普通语言学论文


现代人走出非洲, 人类语言也随之扩散到世界各地. 经历数万年, 不同地区的人群形成各自的文明, 也形成了多样性的语言. 语言的多样性反映了演化的复杂性, 但犹如生物自简单而复杂, 语言亦非生而复杂. 历史语言学证明, 几乎所有复杂的词法形态和句法现象都是逐步产生的. 但早期口语一定包含了人类语言作为区别于其他生物交流方式的符号系统所拥有的基本结构, 并清晰地外显. 这种结构经历数万年多样性演化也不会丧失, 而会在现代语言中传承下来, 这就是我们称为语言“基因”的词形结构或词音节结构(word-syllable structure). 词形结构的多样性或差异性决定了语言的类型和面貌, 是观察现代语言分类和追溯语言历史渊源的最重要要素,也是追踪人类族群迁徙和地理分布的参照线索.
1 什么是词形结构
词形结构是词义的语音形式和形式的结构, 由音节和组成音节的音素构成. 它不是一种元音或辅音这样的个体音素形式, 而是一种结构体. 结构体的表达是把词的具体的音素(如a, b, m)抽象为音类C,V (C 表示辅音, V 表示元音)并以音类符号的排列结构来表达, 例如英语词 sesame [ses?mi]由 6 个音素构成3个音节组织而成, 即 CV·CV·CV. 本文约定, 词形结构有时候可以简称结构, 例如 CV 结构, 形态则指音类符号排序的各种形式. 关于音节, 近年来学者们有一项极为重要的发现, 他们认为 CV 结构是人类语言偏好形式或基本形式. 不过, 尽管这个结论来自心理实验、行为实验、语言习得、生成音系学等多个领域, 从真实词形中抽取的单个 CV 形式却没有语言单位价值, 唯有整体词形才符合词的音义结合的本质. 由此, 我们推论人类语言词形结构的初始形态很可能是{CV}p(‘p’即 poly-, 表示多音节), 其中当然也包含了单一 CV 词的结构.
假定我们接受人类偏好的 CV 是词形结构的基本构成要素, 也接受{CV}p是早期共同语言的词形结构形态, 就可以承认以下推理的合理性: 在语言的演化过程中, 元音或辅音的演化脱落造成了辅音相连或元音连缀的相对复杂的词形结构的出现. 例如英语 pluck [pl?k]的词形结构是 CCVC, 有辅音丛和辅音韵尾, 但仅一音节长, 这个单音节词来源于古英语多音节的 ploccian, 中古低地德语 plucken, 再比较拉丁语族罗曼斯语构拟*piluccare(‘*’表示词形构拟),可以判断这个词历史上曾发生多处元音脱落. 日语词 kudamono(水果)结构单纯, 但是 CV·CV·CV·CV 有四个音节长, 词形结构很接近预设的初始形态. 汉语是声调语言, ma55(母亲), ma35(苎麻), ma214(马), ma51(骂), 虽然都是 3 个音素(含 1 个声调)和 1 个音节组成, 具有相同的简单结构 CV(Tone), 但同一个音节声调不同, 有多个意思. 汉语乃至东亚和东南亚大多数语言一直被认为是世界语言的特例, 词形长度已达到最简地步, 但正是这一点证明 CV 是词形结构的最基础要素.
人类早期在世界的活动主要呈现为迁徙模式,随着人口增长逐步扩散到世界各地. 如果现代人曾拥有相同的初始语言, 词形结构也应具有一致的初始形态, 正是数万年的迁徙扩散、人群的隔绝和语言的随机演化导致了词形结构的地理区域差异, 造成词形结构在世界范围内呈现出高度复杂性和多样性.
2 词形结构进化的历史深度
Atkinson曾以音素作为人类语言基因要素探索人类起源于非洲的命题, 这种思想有着深刻的学术背景. 全球人类基因组创始人 Cavalli-Sforza 等人认为语言进化与基因进化具有平行性, 现存的大约 5000种语言与今天的民族和土著部落相当吻合.
