文献检索论文


一、引言 :网络时代和信息检索
随着网络技术的进步和互联网用户的猛增,网上的信息呈几何级数爆炸性地增长.其中,约80%是用自然语言表示的信息,简称"文本信息".在这海量信息中,用户要发现自己所需要的信息,犹如大海捞针一样困难.于是,信息的组织和提供,特别是怎样从文本中找到用户所需要的信息,就成为语言信息处理技术研究的一个紧迫的课题.最近几年来,一些面向真实文本的自然语言处理(Natural Language Processing,NLP)技术,包括信息检索、自动文摘、信息抽取等,发展很快,也开发出一些实用的产品,但其处理效果并不能满足用户的需要.比如,环球网上提供的各种搜索引擎,基本上都采用基于关键词匹配的技术,即根据用户提出的关键词,把包含这个关键词的各种文档按照某种顺序返回,让用户费时费力地从中寻找自己所关心的信息.用发展的眼光来看,它们最终都要被基于内容理解的智能检索技术(即语义搜索)所淘汰.要想开发基于语义和内容的检索系统,又依赖于充分的词汇本体知识资源的支持.
有鉴于此,本文介绍信息检索、语义搜索、本体知识、词汇本体知识等基本概念及其相互之间的关系,特别是Ontology这个概念的内涵从哲学本体论到信息技术的本体知识的演进、本体知识系统的构造与类别、跟汉语相关的词汇本体知识库的建设、本体知识特别是词汇本体知识对于信息检索和语义搜索的作用.希望向自然语言处理及其应用研究的学者展示词汇本体知识的特殊资源价值,同时也为语言学研究人员提供一些通向当代语言信息处理技术的路径,为汉语词汇学的研究注入面向工程应用的活力.
二、语义搜索和词汇本体知识
所谓信息检索(information retrieval)是指把信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术.显而易见,在当今网络化的信息时代,为了有效地利用互联网上海量的信息,必须有卓越的信息检索技术,来根据用户的信息需求,从大规模、非结构化的信息集合中搜索特定的信息项目(包括文本、声音、图像、数据等).但是,目前通行的基于关键词匹配的搜索技术不考虑查询请求跟网上文本在语义上的匹配,因而在查全率和查准率两个方面都不尽人意.为了解决这个问题,必须发展智能性的语义搜索技术,让真正符合用户信息需求的文档即时返回给用户.
所谓语义搜索(semantics-based search),指基于查询(queries)和文档在知识和语义上的匹配的搜索技术,区别于目前常规的基于关键词匹配的搜索技术.其中,怎样为用户的信息需求建立模型,就成为语义搜索首先必须解决的技术难题.因为语义搜索追求的是查询和文档之间在语义(包括知识和内容)上的匹配,所以对用户的查询请求必须用合适的语义(概念)框架来进行系统的表示.在目前的技术条件下,本体知识无疑是一种最合适的概念模型和知识表示工具.所谓本体知识(ontology)①,在人工智能领域指对于共享概念的明确、规范的表述,其目标是描述相关领域的知识,提供对该领域知识的共同理解,确定该领域内共同认可的词汇/术语,并从不同层次的形式化模式上给出这些词汇/术语及其相互之间关系的明确定义.也就是说,一个本体知识能够为需要在某个领域分享信息的用户定义这个领域的概念词典/术语表,其中包括了这个领域的基本概念及其关系的机器可读定义.有了合适的基于词汇的本体知识体系,就可用以对用户的查询词语和网页文档进行语义内容和概念类别分析,进行语义和概念层面的比对和匹配,从而帮助搜索引擎系统能够检索到跟用户的查询需求比较吻合的文档序列,并根据两者的相关性进行合理的排序.
由于用户的查询通常是用一个词或短语来表示他对信息的需求,因而基于语义的搜索技术需要词汇本体知识作为基础资源.所谓词汇本体知识(lexical ontology),指对一种语言的有关词汇所表示的概念(词义及相关的百科知识)的明确、规范的表述,通常用类框架结构,通过机器可读的格式,把概念、定义、关系、规则、目标语翻译、同义词、词性、父域信息和子域信息等知识内容有效地组织起来.
三、Ontology的内涵演进和本体知识的结构与类别
由于本文讨论的本体知识对许多语言学者来说还是比较陌生的,因而下面首先介绍国内外学术界对于本体知识的有关研究,内容包括 :Ontology这个概念的内涵的技术演进、服务于信息处理的本体知识的构造与类别.
1. Ontology的内涵的技术演进
本体论(ontology)本来是哲学上研究存在(being)的性质及其内在关系等抽象本质的理论.在人工智能、知识工程等计算机科学与技术领域中,本体知识(ontology)指有关领域对共享概念的正规、明确的表述.即以机器可读的格式来定义概念及其关系,用概念的层级体系来反映概念之间的关系.
