res Net算法的监控视频中的人脸检测与识别[J]重庆理.工大学学报(自然科学),2018,32(08):170-175.
[8]陈玉洁纡神经网络的手势识别算法的设计与实现[D].湖南大学,2019.
图像识别论文第二篇:一种概率神经网络在图像识别中的应用方法
摘要:图像识别精度的高低直接影响着态势感知系统的性能,针对在复杂异构环境中提取图像关键要素难以识别的问题。该文提出了一种概率神经网络识别图像的方法。应用这种方法,首先,该文通过粗糙集属性约简原始数据,过滤掉冗余属性;然后,该文使用概率神经网络这种模型对提取的数据集进行分类训练。这是一种有效、可行的图像识别方法,与其传统方法相比,该方法明显地提高了图像识别的准确性,为图像识别态势评估和预测提供了有力的理论保障。
关键词:概率神经网络;图像识别;人工智能;
1 背景
世界上许多事物都有一定的结构,我们可以用它来组织思想。我们使用心理数字线组织其他类型的信息,最明显的就是数字。概率神经网络应用到网络空间安全[1],图像的识别中。概率神经网络的一个定义特征是它们的词表征,是高维的实值向量,在这种结构中,词被一些学习到的查找表(lookup-table)转换成实值向量,这些向量被用作一个神经网络的输入,其主要优势是其分布式表征实现了一定水平的泛化,而使用经典的n-gram语言模型是不可能办得到的。作为概率神经网络中一种概念,数量大小可表征在单一维度上(即在一条心理数字线上,一般来说,小数字、坏的、悲伤、不道德、年轻表征在这条线的左侧,大数字、好的、开心、高尚、年老等表征在右侧)。牛津大学实验心理学系Luyckx和Summerfield等人在e Life杂志上发表文章,他们做健康训练实验,将被试6个不同颜色的驴子照片与六种不同的奖励概率联系起来,通过试误,被试学会了根据驴子获得奖励的可能性对它们进行排序。Luyckx等人将被试驴子观察大脑活动与观察数字1-6时的大脑活动进行比较。驴的EEG活动模式对应于它们在心理数字线上的数字。因此,驴子1以最低的奖励概率,产生了类似于数字1的大脑活动模式,以此类推,产生了类似于对应数字的大脑活动模式。实验表明,我们不是以非结构化的方式学习,而是利用过去关于刺激之间的关系知识来组织新的信息,这种现象称为结构对齐。Luyckx等人的研究结果表明人类是通过对世界结构的一般理解来学习新事物,这对教育和人工智能有着重要意义。例如,人教授计算机了解项目之间的关系,而不是孤立地学习项目,计算机可能会更有效地学习。
新工科中人工智能中的机器学习是研究训练计算机的学习行为。深度学习是属于机器学习,人工神经网络的研究促进了深度学习的发展,深度学习有多种模型,其中,多个隐藏层的多层感知器是一种深度学习的模型[2]。建立模拟人脑进行分析学习的神经网络是研究深度学习的动力源泉,图像识别、声音识别、文本识别等都是模拟人脑的运行机制来分辨识别的[3]。在深度学习的理论下,机器可以模仿人的活动,例如视听和思考等,克服了人脑的一些局限性,从而人工智能相关技术有了突飞猛进的发展[4]。香港中文大学的多媒体实验室是最早应用深度学习进行计算机视觉研究的华人团队。