甚至进化论奠基人达尔文也提出“假如我们拥有一个完善的人类系谱, 则人种排列成的系谱将能提供现在整个世界上所说的各种语言的最好分类”. 不过,Atkinson采用的音素和音素数量并不是语言中稳定的参项, 语言不断发生音素变化, 从一种音素变为另一种音素, 例如 b→β, k→x, 也经常失去原有音素,或产生新的音素, 音素和音素数量在一代代人之间变化传承, 累积起来足以使一个语言的音素系统面貌全非. 历史语言学家 Campbell指出: 由于跨越如此漫长的年代, 发生如此巨大的变化, 原初语言没有任何东西以任何形式在现代语言里残留下来.
Campbell 的观点有点片面, 个体音素的确不停地变化, 词形结构也会变化, 但任何语言都保持着动态稳定的音系、词汇和基本词形结构, 语言交流功能不会中断. 迄今, 语言描写和类型研究告诉我们, 任何语言都没有所有词形变为{C}p或者{V}p这类结构, 也没有所有词都以 V 起始的语言, 没有所有词都以 C 结束的语言, {CV}p结构仍然是人类语言的基本形式.
上文推论人类语言词形结构具多音节性, 其中蕴含了语言起源的单源性假说. 这个假说基于语音变化的原理和规则: 所有语言普遍发生语音弱化和脱落,反之, 增音(音素)则是随机的、临场的和语流音变性的.
换句话说, 语言伊始呈现多音节词面貌, 经过脱落,词长逐渐缩短, 形态复杂度逐渐增加. 这个观点跟 20世纪早期 Jespersen的观点一致, 他认为语言是从原始多音节词朝单音节词发展. Jackendoff对人属(包括尼安德特人)的发声音姿单位提出一个有趣的描述:
每个音节都是一个整体发声音姿, 用 10 个这样的音姿, 人们就能建立 100 个双音节原始音节发声串和1000 个三音节的原始音节发声串, 这种方法很好地实现了开音节结尾. Jackendoff 所说“整体发声音姿”即音节, 他所描述的开音节表明音节形式就是 CV,然后可以组成双音节词 CVCV 或更多音节的词.
按照音素脱落的模式, 词形结构在漫长的数万年演化过程中产生了复杂的多维度演变, 导致世界语言演化出不同词形形态结果. 我们采用递减算法来模拟音素脱落, 以观察语言的演化路径和深度. 设定初始词形长度为 3音节, 演化过程中每次脱落一个音素, 如图 1 所示演化模型.
从演化过程看, 图 1(a)中并非每种结果都实际出现过, 语言凭借自身的自组织系统会选择恰当的路径,因此, 在某些节点必定存在实际出现的词形结构. 深度上, 词形至少经历两次元音脱落才可能转变为单音 节 词 : →CVCVC→CVCC; →CVCCV→CVCC;→CVCCV→CCCV; →CCVCV→CCCV, 余则经历更多层次. 元音和辅音脱落都带来复杂的词形形态, 例如 CCCV(spray), VCVVC(oriole)等, 因此单个音节可能呈现 CV, V, VC 3 种形态, n 个音节可能产生 3n?1种词形结构(至少保留一个元音). 图 1(b)表示词形结构演化过程中可能会出现相同的形态, 但是, 由于音素值的差别, 例如 CV 可能是[ta]或[si]等, 语言中产生的同形词相对还是有限的.【图1】
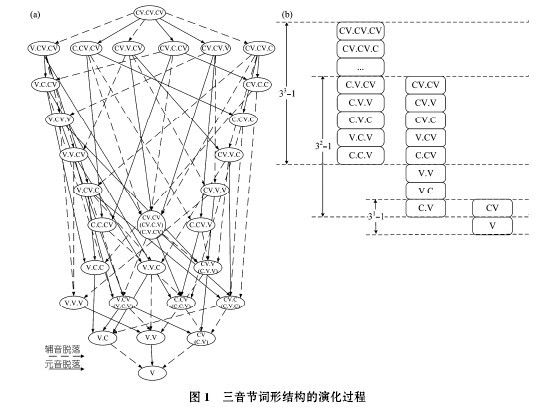
在东亚和东南亚区域, 有上百种语言已发展为单音节词语言, 它们很可能都是这个模型的原型. 至于导致语言演变的诸多其他因素, 例如随机变化、地理分布、人口规模、文化接触、区域趋同等, 本文结语有所提及.