在人工智能领域,Neches等[1]将Ontology定义为"给出构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成的规定这些词汇外延的规则的定义".Gruber[2]给出了最为流行的定义 :"Ontology是概念模型的明确的规范说明."在此基础上,Borst[3]给出了另外一种定义 :"Ontology是共享概念模型的形式化规范说明."Studer等[4]对上述两个定义进行了研究,认为Ontology是共享概念模型的明确的形式化的规范说明.其中包括4个要素 :
(1)概念模型(conceptualization),即通过抽象出关于客观世界中一些现象的相关概念而得到的模型.因此,概念模型所表现的含义独立于具体的环境状态 ;(2)明确(explicit),指所使用的概念以及使用这些概念的约束条件都有明确的定义 ;(3)形式化(formal),指计算机可读的,即可以被计算机处理 ;(4)共享(share),指Ontology中体现的是共同认可的知识,反映的是相关领域中公认的概念集合.因此,本体知识针对的是团体而非个体的共识.
可见,建构本体知识的目标是捕获相关领域的知识,提供对该领域知识的共同理解,确定该领域内共同认可的词汇,并且从不同层次的形式化模式上给出这些词汇/术语和词汇关系的明确定义.由此可见,本体知识的建构与语言学中的词汇研究有着天然的联系.
2.本体知识的构造和类别
一般来说,本体知识的建模元语(modelingprimitive)主要有 :类(classes)、属性(attributes)、关系(relations)、函数(functions)、公理(axioms)、实例(instances)等.其中,实例代表元素,类是元素的集合,表示某一类型的事物,也可以写成概念(concepts),指涉任何事物.属性是个体或者类所具有的性质或特征,而关系是个体和类相互联系的方式.个体和类可以通过其在层级系统中的位置,也可以通过属性相互关联.本体知识中最常见的基本关系包括 :part-of,kind-of,instance-of和attribute-of.其中,part-of表达概念之间部分与整体的关系 ;kind-of表达概念之间的继承关系,类似于面向对象的知识表示中的父类和子类之间的关系 ;instance-of表达概念的实例和概念之间的关系,类似于面向对象的知识表示中的对象和类之间的关系 ;attribute-of表达某个概念是另外一个概念的属性,attribute可以设定为具有不同的值.比如,概念"价格"可作为概念"桌子"的一个属性,相当于概念"桌子"的不同子类,其属性"价格"的值可以分别是"80元"、"120元"、"280元"等.公理是根据某种逻辑形式形成的永真式断言(tautological assertions),代表本体知识中允许进行的形式化的逻辑推导,可以看作是本体知识中的约束.而函数是一种特殊的关系,在这种关系中,前n-1个元素可以唯一地决定第n个元素.比如,关系mother-of是一个函数,其中mother-o(fx,y)表示y是x的母亲(即x叫y母亲).显然,x可以唯一地确定他的母亲y.
根据不同的应用目的,本体知识的表示方式可以是非形式化语言或形式化语言.即可以用自然语言这种非形式化语言,也可以用框架、语义网络等半非形式化结构,或者用某种形式化的逻辑语言来描述不同的知识.就目前的情况来看,使用较多的还是LoomOntolingua.
关于本体知识的类型,可以根据其对于领域的依赖程度分为4种 :
(1)顶级本体知识(top-level Ontology),描述的是跨领域的普通概念及概念之间的关系.比如,人类生活最核心的空间、时间、事件、行为等概念.其他类别的本体知识,都是它的特例.比如,美国电气及电子工程师学会标准上层本体知识小组①建立的"建议上层共用本体知识"(Suggested Upper Merged Ontology,SUMO).它只包含具有广泛性、一般性和抽象性的概念,希望为特殊领域本体知识的建立提供基础.
(2)领域本体知识(domain Ontology),描述的是特定领域(如医药、汽车等)中的概念及概念之间的关系.如英语的"doctor"有医生和博士两个意思,如果用于医药领域的本体知识中,"doctor"主要表示医生的意思 ;而在描述学位系统的本体知识时,"doctor"主要表示博士的意思.
(3)任务本体知识(task Ontology),描述的是特定任务或行为中的概念及概念之间的关系.
(4)应用本体知识(application Ontology),描述的是依赖于特定领域和任务的概念及概念之间的关系.
此外,像英语的WordNe和汉语的知网都是跟语言的词汇直接相关的本体知识体系,可以叫作"词汇本体知识"(lexical Ontology).选择在哪个层次上建构本体知识、侧重词汇语义知识还是概念与世界知识(world knowledge),说到底应该是由建构本体知识的目标和需要完成的任务来决定的.
四、四个词汇本体知识库简介
根据上文的介绍,本体知识是某一领域的共享概念的明确的形式化的规范说明.于是,对于某些个特定语言的词汇的意义(相关的概念及百科知识)、用法以及相关词汇之间的关系等的明确的形式化的规范说明就是词汇本体知识.下面,我们介绍国内外几个着名的词汇本体知识库,包括 :WordNet、中文概念词典(Chinese ConceptDictionary,CCD)、中英双语知识本体词网(TheAcademic Sinica Bilingual Ontology Database,SinicaBOW)和知网(HowNet),特别说明它们如何利用词汇资源来建立起概念网络,以及如何在概念网络中进行语义推理.