20世纪40年代,美国数学家W.Pitts和心理学家W.McCulloch首次提出人工神经网络的概念。1957年,F.Rosenblatt提出了一种新的人工神经网络感知器模型,使用最小二乘法或者是Hebb学习规则来训练感知器模型的参数,这也是目前提出时间最早且结构最简单的人工神经网络模型。之后又出现了新的感知器模型(Mark I),这是第一个通过硬件实现的模型,标志着人工神经网络的计算开始向硬件方向发展。感知器采用的是阈值型激活函数,这是只有一层神经元的前向人工神经网络。通过对数据的提取训练之后获得网络权值,对应于一种输入可以得到1或者0两种输出,这就实现了对目标的分类。但是,这也表明了感知器的分类能力没有足够的优秀,目前只能处理二元分类,这取决于它只有一层神经网络,所以不能处理不可分问题。
2 概率神经网络简介
2.1 概率神经网络的特点
1989年,D.F.Speeht博士提出概率神经网络(Probabilistic Neural Network)。概率神经网络经过这多年的发展,它凸显出自身独特的特点:
1)快速度收敛,训练简单,方便使用。在PNN网络中,训练样本的值赋予隐含层的神经元,输入样本值作为神经元的权值。这样,用PNN网络所形成的判决曲面与贝叶斯最优准则下的曲面可以很逼近。
2)隐含层由非线性映射函数作为径向基,这样选择的优点是具有很强的容错性。若样本数据充足,概率神经网络函数就能收敛,避免陷入局部极小的困境。
3)取概率密度函数作为隐含层的传输函数,分类结果不受影响。
4)扩充性能好,易于硬件实现。网络的学习过程简单,增加或减少类别模式时不需要重新进行长时间的训练学习,各层神经元的数目比较固定。
从本质上说,它属于一种有监督的网络分类器,基于贝叶斯最小风险准则。
2.2 概率神经网络的技术特点
概率神经网络的结构是属于一种前向型的神经网络结构,而且是径向基网络的一个重要分支。概率神经网络建立在贝氏法则理论基础上,可以快速且有效地解决任意维度输出的分类应用问题上关于输入向量大小的问题。由于网络结构上的特点,连续值或二进制值都可以处理的,因而,可以解决不同形式的问题。而且在面临因为系统外界环境因素改变时,概率神经网络仅需对新进的分类数据定义权值而无须改变全部的网络权值。概率神经网络连接权值采取一次设定,并且直接从训练范例中加载所需数据,无迭代过程,所以,概率神经网络的学习速度十分快速,这对网络的训练是一个很重要的过程。
2.3 概率神经网络的结构图
概率神经网络的结构如图1。
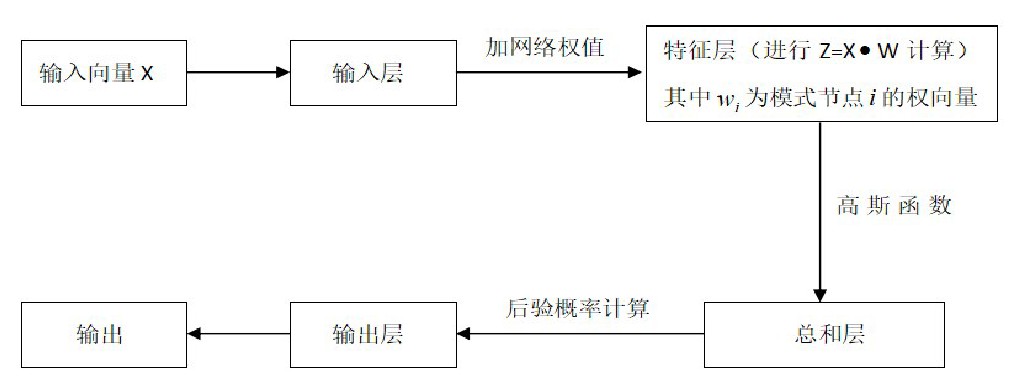
图1 概率神经网络结构图
首先,输入层接收一个m维的向量X,经过加权,再传给模式层的所有节点,模式层的节点根据不同的输出分成不同的类,这些节点执行高斯函数转到总和层;总和层节点计算特征层节点的输出来产生与每一类相对应的概率密度函数再合成计算;在一定决策规则下,输出层产生输出。
3 图像识别技术的特点及应用
图像识别是机器视觉的一个分支。计算机应用机器视觉理论的处理方法和技巧,结合神经网络以及设备来进行图像采集和识别。在机器视觉理论中,图像识别主要利用软件对图片中的地理位置、物品、人物、形态动作和手工笔迹进行分辨的能力[5]。
3.1 图像识别技术的特点
对于人类和动物的大脑来说,识别物体是很简单的,但是同样的任务对计算机来说却是很难完成的。当我们看到一个东西像树或者汽车或者我们的朋友,我们在分辨它是什么之前,通常不需要下意识地去研究它。然而,对于计算机来说,辨别任何事物(可能是钟表、椅子、人或者动物)都是非常难的问题,并且找到问题解决方法的代价很高。图像识别采用模拟人脑进行识别的方式。根据机器学习,我们可以通过图片的训练,教会计算机识别图像元素。在大型数据库中,计算机对数据呈现的模式进行识别,对图像进行辨别,然后形成图像相关的标签和类别。