3 词形结构多样性的地理分布
选取世界8个区域179种语言的基本词汇(Swadeshlist)数据为样本, 尝试使用 Shannon-Wiener 多样性计算模型对词形结构的类型和数量进行分析【1】
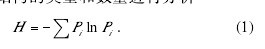
式中 H 代表词形结构的多样性, Pi表示具有第i 种词形结构的词汇数占总词汇数的比例.
根据计算结果, 我们编制了表S1 的词形结构数据, 按语言的分布区域经纬度绘制地理分布图(图 2).
该图以渐进颜色表示词形结构的多样性变化, 深蓝色表示多样性较低一端, 深红色表示多样性丰富一端.
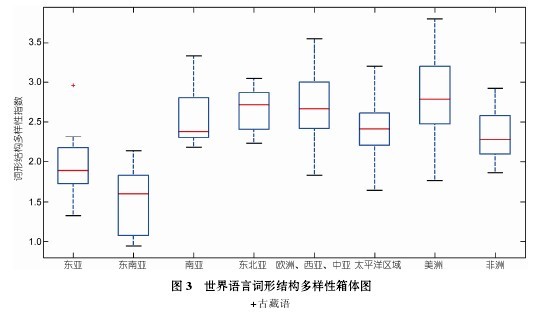
然后按照 8 个语言地理区域(分别是: 东亚, 东南亚,南亚, 东北亚, 欧洲、西亚和中亚, 太平洋区域, 美洲和非洲)数据给出词形结构多样性的箱体图(图 3).
词形结构的多样性是由演化创新造成的. 最重要的指标是词长变异和形态变异, CVCV 跟 CV,CVCVCV 词长不同, 也跟 CVC, CCV, CVV 形态不同.
图 2 显示出欧洲、西亚等地多样性最丰富, 这主要是该区域语言词的形态变异造成的. 东亚和东南亚多样性最低主要是词长变异造成的, 反映了它们的孤立语性质. 非洲、美洲、太平洋区域语言很可能在词长和结构上保留较多早期形式. 显然, 现代语言的多样性聚类跟地理区域分布呈相关关系, 图 3展现了这样的聚类关系.【图2.略】
4 词形结构的偏移度量
词形结构多样性指数涵盖了一种语言的词形结构的总体丰富度与均匀度信息, 但随机演化结果也可能造成低丰富度和高均匀度系统与高丰富度和低均匀度系统具有相同的多样性指数, 这种情况在图 3 显示为多个区域多样性指数不彰. 因此, 还要对多样性产生的根源, 即词形结构本身进行分析. 那么,词形结构本身又隐藏着什么样的特征信息呢? 这些特征信息能否确定现代语言处在语言演变过程中的什么位置呢? 上文已经提出词形结构的初始形态为{CV}p, 如果把现代语言中的复杂词形结构看作对词形结构初始形态的偏移, 那么分析现代语言的偏移情况即可度量现代语言的演化程度.【图3】
假设词的元音个数为 nv, 辅音个数为 nc, 音节长度为 ns. 根据初始结构的特征, 其元音数与辅音数应等于音节长度 ns. 以元音数与辅音数构建二维坐标系, 将现有词形与其初始结构分别表示为该坐标系第一象限中的两个向量 m(nv, nc)与 o(ns, ns), 如图 4(a)所示. 若这两个向量之差为向量 x , 我们定义 x 的模(即长度)为该词形结构的偏移距离, 元音与辅音的脱落数量越多, 偏移距离越大. 同时, 我们将两个向量的夹角a 定义为该词形结构的偏移角, 偏移角为正则词形结构向元音丛倾斜(辅音脱落), 反之则向辅音丛倾斜(元音脱落). 如果词内辅音和元音脱落数相同,统计上部分词形结构仅偏移距离改变, 不发生偏移角变化, 以三音节词为例, 可能有 6 种变化, 其中仅两种有偏移距离变化(删除线表示脱落): CV.CV.CV→CV.C.V, CV.CV.CV→C.V.CV, 其余多数偏移角和偏移距离都有变化, 例如: CV.CV.CV→C.CV.V, CV.CV.CV→V.C.CV.