1.英语的WordNet和汉语的CCD
WordNet是普林斯顿大学认知科学实验室,在心理学家米勒(George A. Miller)指导下建立起来的词汇数据库(lexical database).它根据人类词汇记忆的心理学理论(比如,人脑的词库中名物概念的层级性组织方式),尝试用一致的形式来为人类的语言(主要是词汇)知识建立模型.WordNet收录将近150 000个词,包括名词、动词、形容词和副词.词以synse(t同义词集合)的形式被组织起来,每一个synset表示一个词汇化的概念,这个概念由一组同义词和对这组同义词的解释来表达.这样,用户脑子里如果有一个特定的概念,那么就可以在相应的同义词集中找到一个合适的词去表达这个概念.例如 :
00047131 04 n 02 accession 0 addition 0001@ 09536731 n 0000 | something added towhat you have already ;"the librarian shelvedthe new accessions";"he was a new addition tothe staff"
在这条记录中,开头的数字00047131是名词同义词集{accession,addition}的唯一的标识码,符号"@"与"|"之间的字符表示前面这个同义词集直接从属于标识码为09536731的同义词集(其意义为acquisition),最后分别是这个同义词集的释义和用例.在WordNet1.6版中,共有66 054个名词同义词集,17 944个形容词同义词集,3 604个副词同义词集,12 156个动词同义词集.这近10万个同义词集可以用来提取和代表人类常用的近10万个概念.
WordNet还通过指针(pointer)表示相关同义词集合之间的语义连接(semantic links)关系,比如 :下义关系(hyponymy)、部分-整体关系(meronymy)和反义关系(antonymy)等.这样,WordNet不是通过罗列语义特征,而是利用语义关系的指针,把相关的synset连接成一个语义网络.通过一个个语义网络,构建了一个机器可读的词库(machine readable lexicon).下面是Fellbaum的一个名词语义网络的示例(见图1):
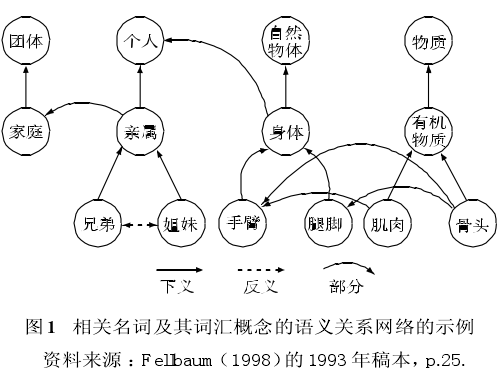
WordNet1.6描写了名词、动词、形容词和副词四类词的近10万个概念节点和500多万个语义关系,形成了一个庞大的概念网络.比如,WordNet收录了约11 000个动词,分为24 632个义项,平均每个动词有2~3个义项.动词按特定的语义关系(转精[troponymy]、反义、推演[entailment]和致使[causation])连接起来,这些关系直接或间接地表示了两个动词之间的词汇推演关系.虽然WordNet包括数量巨大的概念,但是在概念的关系方面,它并不足以支持推理.面对这种情况,许多研究者想出的解决方案是对WordNet的注释进行排歧,得到词语之间更多的关系,从而将WordNet中的注释变成语义网络,其中包含不同词类之间的关系.比如,在hungry(饿)和refrigerator(冰箱)之间存在一条路径,因为这两个标记词在food(食物)这个节点上相遇.
通过food,可以把hungry和refrigerator联系到一起,从而用于常识推理.中文概念词典(CCD)是北京大学计算语言学研究所建立的语义知识库.它参考WordNet的理念、方法和技术,根据汉语的特点对概念和关系做出了相应调整.该知识库目前大约包括10万个汉英双语概念,可以与WordNet兼容.根据于江生等[6]的介绍,CCD的特色在于 :(1)它是一个在线的词汇语义的索引系统 :词汇关系在词之间体现,语义关系在概念之间体现 ;(2)它用同义词集合(SynSet)表示一个概念,该特色可用来区别于其他的语义词典 ;(3)概念之间的继承关系(即上下位关系)是CCD结构中的主关系,上下位关系所确定的概念标记森林附加上其他关系(如 :对立关系、部分整体关系等),形成一个概念网络 ;其上的演绎规则是严格形式化了的,可应用于中文的语义分析.
2.通用的SUMO和汉英双语的SinicaBow
因为SinicaBOW(中英双语知识本体词网)是在WordNet和SUMO的基础上建置的,所以这里有必要先介绍SUMO.SUMO将人们感兴趣的领域知识规范化为一套概念、关系和公理,以促进数据的互通(inter-operation)和共享、信息的搜寻和检索、以知识为基础的自动推理和自然语言处理(比如,利用本体知识进行歧义消解).SUMO最初只考虑较高层次的概念,描述一般的不属于任何特定领域的实体和概念,从而为百科知识提供概念化的框架.比如,它的概念根节点是Entity(实体),两分为Physica(l物质的)和Abstrac(t抽象的);"物质的实体"包括在空间/时间占有位置的一切,两分为Objec(t物体)和Process(过程);"抽象的实体"指物质的实体之外的一切,四分为SetClass(集合-类)、Proposition(命题)、Quantity(数量)和Attribute(属性)等等.
