【摘要】作为重要专利信息源,德温特数据库可以为研究者提供丰富的资源,但其数据导出格式局限性较大且只包含摘要等信息,不利于进一步深入分析。设计并实现基于多 Agent 平台的分布式德温特专利信息抽取系统,将专利信息导入到本地数据库中; 并针对 USPTO 库提供专利详细信息自动获取。该系统抽取效率较高,为专利研究提供较好的信息获取途径。
【关键词】专利信息抽取 负载均衡。
1 引 言
1.1 需求分析。
德温特创新索引(Derwent Innovation Index,DII)[1]是专利研究领域重要的数据来源,在课题组研究中,发现并总结了专利数据获取过程中的问题如下: 虽然德温特专利数据库提供多种检索方式,但检索结果导出的形式却比较有限(例如 HTML 或纯文本格式) ,不利于数据分析阶段的处理; 从所包含内容的角度,德温特专利数据库仅为摘要库,不包含专利文档原文; 专利分析与研究领域大数据的特征日益显着,信息获取的速度和效率需要提升。
针对上述实际问题和现有专利信息获取软件的功能,确定系统需求如下:
(1) 基于多 Agent(Mutil - Agent) 平台,构建德温特专利信息抽取系统。以用户下载到本地的专利 HTML 文档作为系统输入,抽取文档中的信息并存储到本地数据库中;
(2) 主要面向 USPTO[2]专利数据库提供专利详细信息的抽取,通过多 Agent 系统的消息机制实现上述过程的协同;
(3) 针对大数据处理效率的问题,设计并构建分布式系统。其中,本地服务器用于德温特专利信息抽取,异地服务器负载的计算和任务分发,部署在异地的服务器用于任务接收、负载情况反馈和面向 USPTO 专利数据库的专利详细信息获取。
1.2 国内外研究现状。
在信息抽取领域中多 Agent 系统的研究方面,Bedi等[3]基于多 Agent 系统的体系结构,提出将定制 Web 搜索与信息线索相整合,设计并实现了网页信息检索与抽取系统。Pavlin 等[4]提出了支持构建模块化的贝叶斯融合系统的设计策略和方法论,面向大量异构的含噪声信息,使用多 Agent 系统完成分布式的信息抽取和贝叶斯信息融合。Jumadinova 等[5]研究了多 Agent 系统用户获取、分析相关数据用以对市场进行预测。国内方面,张俊等[6]将多 Agent 系统应用于数据处理(数据抽取、转换、加载) 领域,基于 Agent 之间的协作机制进行实时ETL(Extract - Transform - Load) ,提高了数据加载和更新的效率; 翟东升等[7]基于多 Agent 系统,使用 XML 模板,设计并实现了 USPTO 专利抽取系统。综上,多 Agent系统具有模块化程度高、结构开放程度高、并行性等优势,适合用于解决信息抽取领域并行处理多目标的任务,且当前的应用范围较为广泛。随着大数据特征的日益凸显,将多 Agent 系统分布式计算与抽取规则引擎相结合完成信息抽取可以大大提升专利信息获取的效率和灵活性,满足迅速增长的数据采集需求。
在分布式系统的负载均衡机制研究方面,Kunz[8]认为,采用简单因子进行负载均衡就可以使系统效率显着提升,并且不同因子对系统效率的影响具有较大差异; 针对服务器计算能力不同但各通信参数一致的情况,Bahi[9]提出异步负载均衡迭代算法并验证了算法的有效性。国内方面,马雪梅[10]认为,对一个分布式系统而言,负载均衡的实现是系统整体效率提升的关键,并提出了负载均衡指标体系建立的方法论; 王春娟[11]提出了一种针对 Web 集群的负载均衡算法。