3.2 图像识别技术的应用
图像识别技术有许多应用,其中最常见的就是图像识别技术助力的人物照片分类[6]。谁不想更好地根据视觉主题来管理巨大的照片库呢?小到特定的物品,大到广泛的风景。图片识别技术赋予了照片分类应用的用户体验新感受。除了提供照片存储,应用程序也可以更进一步,为人们提供更好的发现和搜索功能。有了通过机器学习进行自动图像管理的功能,它们就可以做到这一点。在应用程序中整合的图像识别程序界面可以根据机器所鉴定的特征对图像进行分类,并且根据主题将照片分组。图像识别的其他应用包括存储照片和视频网站、互动营销以及创意活动,社交网络的人脸和图像识别,以及具有大型视觉图像库网站的图像分类。
3.3 图像识别应用领域
图像识别的过程为:将图片信息输入到含有多层次概率神经网络中进行处理;在最低层中对刚开始输入进来的原始像素进行常规操作,处理之后就是原始输入的图像纹理以及它自己的边缘特征,这些特征包含了像曲线,直线等各种形状;中层网络会把上一次从下层网络上获得的信息再仅需进行加工处理操作,把这些信息抽象变成更高层次的效果;最高层网络因为能够描绘出整个输入图像的全部整体特征,经过多次处理之后,机器会获得识别该输入原始图像的强大能力。但是电脑识别图像的全部过程里,电脑进行自主的学习完全没有人的干预操作,机器自己发现图像的特征,不需要人工干预。
深度学习中应用程度最高的就是图像识别,Image Net比赛更是将图像识别的热浪推向高潮。通过过拟合技术,使得神经网络可以对拟合数据进行更好的处理,提高了识别的效率。深度学习模型是图像处理技术的完美融合,不仅可以提高效率,还可以提高准确率。
深度学习的快速发展让机器学习来到了从没有过的高度,受到了各界的广泛的关注,一定程度上推动了相关领域的发展。相信随着算法和理论进一步发展,深度学习将会在更多的领域得到应用。
4 概率神经网络对图像识别技术的作用
图像识别不是一项容易的任务,一个好的方法是将元数据应用到非结构数据上。聘请专家对音乐和电影库进行人工标注或许是一个令人生畏的艰巨任务,然而有的挑战几乎是不可能完成的,诸如教会无人驾驶汽车的导航系统将过马路的行人与各种各样的机动车分辨出来,或者将用户每天传到社交媒体上的数以百万计的视频或照片进行标注以及分类。解决这个问题的一个方法是使用概率神经网络。简单地说,过拟合一般发生在模型过于贴合训练数据的情况下,一般而言,这会导致参数增加(进一步增加了计算成本)以及模型对于新数据的结果在总体表现中有所下降。理论上,我们可以使用传统概率神经网络对图像进行分析,但是实际上从计算角度来看代价很高。举个例子,一个传统的概率神经网络在处理一张很小的图片时(假设30*30像素)仍然需要50万个参数以及900个输入神经元。一个相当强大的机器可以运行这个网络,但是一旦图片变大了(例如500*500像素),参数以及输入的数目就会达到非常高的数量级。根据概率神经网络的构建方式,一个相对简单的改变就可以让较大的图像变得更好处理。改变的结果就是我们所见到的卷积概率神经网络,概率神经网络的广适性是他们的优点之一,但是在处理图像时,这个优点就变成了负担。卷积概率神经网络对此专门进行了折衷:如果一个网络专为处理图像而设计,有些广适性需要为更可行的解决方案做出让步。对于任意图像,像素之间的距离与其相似性有很强的关系,而概率神经网络的设计正是利用了这一特点。这意味着,对于给定图像,两个距离较近的像素相比于距离较远的像素更为相似。然而,在普通的概率神经网络中,每个像素都和一个神经元相连。