SUMO希望藉由最高层次的本体知识,鼓励其他特殊领域的本体知识以其为基础衍生出其他特殊领域的本体知识,并为一般多用途的术语提供定义.现在,它已经扩展到包括一个中层本体知识及数十个领域本体知识的规模.其中,上层本体知识是在融合许多当时已经存在的高层本体知识的基础上创建的,它现在被分成11个部分,各个部分之间存在复杂的依存关系,这些依存关系被仔细明确地记录在文件之中.高层本体知识的目的是抓住最主要的、可重复使用的词项和定义,激发对更具体的词项进行明确定义的思考,并提供大规模的重复利用.为了服务于某一具体的领域,在上层本体知识的基础上,SUMO还建构了通讯、财经、恐怖主义等领域的本体知识.这些领域本体知识继承高层SUMO中的比较宽泛的概念性的区别,同时也对某一具体领域的概念和定理性的内容做出详细的说明.由于高层SUMO提供了一个包含重新使用的内容的平台,它能够更容易、更迅速地建构起这些领域本体知识.同时,由于它们跟高层本体知识相容,因而即使它们应用于不同的目的,也可以与更基础的语义层进行交互活动.
SUMO采用SUO-KIF(Standard Upper OntologyKnowledge Interchange Format)语 言 进 行 描 述.SUO-KIF具有明确语义的本体描述并支持自动推理.SUMO收录了1 000多个术语,定义了4 000条公理,可以用英语等语言做知识节点的查询,并可以进行一阶(first-order)逻辑推理.基于与SUMO兼容的领域本体知识的应用程序,由于具有相同的公共术语和定义,因而可以具有一定的兼容性.SUMO作为中立的数据交换格式,现有应用程序可以把其数据映射到公共本体知识,并且只需要映射一次.这就让系统和其他同样基于SUMO的应用具有一定程度的兼容性.同时SUMO也可以映射为更加严格的格式,比如XML、关系数据库模式和面向对象模式.这样,来自不同应用领域的电子商务等,都可以在数据和语义层次上互通.
除了包括上述内容以外,SUMO还实现了与WordNet1.6版本等的连接,一个SUMO概念会映射(mapping)到WordNet中对应的同义词集上.映射关系有三种 :(1)上位关系(hypernym),比如 :"sport"(运动)是"hockey"(曲棍球)这个词的上位概念 ;(2)同义关系(synonymy),比如 :概念"cell"(细胞)跟同义词集"cell"所表示的概念是同义关系 ;(3)示例关系(instantiation),比如 :"China"(中国)这个词所表示的概念是"nation"(国家)这个概念的示例.具体的表示方式,例如 :
00008864 03 n 03 plant 0 flora 0 plant_life0 027 @ . . . | a living organism lacking the powerof locomotion &%Plant=
上面显示了从WordNet同义词集{plant,flora,plant_life}到SUMO中的概念项目"Plant"的映射关系.其中,"&%"之前是WordNet中的内容.前缀"&%"表示其后的概念项目来自SUMO,后缀"="表示两者的映射关系为同义关系.相应地,用后缀"+"表示上位关系,用后缀"@"表示示例关系.
促发这种把词汇知识跟本体知识连接起来的动机是 :(1)可以提高SUMO在自然语言理解中的应用能力.将WordNet同义词集合映射到一个形式化的本体知识之上,可以利用SUMO中广泛的语义内容来实施歧义分化等自然语言处理中的中心任务.比如,在句子"The board approved thepay increase."中,"board"对应于两个WordNet的同义词集--"木板"和"委员会".这两个同义词集分别对应于SUMO中的"设备"和"组织"两个概念.由于只有施事能够参与"批准"这一行为,我们可以利用SUMO中关于施事的意义限制来排除歧义,将"木板"的意思从"board"中分离出去.上文已经提到,WordNet概念之间的关系不足以支持推理,而SUMO是复杂的公理化的本体知识,将WordNet与SUMO连接,可以大大提高其推理能力和对自然语言的处理能力.(2)可以核查本体知识的覆盖程度,从而帮助确定SUMO概念空间中存在的缺口.正是在核查过程中,研究人员发现了大量WordNet同义词集所对应的SUMO中的概念意义太过宽泛,这种情况就需要用更具体的概念来替代.
我国台湾地区"中研院"的"中英双语知识本体词网"不仅是一个中英双语词汇语义数据库,而且是一个把词汇知识跟本体知识直接挂钩的数据库.更加确切地说,是一个本体知识和词汇知识相结合的数据库,它更加强调词汇释义参照本体知识.跟SUMO一样,它将WordNet的10万多个概念一一英汉对译,并在此基础上将其概念与SUMO本体的概念节点建立映射关系.这样,SinicaBOW可以提供跨语言的词汇信息转换、词义的区分和词义关系的连接、语言信息与概念构架(本体知识)的连接、词汇和概念的使用领域等多方面的信息.SinicaBOW主要包括下列三方面信息 :
(1)SUMO本体知识的中文版.根据SUMO2002版本的中文数据,涵盖11大类的概念,每个大类又分为2~5个类别,总共包括3 912个概念,每个概念下附有解释和定理.