综上,当前的文献表明,存在一些具有普适性的指标,例如网络速度、内存空闲率和 CPU 使用率等。并且,分布式系统的负载均衡指标选择应考虑简单性以及低耦合性。上述负载均衡调度算法的应用对象是一般分布式系统(如分布式网络服务器等) ,但基于 Agent 系统的专利信息抽取工作具有其自身特点(如 Agent 的协作情况等) ,因此在研究中需要结合实际情况对负载均衡机制进行重新设计和应用。另外,基于 Agent 的分布式系统调度特性具有与人类感官直觉相类似的特点,有利于负载均衡机制的设计与效率提升。
2 系统流程与架构
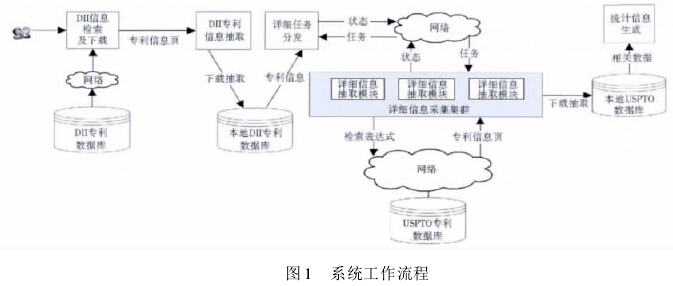
明确系统开发需求后,构建系统工作流程与系统架构。系统工作流程如图 1 所示:
(1) 用户在德温特专利数据库中检索所需专利并下载 HTML 格式的专利信息页面作为系统输入;
(2) 进行专利抽取并将信息存储在本地数据库,向用户反馈专利信息,并由用户选择需要获取详细信息的专利;
(3) 将详细信息抽取任务分发给部署在异地的服务器,即详细信息采集集群,任务分发的策略须考虑负载均衡;
(4) 各详细信息抽取模块构造在 USPTO 专利数据库中的原始专利信息页面的 URL,并将详细的专利信息下载至本地数据库,提供相关统计信息作为系统输出。
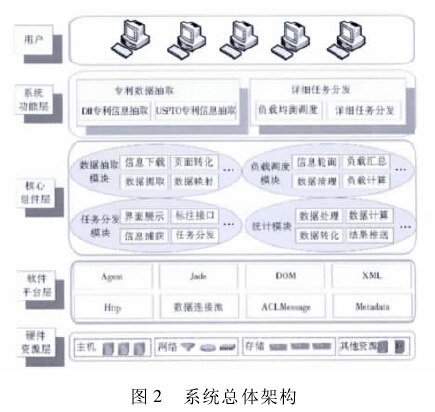
系统总体架构如图 2 所示:
由底层向上,分别为硬件资源层、软件平台层、核心组件层和系统功能层。硬件资源即为系统硬件基础,以它为基础搭建软件平台层,即系统的若干相关技术和开发平台; 核心组件层是将系统功能与关键技术相关联的核心中间件,根据系统的应用实际,将该部分抽象为 4 个模块,便于未来增加其他功能或功能升级;系统功能层为与核心组件层的模块相对应的工具包,为用户提供相关服务。
3 系统设计
系统划分为如下功能模块: DII 专利信息抽取模块、任务分发模块和 USPTO 专利信息抽取模块,如表1 所示:
上述功能模块中,本文主要研究内容是模块 1 和模块 2,模块 3 部分重用课题组的研究成果[12],对相关内容进行改写。模块开发策略方面,使用多 Agent.
3.1 DII 专利信息抽取模块设计。
模块输入为用户下载的德温特专利信息文档,格式为 HTML! 基于模板对文档中的专利信息进行抽取,并将抽取结果存入本地数据库。
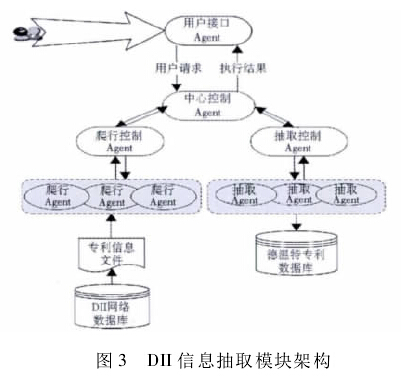
为实现该模块功能设计如下 Agent:
①用户接口 Agent,用于用户与系统间的信息交互,提供GUI,便于用户对系统进行操作。
②中心控制 Agent,是本模块的控制核心,它将用户的操作指令提交至相关二级调度 Agent! 并在任务完成后,向下一通信节点转发相关信息。
③爬行控制 Agent,用于接收任务消息后及时进行任务分发,综合调度爬行 Agent,使其完成页面信息爬取任务,并上报最终结果。
④抽取控制 Agent,用于依据抽取 Agent 的实时情况分配抽取任务。
⑤爬行 Agent,为该系统功能模块的实际任务完成者之一。用于解析流文件形式的专利信息 HTML 页面,并转换为StringBuffer 形式存储在内存中以便于后期的信息抽取。
⑥抽取 Agent,为该系统功能模块的实际任务完成者之一。用于预处理内存中的专利信息,将其格式转化为标注的XML 文件,然后抽取其中信息映射到本地数据库。
该模块整体架构如图 3 所示:
(1) 用户接口 Agent.