在这种情况下,附加的计算负荷使得网络不够精确。概率神经网络通过消除大量类似的不重要的连接解决了这个问题。技术上来讲,概率神经网络通过对神经元之间的连接根据相似性进行过滤,使图像处理在计算层面可控。对于给定层,概率神经网络不是把每个输入与每个神经元相连,而是专门限制了连接,这样任意神经元只能接受来自前一层的一小部分的输入(例如3*3或5*5)。因此,每个神经元只需要负责处理一张图像的一个特定部分。(顺便提一下,这基本就是人脑的独立皮质神经元工作的方式,每个神经元只对完整视野的一小部分进行响应)。
5 结束语
本论文总结了概率神经网络技术特点和应用方法,涉及从简单的应用到通用人工智能实体概念化等一系列应用问题的开发。图像识别和语音识别的研究领域是人工智能的重要研究领域。概率神经网络未来的工作,我们打算实验性地比较不同的图像识别方法,以作为迭代地构建高质量的用于未来机器学习模型,人类对奖励概率的学习伴随着对价值表征的结构比对,这种比对与抽象大小概念的神经编码相一致,表明结构对齐可以促进学习的迁移,促进概率神经网络在图像识别与应用技术中的使用。

本文通过引入人工智能技术,对其进行了创新研究。将本文提出的识别方法应用到实际当中,能够有效增强识别性能,具有更高的实用价值。...
本文分析了几种常见的图像预处理技术,有效的图像与处理手段,不但能最大程度保留图像的有用信息,还能降低后续图像学习、检测、识别的难度,并最终转化为识别准确率的提升。...
本文除了研究铺面检测车的检测与图像处理原理外,针对铺面损坏严重程度与铺面损坏种类做更进一步的实验与验证,以研究铺面检测系统的稳定性与可行性,达到规范所要求的检测精确度。...

外观检测作为枪弹装配生产最后的工序,需要通过对弹身360旋转检测,挑选出弹身有划伤、凹坑、油污、裂纹等缺陷的产品,才能保证枪弹的装箱合格率。目前枪弹生产中外观检测大都采用人工目视检测的方式,被检子弹由传输丝杠带动旋转,凭肉眼检查是否存在外观...
舌诊作为中医望诊的重要组成部分,一直是临床辨证及疗效评价的重要依据之一,传统舌诊方法主观性强且易受光线、环境等不确定因素的影响,因此,限制了中医诊断方法与技术的发展。然而20世纪90以来,计算机图像识别方法的应用促进了舌诊客观化的发展,数字图...
数字图像处理技术在不同领域中的运用,是通过不同关键技术点,将图像处理与应用模式相关联的,在一定程度上强化图片信息的处理质量。...

数字图像处理技术在不同领域中的运用,是通过不同关键技术点,将图像处理与应用模式相关联的,在一定程度上强化图片信息的处理质量。...
大蒜在我国种植面积广泛,年产量约175万t,出口31万t,出口规模为世界第一。由于不同国家对大蒜规格要求不同,我国作为大蒜的主要生产和出口国,要使大蒜产生巨大的经济效益必须适应国际市场对大蒜的规格要求,如:美国、日本市场要求柄长为2cm;东南...

文章就人工智能图像识别技术在电力系统中的具体应用进行论述,对如何利用二次屏柜展开智能监控进行分析,对指示灯、开关、压板、仪表盘等不同监控对象进行图像识别分析算法的设计,将系统结构设计以及安装部署进行有效的规划,参照数据管理、显示平台等多个层...
本文将从数字图像处理、图像识别方法在人脸图像识别中的应用以及图像识别系统在识别残损纸币中的应用角度,对系统开发思路进行探析。大家在相关论文写作时,可以参考这篇题目为处理与识别数字图像的应用探析的数字图像处理论文。原标题:数字图像处理与识别...