(2)中英双语领域分类树.以《中国图书分类法》为基准,参考各种知识分类与实际研究经验,提出了9大类的知识分类目录(knowledgecontents):人文学科(humanities)、社会科学(socialscience)、形式科学(formal science)、自然科学(natural science)、医疗科学(medical science)、工程科学(engineering science)、应用产业(productionindustry)、艺术(fine arts)、休闲娱乐(recreation),涵盖了427个领域.并根据语言资源的特性,加入了下列语言使用(language usage)方面的信息 :专名(proper name,说明文字符号的指涉)、语体(genre/strata,说明文字符号的使用场合)、各种语言/词源(language/etymology)、各国地名(countryname).
(3)中文与SUMO本体知识对应数据库.由中文词汇出发,经由以英文WordNet定义的同义词集(synset)为基准,对应到SUMO本体知识的概念节点.数据内容包括 :①中文词汇.10万多个词形,部分词汇对应到一个以上英文同义词集,有近15万条数据 ;②某个词形所对应的英文WordNet同义词集记录码(offset),共对应到近万个同义词集 ;③同义词集与SUMO本体知识的对应关系、与本体知识分类(SUMO概念)间的关系 ;④本体知识分类目录:SUMO概念的英文版;⑤本体知识分类目录 :SUMO概念的中文版 ;⑥词汇领域分类目录 :针对同义词集给出对应于领域分类树的领域信息.
下面是地名"安布利亚"(Umbria)和树名"枫香树"两个条目的文本文件版本和XML版本的示例 :
I. 纯文字档 :档案名称Ontological_License中英双语知识本体.txt
1安布利亚 NounISAInstantiation OF06467131N@LandArea@陆地
2 枫香树 Noun ISA Hypernym OF 08619764N @FloweringPlant@开花植物
II. XML档 :档案名称Ontological_License中英双语知识本体.xml
<Record Count="1">
<ChineseLemma>安布利亚</ChineseLemma>
<POS>Noun</POS>
<WordNetSynsetOffset Version="1.6">06467131N</WordNetSynsetOffset>
<SUMO>
<SUMORelation>Instantiation</SUMORelation>
<SUMOConcept>LandArea</SUMOConcept>
<SUMOChi>陆地</SUMOChi>
</SUMO>
<Record Count="2">
<ChineseLemma>风香树</ChineseLemma>
<POS>Noun</POS>
<WordNetSynsetOffset Version="1.6">
08619764N</WordNetSynsetOffset>
<SUMO>
<SUMORelation>Hypernym</SUMORelation>
<SUMOConcept>FloweringPlant</SUMOConcept>
<SUMOChi>开花植物</SUMOChi>
</SUMO>
</Record>
为了便于用户通过多元、友好的界面查询上述信息,SUMO将功能分割为词网、本体知识和索引三个主要单元.其中,词网又分为"中文查询"、"英文查询"以及"专门领域"三个单元.用户在"中文查询"(或"英文查询")中输入中文(或英文)词形以后,系统将显示词形搭配词类在各资源中的情况,包括出现与否以及分布频率.如果点击"WordNet1.6英中对译",那么将出现该词形所有的词义,每个词义以表格呈现该词义下的所有信息,包括所属的领域、词类、解释、翻译、同义词集、各词义关系词、SUMO概念以及英语例句.用户可以再点击任一词汇项目进行再查询.用户在"专门领域"中可以查询其他领域词汇库跟WordNet连接的信息.
本体知识由SUMO和"领域本体知识"两个单元组成.都可以用中、英词形或概念查询,并以树状结构呈现各概念之间的关系.提供的信息包括以词形查询所属概念、概念的定义与公理、词汇与概念的关系以及相连接的WordNet中所有的信息,其中的概念信息已经翻译为中文.
索引窗口便于用户以字母、字首字尾、词类、来源、频率、领域、概念以及综合(来源、词类、频率)为限制条件,做进一步的信息查询.系统将列出符合条件的词汇列表,用户可以再进一步查询它们在对应的SUMO、WordNet以及在各种资源中的分布情况.
3.汉英双语词汇知识库HowNet
知网(HowNet)是中科院计算机语言信息工程研究中心董振东先生开发的,它是一个面向计算机的、以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库.可以看作是一种汉语词汇本体知识库.它的哲学根本点是 :一切事物(物质的和精神的)都在特定的时间和空间内不停地运动和变化.它们通常是从一种状态变化到另一种状态,并由事物的属性值的改变来体现.拿人来说,生老病死是人的一生的主要状态.某个人的年龄(属性)一年比一年大{属性值},头发的颜色(属性)逐渐变为灰白{属性值},他的性格(精神)变得日益成熟{属性值}.据此,知网运算和描述的基本单位是 :万物(包括物质的和精神的两类)、部件、属性、时间、空间、属性值以及事件.知网系统包括的数据文件和程序有 :(1)中英双语知识词典 ;(2)知网管理工具 ;(3)知网说明文件,包括动态角色与属性、词类表、同义与反义以及对义组的形成、事件关系和角色转换、标识符号及其说明等.