用户接口 Agent 包括两个组成部分: 前台界面 GUI和后台控制 Agent 类。前台 GUI 用于实现用户交互,后台 Agent 用于传送用户请求,即通过 Jade 平台的黄页服务与中心控制 Agent 进行通信,转发用户请求至中心控制 Agent,并由其进行调度以实现系统功能。
(2) 中心控制 Agent.
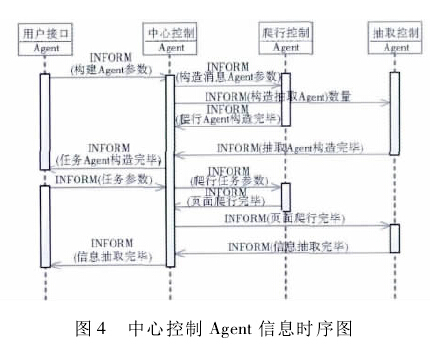
中心控制 Agent 是系统的一级调度模块,也是本模块控制的核心。其主要任务为用户接口 Agent 与二级调度 Agent 之间的通信。其信息时序图如图4 所示。
在接收到用户接口 Agent 发送的构建 Agent 任务后,中心控制 Agent 首先将消息内容进行切分。将构建参数中的信息分类,并按照其所需构造 Agent 的种类将消息打包,转发给爬行控制 Agent 及抽取控制Agent.当接收到 Agent 构造完成的消息后,中心控制Agent将其整合,并发送给用户接口 Agent,以示完成Agent的构造过程。当接收到用户接口 Agent 发送的抽取任务消息时,中心控制 Agent 对其进行解析,若任务参数路径正确,则向爬行控制 Agent 转发此消息,由其完成专利页面爬行任务。当接收到页面爬行任务完成的信息时,中心控制 Agent 向抽取控制 Agent 转发该消息,由其基于页面爬行的结果实现数据抽取任务。抽取任务完成后,抽取控制 Agent 发送信息抽取完毕的消息,中心控制 Agent 将其转发至用户接口 Agent,向用户反馈抽取任务完成。
(3) 爬行子模块。
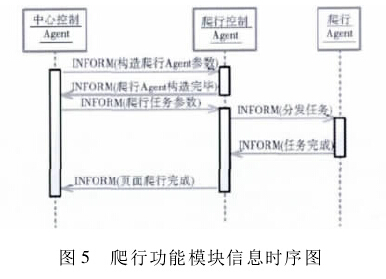
爬行子模块主要包含爬行控制 Agent 和爬行Agent两类。爬行控制 Agent,用于注册爬行 Agent,并调度其完成页面信息爬取; 爬行 Agent,用于接收相关专利信息爬取任务,并上报爬取结果。该子模块的基本信息流时序图如图 5 所示:
在接收到构造爬行 Agent 任务后,爬行控制 Agent将获取到相关构造参数,并将其传送至动态创建 Agent的方法中,以实现爬行 Agent 的构建。当接收到中心控制 Agent 发送的任务时,爬行控制 Agent 通过其 Cy-clicBehaviour 行为进行任务分发。当爬行 Agent 任务完成后,将状态修改为空闲并发送消息。最后,由爬行控制 Agent 向中心控制 Agent 发送页面爬行任务完成的消息。
(4) 抽取子模块。
抽取子模块包含抽取控制 Agent 和抽取 Agent.其中,抽取控制 Agent 主要用于接收消息并调度抽取Agent 完成对爬行 Agent 所爬取页面信息进行格式转换和面向本地数据库的数据映射。其调度过程与爬行子模块类似,这里不再赘述。
3.2 任务分发模块设计。
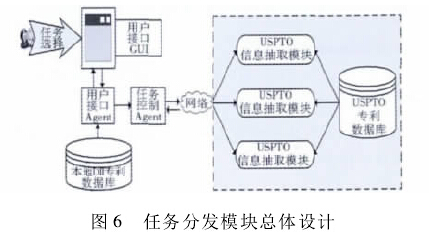
任务分发模块由用户接口 Agent 和任务控制Agent两部分构成。其中,用户接口 Agent 用于将抽取的德温特专利信息向用户展示,提供 GUI 供用户选择所需的专利详细内容,用户对相关专利做出选择后,向任务控制 Agent 传送该信息。任务控制 Agent 主要用于接收用户接口 Agent 发送的任务信息,并在自身任务池中存储待抽取详细信息的专利号。对部署在异地的服务器进行状态轮询,并计算其负载情况,依据此分发任务。该模块的总体设计如图 6 所示:
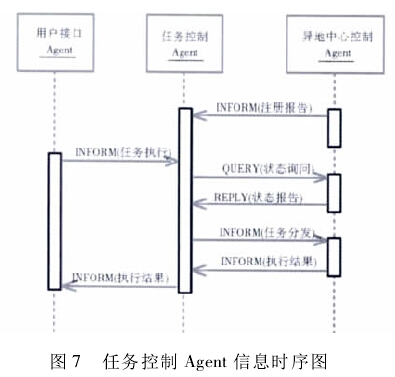
任务控制 Agent 是分布式系统负载情况的计算核心以及与异地服务器进行通信的核心。它与异地服务器之间的信息交互时序图如图 7 所示。
部署在异地的服务器在注册中心控制 Agent 时,会首先向任务控制 Agent 发送相关消息,以示自身注册已完成并可以接受任务。在接收到来自于用户接口Agent 的任务执行消息时,任务控制 Agent 从接收到的信息中抽取出相关任务数据并进行格式处理,然后将处理后的具体任务信息排入任务队列中。之后,对异地服务器状态进行轮询,异地服务器会及时反馈自身负载状态。接收到状态消息后,任务控制 Agent 将相应服务器的信息加入状态管道之中并计算全部异地服务器负载状况,依据此进行任务分配。异地服务器完成详细信息抽取任务后,返回抽取结果,由任务控制 Agent 转发至用户接口 Agent 实现抽取任务完成的反馈。
3.3 分布式多 Agent 系统通信设计。
(1) 任务控制 Agent 与异地服务器的通信机制。
异地通信使用 Agent 平台的 AMS(Agent Manage-ment System) 服务,这是一个负责管理 Agent 平台并提供用户信息数据库服务的管理 Agent.
其通信方式的步骤如下:
①定位 AMS 通信参数(主机名称、IP 地址、通信端口);
②使用 AMS 服务获取其所在容器;
③通过 AMS 服务的静态方法 Search,获取该容器中的Agent 列表;
④对列表进行遍历,搜索到需要通信的异地 Agent.
(2) 异地中心控制 Agent 的消息上报机制。
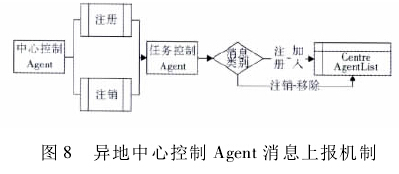
对 USPTO 专利抽取系统[12]的中心控制 Agent 实施相应改写。为满足当前系统要求,为其增加新的行为变量。异地中心控制 Agent 的消息上报机制如图8 所示:
注册之后,它将其 IP 地址和端口号等信息打包并发送至任务控制 Agent! 接收信息后,任务控制 Agent将该中心控制 Agent 的 Agent ID(AID) 及通信参数加入 CentreAgentList 列表中,表示该服务器已完成注册并可以执行任务。当异地中心控制 Agent 注销时,该Agent 向任务控制Agent上报注销消息,接收消息后,任务控制 Agent 根据 AID 查询 CentreAgentList 列表,移除该异地服务器的全部信息,表示该服务器已注销,不再执行详细信息抽取任务。
3.4 分布式多 Agent 系统的负载评估体系。
依据多 Agent 系统的特点,使用理论分析结合反复实验的研究方法,本文确定了如下系统负载均衡的评价指标。
(1) 空闲爬行 Agent 数量(LSa) .根据本系统设计的调度机制,当没有空闲的爬行 Agent 时,系统会将任务挂起,直到有爬行 Agent 执行完现有任务后,才能为其再次分发任务。因此,在进行负载计算时,空闲爬行Agent 数量是一个重要的指标。
