搜索引擎论文


1 概述
搜索引擎完成的主要功能是关键词的匹配及网络上节点的遍历查找,而本文针对人脸识别的图片搜索引擎同样利用特征匹配实现以人脸找相似人脸的搜索引擎。本文对人脸识别算法的分析主要从主成分分析法(PCA)入手,对其中的缺陷进行改进并应用于人脸图片搜索引擎的实现中。在主成分分析法中利用降维的思想提取主要特征,经过线性变换及奇异值分解得到特征向量从而得到特征脸。在搜索引擎的实现中主要利用的是在网络上节点的遍历以找到匹配信息并显示的技术。
2 人脸识别算法的分析
人脸识别算法的重点在于对于图片的特征提取和分析,一张图片的分辨率决定了图片划分的精度,为了提取有效特征,比如眼、口、鼻,可以将整张图像利用横纵轴划分,利用多幅图片,提取特征形成特征向量,表征标准人脸的组成。本次使用ORL人脸数据库作为样本进行PCA算法的验证及分析。
2.1 基于PCA人脸识别算法的分析
PCA(主成分分析)和LDA(线性鉴别分析)是两种降维方法,经过基本的测试和分析,PCA算法对于图片识别的正确性很高,对于人脸表情和轻微颤抖也有很好的健壮性(本文的测试实验建立在ORL人脸库上)。
PCA方法由Turk和Pentlad提出,它是基于Karhunen-Loeve变换(即K-L变换),主要用于建模方法中常用的数据降维,由于一幅图像由像素组成,基于像素在行列方向上的划分形成矩阵或看成一个矢量,构成原始的图像空间,因此PCA算法同样也应用于人脸识别的领域--PCA算法在处理人脸等图像识别问题时,遵循如下过程:将图像矩阵转化为图像向量,对原始图像向量进行线性分析标准化后得到标准化矩阵根据方差确定影响最大的向量即为第一主成分类似前面过程得到第二主成分以此类推。完整的人脸识别的过程包括:读入人脸库;形成特征脸(即特征向量)子空间,对图像进行降维获取特征值,把两组图像投影到由K-L变换得到的子空间上,利用对图像的这种投影间的某种度量来确定图像间的相似度;选择一定的距离函数进行识别。提取主要的特征向量进行图像重建,根据图像重建结果得出相似程度与提取原始图像向量的关系。
2.2 对于不同条件对特征提取的影响
2.2.1 依据图像重建,得出利用特征向量的多少及原始图片的成像清晰度(包括角度、光线、倾斜程度)都对重建结果有很大影响。这是人脸识别的关键性问题,本文通过图片预处理来解决一部分问题,比原先未处理的图片重建效果好了很多,拟合性也高了很多。
2.2.2 对于PCA算法,要求训练集必须大于测试集。即要搜索的人脸图片必须在数据库中存在至少一张图片才能得到好的重建效果,否则不能实现。PCA算法可以对训练样本内的图片重建效果很好。
如图2,表示使用特征向量进行人脸重建得出的一组人脸图像。
第一、二组表示训练样本中的重建结果,第三组表示训练样本外的重建结果,从中可以看出,训练样本内的效果在特征向量大于等于100时基本得到了很好的重建效果,基本还原原始图片,而训练样本外重建的效果只能得到关键部位例如五官的大致位置和形状,重建效果不是特别好。
2.3 基于影响因素对PCA算法的改进
通过增加训练,集中不同人脸图片的数量,增加关键部位例如五官的丰富性,使获得的平均脸更具有广泛性和代表性,对于不同图片的外在差异性通过图片预处理(例如:灰度处理)从而产生颜色、纹理差异性较小的图片,再使用PCA算法进行降维得到的特征向量来重建的人脸图片具有更好的拟合性,如此得到的特征向量相比没有做预处理图片有较好的重建效果。
3 Ubuntu下搜索引擎的搭建
3.1 准备工作
为了提高安全性,由于Ubuntu系统下可选择用户权限使得人脸库的可靠性更高,本文选择在Ubuntu下完成人脸搜索引擎的实现。在Ubuntu系统下通过命令行下载安装CMake、OpenCV,同时利用CMake对OpenCV进行编译;配置php的imagick-3.2.扩展和imagemagick扩展为图片处理做准备,再配置好face_detect即php使用OpenCV的扩展函数;由于使用PHP作为开发环境,下载安装LAMP(Linux、Apache、Mysql和PHP),将搭建搜索引擎的环境配置好。
3.2 前台设计
搜索引擎主要以网页的形式与用户交互,是与用户交互的接口的主要界面,主要有以下功能:实现人脸图片的检索和匹配功能(button、input元素),同时可以从本地上传图片(可预览)至网页客户端(input元素),使得本地图片与系统中相似图片得以匹配并显示给用户。设计框架搭建前台界面,利用html、css与JS语言实现界面设计,html和css完成界面风格设计,JS实现动态页面效果(例如预览图片的动态显示等),布局主要采用分栏形式,整体风格简约便于用户使用。
3.3 后台实现
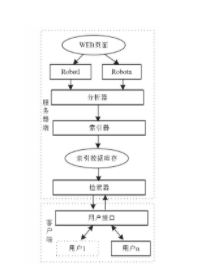
基于代码的后台主要使用php语言实现具体功能,包括:实现人脸图片的检索和匹配功能,同时可以从本地上传图片至网页客户端且用户可以预览,通过用户点击搜索按钮使得本地图片与网络中相似图片得以匹配并将匹配图片显示给用户。通过spider技术实现网络上html文档的遍历,可采用广度优先算法--在访问一个网络节点后一次访问相邻的网络节点直到将网络中所有节点全部遍历。对于图片匹配与传统的搜索引擎的文字匹配是类似的,利用PCA算法将图片抽象成特征向量并与www中的html文档中为图片格式的元素进行匹配,通过建立索引的方式实现人脸图片的查找与匹配,从而显示给用户。
4 结语
本文主要探讨如何用php语言来实现搜索引擎中人脸图片识别匹配的功能。由于在Ubuntu系统中可以保障人脸信息的安全性,本文的搜索引擎实现在Ubuntu系统下完成。该搜索引擎中对于人脸识别部分使用了稳定可靠的PCA算法,搜索引擎本身采用网络爬虫进行索引匹配,虽然基础,但给用户检索人脸图片带来一定的方便,实现了图片搜索、匹配等一些常用的功能,但是系统还可以进一步完善。由于现在信息大爆炸,在各个领域中对于信息的私有性有着很大的需求,因此,本次研究与实践还有待进一步完善:(1)检索图片不仅仅局限于人脸图片,而扩展为包括风景、物品等图片的检索;(2)优化PCA算法,使用基于PCA算法的优化算法例如Eigenface(其方法基于本文研究的PCA算法),可能会得到更好的结果;(3)不仅仅局限在搜索引擎,可以扩展到手机APP,使得人脸识别得到更好的应用。
参考文献
[1] 宇雪垠,曹拓荒,陈本盛。基于特征脸的人脸识别及实现[J].河北工业科技,2009,9(5)。
[2] 张晓璐。基于PCA的人脸识别技术的研究[J].辽宁科技学院学报,2014,(12)。