HowNet描述了24 089个概念,包含中文词语81 062个、英文词语76 526个.知网通过1 500多个义原(semantic primitives)的组合来描述概念之间的关系以及属性与属性之间的关系.知识词典是知网系统的基础文件,在该文件中每一个记录对应一个词语(包括词语的概念及其描述),包含五项内容,分别是编号、词语、词性、词语例子以及概念定义.知识词典是以词语及其概念为基础的,而概念的确定依赖于义原.义原是最基本的、不易于再分割的意义的最小单位.知网通过对大约6 000个汉字的考察和分析,采用自下而上的归纳法提取了一个义原标注集,在利用标注集建设知网系统的过程中,又不断检验和调整该标注集.比如,可以下面的三个汉字为例 :
治 :医治 管理 处罚
处 :处在 处罚 处理
理 :处理 整理 理睬
从上面所列举的3个汉字的义项,我们可以得到9个义原.但是,其中有两对是重复的,应该合并.这样,我们就得到了7个义原.通过对得到的这些义原进行合并和提取,就可以得到一个义原的标准集,并用它们去标注中文的概念.由于知网着力表现的是概念之间的共性和差异,利用义原标注得到的概念形成的知识系统是一个网状的结构,而不是一个树形结构.在这个网状结构中,概念之间的关系主要体现在每个记录的概念定义项(DEF项)中.知网概念间的关系有上下义、同义、反义、对义、部件-整体、属性-宿主、材料-成品、施事/经验者/关系主体-事件、受事/内容/领属物等-事件关系、工具-事件、场所-事件、时间-事件、值-属性、实体-值、事件-角色及相关关系等16种关系.
在知网的系统中,意义的计算(即语义推理)主要是在概念定义项的基础上对词语相似度和相关性进行计算.计算的基础是 :对概念进行基于义原及其关系的孤立的、静止的描述,并激活概念之间动态的、相互的关联关系.比如,"买"这一事件将激活"有";"患病"这一事件可能激活"医治".又如 :"买"的施事将转化为"有"的"关系主体";"患病"的经验者将转化为"医治"的"受事".通过这样的概念关系,可以揭示词汇之间在意义上的推演关系.下面是对于"患儿"和"儿科医生"的描述 :
"患儿":
DEF={human| 人 :domain={medical| 医 },modifier={child| 少 儿 },{SufferFrom| 罹 患 :experiencer={~}},{doctor|医治 :patient
"儿科医生":
DEF={human|人 :HostOf={Occupation|职位},domain={medical|医},{doctor|医治 :agent={~},patient={human|人 :modifier={child|少儿}}}}
通过对这两个词项概念定义项的比较,可以计算出它们的语义相似度.
五、词汇本体知识对于信息检索的作用
上文介绍了几种本体知识和词汇本体知识体系的结构、内容和建置方式,下面说明词汇知识和本体知识在信息检索中的作用.
1.词汇知识库在搜索引擎中的作用
目前的信息检索,主要是以搜索引擎为代表的基于关键词的搜索.在这种搜索系统中,用户用一个词或者短语来直接表达信息需求,希望所搜索到的文档中含有该词或该短语.如果用户提交的是一个查询短语,那么系统首先要对它进行分词处理,把它分成一个词的序列,并且删除那些没有查询意义或者几乎在每篇文档中都会出现的词②,形成一个查询词表.然后,用这个词表跟系统内核中已经预先处理好的文档进行匹配,系统根据匹配的程度输出查询结果.在这种后台处理过程中,语义词典起到非常关键的作用.根据李晓明等[8]的说法,词典就是搜索引擎系统内核和外围之间的一座桥梁,它所起的作用如图2所示 :

在一个搜索引擎系统中,外围应用通常是跟系统的输入和输出打交道的,它们面临的数据差别很大.如果让核心直接处理这些形态各异的数据,就会导致系统核心代码的急剧膨胀,系统运行效率迅速降低.而词典可以将各种数据以统一的整型编码的形式交给系统内核,使得系统内核的处理简单化,从而保证系统的运行效率.
2.Web环境下的搜索系统需要本体知识的支持
众所周知,现在的信息搜索系统是在Web环境下运行的.Web的特点是信息量大,来源复杂多样,这些不同来源的数据存在语义异构的问题.造成Web语义异构的原因是 :不同的信息源用多种术语来表示同一概念,而同一术语在不同的信息源中表示不同的含义.比如,在XML中,可以用"Author"来表示作者,也可以用"Creator"或"Writer"来表示作者.如果某个医院和大学的Web页面上都有"Doctor"这一词语,在没有其他属性特征描述的情况下,将很难判别Doctor表示的是医生还是博士.要解决上述两个问题,就需要引入本体知识.