(2) 空闲抽取 Agent 数量(LEa) .系统对于抽取Agent的调度机制与爬行 Agent 的调度机制相似,并且,其任务执行过程涉及若干步骤,较为复杂。因此,在进行负载计算时,空闲抽取 Agent 数量同样是一个重要的指标。
(3) 空闲引用抽取 Agent 数量(LRa) .引用抽取Agent同样是系统的任务级 Agent.在 USPTO 的页面中,将某一专利所引用的其他专利存放于深网页面中,需要设计引用抽取 Agent,用于动态构建深网页面的URL 地址,并将相关引用信息暂时存储于内存中,最终映射至本地数据库中。因此,也应将其作为负载均衡评价指标之一。
(4) 空闲内存大小(LFm) .基于专利研究领域大数据量的特征,系统往往需要处理大规模的专利抽取任务。因此,计算机的性能会较为显着地影响系统效率。
(5) 异地瞬时网速(LWs) .由于异地服务器需要在线检索并抽取相关专利详细信息,网络速度造成的延迟对系统效率影响较大。
上述 5 个指标均是独立有效的。其中,前三个指标之间存在多任务间的协作关系,但由于建立了基于调度 Agent 的任务缓冲机制,对于某一随机任务而言,三个指标仍旧是独立有效的。
负载均衡算法方面,主要参考王春娟[11]提出的动态反馈负载均衡算法的思想,并基于多 Agent 系统的调度与通信机制做出改进,将其自主反馈机制修改为轮询式的负载均衡算法,以有效降低系统的通信开销。
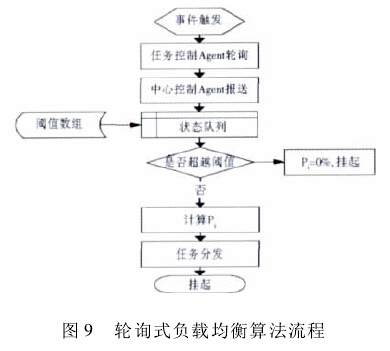
轮询式负载均衡算法流程如图 9 所示:
任务控制 Agent 异步轮询系统的负载情况,在特定情况下触发其轮询事件; 轮询事件被触发后,任务控制 Agent 向异地中心控制 Agent 问询 5 个负载均衡评价指标; 针对这些指标,任务控制 Agent 在设计时封装了它们的最低阈值,这些阈值通过反复实验得到。若某服务器存在低于阈值的指标数值,则将其挂起,且将空载量记为 0.
对于可以接受任务的服务器(即其未被挂起) ,系统对 5 个指标进行归一化处理,转化为 LSa',LEa',LRa',LFm',LWs'! 然后依据预先设定的各项权重值,使用如下公式计算服务器空载 Pi:
Pi=[α,β,γ,δ,ε]×[LSa',LEa',LRa',LFm',LWs']T
其中,指标权重为系统内置,经由反复试验调整至较好的运行状态。
最后依据 Pi值进行按比例的任务分发,即 Pi值越高,就被分配越多的详细抽取任务。
4 原型系统实现与分析
4.1 系统运行平台。
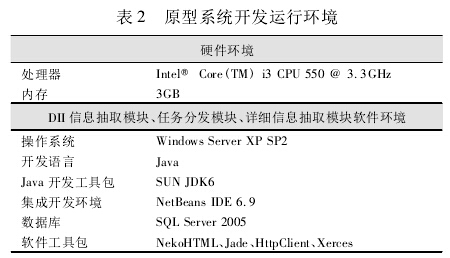
采用分布式的系统结构和多 Agent 设计模式,开发运行环境如表 2 所示。
4.2 实验与分析。
(1) DII 专利信息抽取。
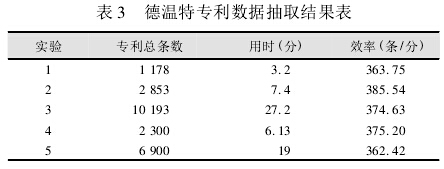
共计进行 5 次实验,检验 DII 专利信息抽取模块的有效性、抽准率和抽取效率。实验中将爬行 Agent和抽取 Agent 的数量设定为 20,实验结果如表 3 所示:
从表 3 数据可以看出,DII 专利信息抽取模块可以从本地的专利信息 HTML 格式文档中抽取相关信息,并存储在本地数据库中; 另外,该模块的数据处理效率较高,可以支持数据量较大的专利信息抽取。