通过几何计算, 可以获得适用的偏移距离计算公式:【2-3】
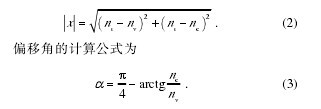
为直观地分析词形结构的偏移情况, 我们将单个词形结构的偏移数据映射到极坐标系当中的一个点上, 其极径与极角分别代表偏移距离与偏移角. 那么一个语言的偏移情况也就可以通过所有词形结构的偏移距离与偏移角来度量了. 本文对 179种语言词表的词形结构进行计算, 得出各种语言的词形结构偏移距离及偏移角数据, 以此为基础绘制了世界语言的偏移情况坐标分布图, 如图 4(b)所示.
从数据看, 全部语言的偏移角在[?17.8, 12]弧度范围以内, 其中 Chewong 语偏移角?17.8 弧度, 表示该语言的辅音丛最突出. 全部语言偏移距离范围是[0.148, 2.678], 其中 Western fijian 最小(0.148), 表明最接近{CV}
p结构, 而书面藏语为 2.678, 辅音丛尤为丰富. 就全局来看, 有如下两个显著的特点: (1)偏移角为负的语言要远远多于偏移角为正的语言,说明大多数语言的词形结构呈现辅音丛形态; (2)偏移角为正的语言其偏移距离普遍较短, 这说明即使是元音丛形态为主的语言, 其元音丛形态相对简单.
对比而言, 辅音丛形态为主的语言偏移距离从短到长分布比较均匀, 说明辅音丛具有从简单到复杂的多种形态.
具体而言, 以各项中值数据看(表 1), 欧洲、中亚、西亚和东北亚语言(图 4(b)中圆圈)的偏移距离高于其他区域语言, 并且严重朝辅音丛方向偏移, 加之词形较长, 说明这些语言既有较长的词形, 也有丰富的辅音丛, 故而归为一个类型. 美洲、非洲、太平洋区域语言(图 4(b)中星号)的偏移角很小, 词长最大,说明整体偏移不大. 实际上, 美洲、太平洋区域有部分语言偏移角呈正值, 即辅音脱落较多, 形成元音丛,这样的现象在世界其他语言不是主流变化. 东亚和东南亚语言(图 4(b)中三角形)最为独特, 目前采集的Swadesh 词汇绝大多数是单音节词形式, 少量是双音节派生词和复合词, 由于历史上可能的 CV 连续脱落,无法从长度追溯初始形态. 而且, 东亚和东南亚语言词形形态从简单到复杂形成多个等级, 藏羌语言辅音丛丰富, 缅彝、景颇、侗台、苗瑶语次之, 汉语最简单, 它的偏移角和偏移距离数据只能从单音节词的辅音丛计算, 偏移距离明显较小. 作为对比, 我们单独列出了汉语的数据和形态特征.【图4.表1】
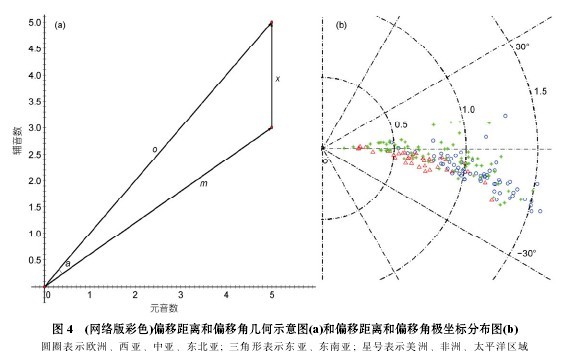
据此, 可以根据词形结构的形态将世界语言划分为 3 种类型, 欧洲、西亚、中亚、东北亚语言是辅音丛和多音节并重形态, 美洲、非洲、大平洋区域语言是简单辅音和多音节形态, 东亚和东南亚语言是单音节词以及单音节词内单一辅音与辅音丛交替的形态. 南亚语言是多音节词语言向单音节词语言的过渡形态, 暂未列入统计数据和归类.