上文已经指出,本体知识是对于共享概念的明确而规范的形式化说明.其中,"共享"说明本体知识体现的是相关人员共同认可的知识,它确定的是相关领域中公认的概念集 ;并且,对其所刻画的概念有严格的定义,对概念之间的关系有明确的说明.对于一般的语义词典来说,因为它们跟词项(item)直接关联,所以通常是处在词汇的层次,而本体知识表示的是人脑中的概念,对应于人脑中的百科知识,处在概念的层次.因为概念跟词项并不是一种一一对应的关系,所以在本体知识的建构过程中,一方面需要利用词汇知识(因为概念要通过词汇来表达),另一方面也需要注意词项与概念之间的区别.因此,在上一节中,我们特意介绍在已有的语义知识库中,它们是如何处理词汇与概念之间的关系的.
3.基于本体知识的信息检索上文说过,目前搜索引擎所用的主流技术是基于关键词匹配,这已经不能满足用户在语义上和知识上的需求.于是,基于语义和理解的检索技术被提到议事日程上来了.由于本体知识具有良好的概念层次结构和对于逻辑推理的支持,因而在信息检索,特别是基于语义和知识的检索中,可以发挥重要的作用.
基于本体知识的信息检索①的步骤可以总结如下 :
(1)在领域专家的帮助下,建立相关领域的本体知识.
(2)收集信息源中的数据,参照已经建立起来的本体知识,把收集来的数据按照规定的格式存储在元数据库(关系数据库、知识库等)中.
(3)对用户检索界面获取的查询请求,查询转换器按照本体知识,把查询请求转换成规定的格式 ;并且,在本体知识的帮助下,从元数据库中匹配出符合条件的数据集合.
(4)对检索的结果进行定制处理,然后返回给用户.
我们认为,对于上面的第3步,如果有了搜索意图的自动分析,那么就可以增加一个工作模块 :查询意图的展开和用户确认.因为,在web环境下的搜索过程中,用户输入的检索词常常存在歧义,这种歧义不仅包括语义歧义,更重要的是检索意图上的歧义.比如,用户输入"购物"这样一个词.虽然"购物"作为一种活动,它本身在语义上是没有歧义的,但是它却存在检索意图上的歧义 :用户可能想在某个购物网站上买东西,也可能是想在网站上查询某一商场的购物信息.
而前者属于事务型的检索,后者属于信息型的检索.对于我们来说,在建构本体知识的时候,就不仅要反映某个词项在语义上的特征,也要反映用户的搜索意图(词项的交际功能特征),特别是事务性的搜索意图.
如果检索系统不需要太强的推理能力,那么本体知识可以用概念图的形式表示并且存储,数据可以保存在一般的关系数据库中,采用图匹配的技术来完成信息检索.如果检索系统需要比较强的推理能力,那么本体知识需要用一种描述语言(如Loom、Ontolingua等)来表示,数据保存在知识库中,利用描述语言的逻辑推理能力来完成信息检索.因为本体知识能够通过概念之间的关系来表达概念语义的能力,所以能够提高检索的查全率和查准率.
4.服务于网络搜索的本体知识的建构
根据网络搜索的特点,参考上述几个词汇本体知识库的建构模式,我们认为服务于网络搜索的本体知识的建构,可以分以下几个步骤来进行:
第一,先确定一个服务于通用的搜索引擎的词项表,并将词项整合到一个层级系统之中.这一步骤可以借鉴SUMO和WordNet的建构方式.首先收集搜索引擎服务网站(如百度、Google)及一些导航性的网站(如新浪、搜狐)等已经存在的分类体系,然后对收集到的分类体系按照通用的系统进行整理,按照词项和概念一一对应的原则将这些分类体系整合到一个层级系统之中.如果在同一节点上存在多个词项,则选定一个优先/权威词(preferred word)作为索引词,其他非优先词项(non-preferred word)与优先词项形成同义词集.
第二,对已经形成的分类系统进行核查,可以借鉴从WordNet到SUMO的映射方式.分析用户的搜索日志,将某一时间跨度内用户日志中②所涉及的词语映射到已经形成的分类体系之中,看分类体系所形成的概念空间能否覆盖所有的词语.如果存在缺口,则需要用词项去填补.另外,看分类体系所提供的术语的抽象程度是否合适.如果不合适则根据核查的结果,对分类系统进行调整.
第三,对词项进行定义,借鉴HowNet对于词项释义的方式.除了对系统中已经存在的词项进行概念上的描述外,还需利用搜索日志的分析结果对词项的查询意图进行描述.如某一种商品应分别对应于信息型①和事务型两种意图,而对于机构名称,则一般有信息型和导航型两种意图.
第四,在通用的搜索用本体知识基础上,建立服务于具体目的的领域性本体知识.例如,我们可以参考购物网站,建立服务于电子购物的本体知识.