0引言信息检索系统主要为互联网用户提供对资源的检索服务,用户通过输入自己想要寻找的资源信息(诸如资源的部分名称,资源内容中相关关键词等),信息检索系统根据用户提供的检索需求进行资源匹配和资源定位,并按照一定的顺序将匹配的资源反馈给用户。搜...

搜索引擎经历近30年的发展,目前在使用的有几种类型,如全文搜索引擎、分类目录搜索引擎、多元搜索引擎、集成搜索引擎等。但这些都是网络上的公用商业搜索引擎,它们往往不能满足企业的需要。...
在计算机技术以及网络技术特别是移动通信技术不断发展的背景下给智能手机带来了极大的发展空间。目前性能过剩已经成为了当前智能手机的普遍问题之一,硬件功能过于强大的背后反而是软件不能跟上步伐,这也就导致了用户的体验性出现了一定程度的下降。在人机...

本文在原有的中文抄袭检测源检测算法的基础上, 通过实验分析比较各种分词工具和词性标注工具的优缺点, 选取针对高模糊抄袭以及网络抄袭的行之有效的关键词提取方法。CNKI虽然能检测出大部分的中文抄袭, 但面对基于web抄袭的现象显得力不从心。...
安徽农业大学校园网始建于2000年,现有信息网点一万多个,学生用户二万多人,FTP服务器是校园网主要的应用服务之一。在FTP服务器上目前保存着多种共享软件、技术资料和多媒体数据等几十个TB的文件资源。FTP服务器建有若干目录,文件与目录结构存在多...
首先Web信息检索挖掘技术做了简要概念,其次对基于Web挖掘的网络搜索引擎技术的应用进行了分析,提出了一种给予Web挖掘的个性化搜索引擎,并对各系统模块的功能及实现方式进行研究,分析结果表明,此种系统具有很强的检索灵活性,而且还能实现个性化查询结果...
【摘要】作为重要专利信息源,德温特数据库可以为研究者提供丰富的资源,但其数据导出格式局限性较大且只包含摘要等信息,不利于进一步深入分析。设计并实现基于多Agent平台的分布式德温特专利信息抽取系统,将专利信息导入到本地数据库中;并针...
1discuz的文档服务器(archive)是否要开启关于archive是否需要开启要根据我们的论坛要做内容页的伪静态或是动态来决定。如果内容页为伪静态,那么archive就完全没必要开启,假如开启则会造成更多的麻烦与不稳定(主要是重复页的出现);如果主机不...

近年来,几大搜索引擎公司为进一步方便学术用户获取学术资源,纷纷在其原有搜索引擎的基础上推出了学术搜索引擎。学术搜索引擎通过科学组织、管理和维护网络中的学术信息,使用户通过一个检索入口快速获取网络学术信息。...
引言随着信息化的不断深入,互联网飞速发展,传统的集中式搜索引擎难以满足人们对于快速检索信息的需求。云计算技术的发展给搜索引擎带来了新的机遇。针对中小型机构资金与能力不足,难以实现高效搜索,本文以局域网分布式处理为立足点,首先介绍了云计算平...