5 结语
世界语言词形结构的多样性和偏移量模型代表了人类语言演化的多样性方向和演化过程. 数万年来, 随机演化因素造成的元辅音脱落突变并产生新的词形结构形态, 并为不同族群传承下来, 产生了语言地理分布上的多样性. 如果说现代人走出非洲至今是人的大历史, 近 1 万年来, 或者新石器中晚期以来只算得小历史. 可是这个小历史以数倍于前的演化速率改变了人类, 其中人口规模、人群迁徙、文化接触、区域趋同、技术发展, 无一不对人的进化和语言的变化施加社会性选择的影响(与自然选择对应). 我们采用的现代语言数据蕴含了这段小历史作用的结果, 例如, 汉语因为社会状态开放、人口数量较多、外部接触程度高, 在抑扬格词模式演化中转变为单音节词语言. 日语是一种倾向词长优势的语言, 虽然地理位置在东亚, 多样性和偏移量等数据更接近美洲、非洲和太平洋区域语言, 这与日语历史上所处封闭的岛屿文明环境必然相关. Chewong 语是西太平洋区域马来西亚的一种南亚的孟高棉语系语言(Austronesian languages), 因其同时拥有多种词形结构: 单音节词, 一个半音节词; 双音节词, 复辅音声母词, 导致很高的复杂形态. 本文的词形结构数据和阐释模型意在解释各语言在人类语言进化过程中位置, 在进一步的微观研究中, 以上人口、地理等数据将逐步加入讨论.
迄今为止, 词形结构的形态演化最复杂的英语和长度演化最简短的汉语都在不同程度上保存着人类语言古老的词形结构面貌. 由此可以说, 词形结构是人类语言的“基因”, 是语言演化中保存至今的类似考古学化石型的遗存之一.

范畴化是人对客观世界及其自我构建的根本方式。除了原型范畴化,学界还提出了各种范畴化理论,其中体现了语言学史两线之争的范畴化理论当属梯度范畴化。从通俗意义上说,范畴化就是分类。在语言学上,分类是为了讲语句结构,其包括结构上的分...
一、引言无论是在国内还是国外,词典编纂历史源远流长,而严格意义上的词典学研究则是最近数十年的事.1971年,捷克词典学家LadislavZgusta的专着ManualofLexicography(《词典学概论》)出版,标志着词典学已成为一门相对独立的学科;而在国内,对词典学...
引言文化是丰富多彩的,语言也是各式各样的。由于不同民族的文化与语言有一定的差异性,使得不同文化之间交流常常会出现困难。不同民族产生语言的文化背景不同,因此不同文化背景、语言的人在进行交流时,容易出现缺乏共同语言而难以交流的情况,如中国人见...
1852年,《罗氏英语分类词典》(RogetsThe-saurusofEnglishWordsandPhrases,以下简称《罗氏》)出版,自此,英语词典家族中多了一位新成员,类义词典作为一种新的词典类型也就此问世。之后,英语类义词典编纂逐步发展,各种类义词典相继出版。1981年《朗文...
一、电子词典研究的背景及重要性人类的信息载体在不断变化,从最古的甲骨文、青铜铭文到竹简、帛书,再到纸质印刷,新载体不断取代旧载体,成为人类信息的一般传播媒介.而今的互联网时代,作为信息主要载体而存在上千年的纸介质受到光电磁介质等的冲击.年轻的语...
一、引言词汇是语言中词语的集合。关于语法有狭义和广义两种理解。狭义的语法指语言研究的一个层面,独立于音系学和语义学,通常包含句法学和形态学两个分支。按照这一含义,语法研究词与构词成分如何组合起来形成句子。广义的语法指语言结构关系的整个系统...
1词汇变异现象概述所谓词汇变异是相对于常规语义而言.认知语义学理论认为词汇作为语言单位,是一种固着在语言使用者的大脑中的认知常规.与此概念系统相关的意义即为常规意义(Laguacker,1987).但在具体的言语交际中,由于语境要素的不断变化,原有的语言实体及...
《同音文海宝韵合编》(以下简称《合编》)是一部出土的西夏文辞书.这部辞书在形式上似乎是将按韵排列的《文海宝韵》改用《同音》以声为纲的形式重新排列了一遍,并做了简化.如此处理很好地将《同音》《文海宝韵》两部辞书的优点糅合在了一起.这样一部有特点...
声训是训诂学中的一种训诂方法, 最大的特点是“因声求义”, 它对音义关系的探索属于语言学的范围。从索绪尔的普通语言学视角看声训, 声训与普通语言学思想具有契合点, 同时也存在着重大的谬误。...

声训是训诂学中的一种训诂方法, 最大的特点是“因声求义”, 它对音义关系的探索属于语言学的范围。从索绪尔的普通语言学视角看声训, 声训与普通语言学思想具有契合点, 同时也存在着重大的谬误。...