六、词汇本体知识研究的理论意义和应用价值
词汇本体知识的研究,涉及哲学上的本体论、语言学上的词汇语义学、心理学上的概念空间和概念的心理表征、计算机科学和人工智能上的知识表示和数据结构等方面.把这些相关领域的有关理论和方法整合起来,对汉语中跟搜索有关的查询词语进行本体概念分析,进而建立一个汉语词汇本体知识体系,这对于开拓汉语词汇语义学的研究范围,更新词汇语义学的研究方法,具有重要的理论意义和学术价值.这种研究成果可以为文本信息的组织、提取和整合提供跨学科的理论基础和概念化框架,可以直接应用到搜索引擎系统中,帮助其检索系统更快捷、更精准地返回符合用户查询意图的文档序列,这对于中文信息处理技术和中文信息技术产业都具有重要的应用价值和实践意义.因为,本体知识对于搜索引擎的工作原理由基于关键词匹配技术向基于语义的内容匹配技术转变,从而提高搜索的效率和精度,具有重要的提供基础资源的作用.
我们相信,词汇本体知识的研究结果,将为智能检索和语义搜索提供可靠的语言学知识和资源支持,同时也会为词汇语义学和话语交际理论的研究提供新的研究角度并开拓新的研究领域.
并且,这种由实际应用驱动的"词汇-语义-概念"研究,对于拓展词汇语义学的研究范围、更新语义表示的理论和方法、发展新的面向人机交互的话语交际理论,都具有直接的推动作用.还可以为语言学研究人员提供一些通向当代语言信息处理技术的路径,为汉语词汇学的研究注入面向工程应用的活力.
参考文献
[1]Neches R,Fikes R E,Gruber T R,et al. Enabling technology for knowledge sharing[J]. AI Magazine,1991,(3).
[2]Gruber T R. A translation approach to portable ontology specifications[J]. Knowledge Acquisition,1993,(5).
[3]Borst W N. Construction of engineering ontologies for knowledge sharing and reuse[D]. Enschede :Twente,1997.
[4]Studer R,Benjamings V R,Fensel D. Knowledge engineering,principles and methods[J]. Data and KnowledgeEngineering,1998,(1-2).
[5]Fellbaum C. WordNet :an electronic lexical database[M]. Cambridge,Massachusetts :MIT Press,1998.
[6]于江生,俞士汶.中文概念词典的结构[J].中文信息学报,2002,(4).
[7]Niles I,Pease A. Linking lexicons and ontologies :mapping wordnet to the suggested upper merged ontology[C].
Proceedings of the IEEE International Conference on Information and Knowledge Engineering. Las Vegas,Nevada,June23-26,2003.
[8]李晓明,闫宏飞,王继民.搜索引擎 :原理、技术和系统[M].北京 :科技出版社,2004.

腾讯公司推出了一款非常方便的免费应用程序,这是通讯服务专门提供给智能手机的,它支持跨越通信运营商与操作系统平台通过手机发送信息或者图片,还可以进行视频对话和实时对话。互联网现在发展越演越烈,作为时代的弄潮儿,微信俨然变成移动互联网时代的新...
随着计算机技术的飞速发展,图书馆馆藏资源也逐步朝着数字化方向发展。高校图书馆信息检索系统已逐步从手工检索方式向计算机检索方式转变,即全校师生可通过在数字图书馆信息检索系统中输入关键词,从图书馆馆藏资源中检索符合师生要求的有用信息资源,该系...
信息检索课的教学目的是培养高校学生具有较强的信息意识和信息素养,提高学生的自学能力,使他们能够自主获取除教科书之外更加丰富的知识。论文写作是大学期间每个大学生都会遇到的问题,也是学生们继续深造时必须具备的基本能力之一。从一定程度上来说,论...

本文主要介绍渔业、水产学科常用的电子文献资源及其检索方法, 旨在为渔业水产科研工作者提供一定的帮助。...
数据库作为计算机系统的核心构成,其在数据资料调配过程中发挥重要作用,为用户检索文献资料提供了许多实用性功能。因而,用户需掌握计算机数据库检索系统的结构分布情况,实际操作按照标准化流程执行,确保数据检索与运行的稳定性。1数据库应用功能数据...
信息检索课是一门实践性比较强的课程,该课程对于培养学生利用信息的能力有着重要的作用[1].但是随着计算机技术和网络的发展,现在信息资源的检索方式发生了巨大变化。为适应新环境下信息检索的需要,解决好信息检索课教学过程中出现的各种问题,笔者...

进入21世纪, 飞速发展的计算机网络技术革命影响着社会生活的各个领域, 情报信息工作也不例外, 随着数字化图书馆建设步伐的加快, 馆藏资源中数字资源所占的比例不断加大。...

随着科学技术的迅速发展, 农业科研领域的学科分类越来越多、越细, 研究领域也在不断延伸, 与之相应的农业信息资源也日益剧增。...
自1984年教育部印发《关于在高等学校开设文献检索与利用课的意见的通知》文件以来,高校都陆续开设了文献检索课。通过该课程的学习要求学生掌握网络信息检索的方法与技巧,能通过多种途径,迅速、准确地检索到所需的信息;同时,对促进学生不断地...
一、大学生自学能力自学能力是一种获取新信息、掌握新本领的综合能力,包括熟练使用各种工具书、查找文献资料和独立阅读能力等,也包括通过观察、实验、调查、参观和访问等实践活动去获取新知识的能力。大学生的智能培养主要是指自学能力、思维能力、表达能...