(2) 任务分发与详细信息抽取。
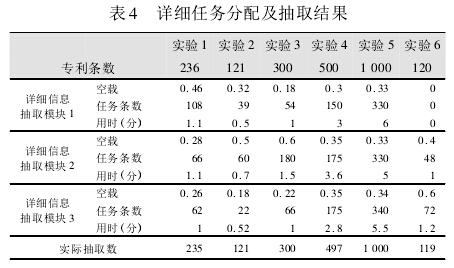
使用 DII 专利信息抽取实验获取专利信息,进行任务分发与详细信息抽取的实验,使用虚拟机模拟三个分布式系统的异地服务器,即详细信息抽取模块 1至模块 3.实验共进行 6 组,各组具有不同的专利条数,各详细信息抽取模块的空载率也通过预设指标值的变化做出改变以验证详细任务分发模块的运行情况,即是否实现了负载均衡。实验结果如表 4 所示:
从表 4 的实验数据可以看出:
①对于每个详细信息抽取模块,任务条数与其空载率成正比,且二者的增长或减少趋势大致相同。
②第 6 组实验中,详细信息抽取模块 1 的空载率为 0.这是因为系统预定义的空闲爬行 Agent 和空闲抽取 Agent 数量的下限阈值为 5,而实验中上述两类 Agent 的数量为 2 和3,所以该异地服务器处于挂起状态,不再接受任务。
③每组实验中,各模块的任务量分配不一,但用时大致相同。
上述三点能够说明该分布式多 Agent 系统的负载均衡评价体系的有效性。但由于整体网络环境以及服务器的运行情况在实验过程中不能保持恒定,从而导致在有些实验中任务完成时间的不稳定,这在系统运行中是可以接受的。
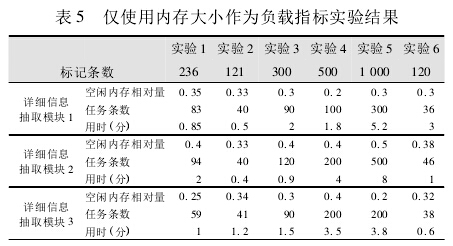
通过对比实验进一步验证系统负载均衡的有效性。由于目前尚无专门针对分布式多 Agent 信息抽取系统负载均衡算法的相关研究,因此这里采用 Kunz[8]提出的方法,以空闲内存大小这一简单指标的模型进行对比实验。实验结果如表 5 所示:
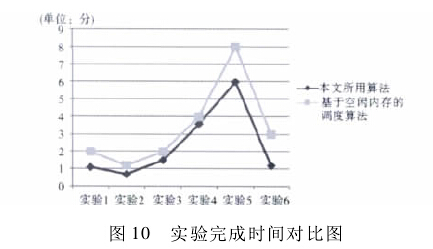
从表 5 实验数据可以看出,6 组实验中三个详细信息抽取模块完成任务的时间分布较为离散,其完成任务的最终用时较长,两种负载均衡算法实验的任务完成时间对比如图 10 所示:
其中,实验完成时间为由三个抽取模块共同完成专利信息抽取任务的时间,由于三个模块的工作是并行的,所以任务完成时间即为用时最长的详细信息抽取模块所用的时间。经分析认为,这是因为对比实验中,异地服务器的实际负载没有实现精确计算,即无法有效实现系统资源的优化配置,出现资源闲置的现象,从而导致系统效率不稳定。
通过对比实验,可以看出本文提出的负载均衡算法能够较为准确地反映基于多 Agent 平台的分布式专利信息抽取系统的负载情况,从而有效地使系统达到负载均衡。
5 结 语
本文设计并实现了分布式的德温特专利信息抽取系统,系统基于多 Agent 技术构建,以用户下载的德温特专利 HTML 文档作为系统输入,利用模板进行信息抽取并存储在本地数据库中; 针对德温特专利信息中仅包含摘要信息的局限性,面向 USPTO 专利数据库,提供用户可自主选择的专利详细信息自动获取功能。
实验证明,系统的信息抽取效率较高,且分布式多Agent系统的负载均衡计算方法和通信机制较为有效,可以提供高效、准确的专利信息获取服务。在未来的研究中,考虑面向更多的专利数据库提供详细信息抽取服务; 另外,设想为用户提供进一步的专利信息预处理,以及统计和分析等服务,扩充系统功能,更好地为专利研究做出有力支撑。
参考文献:
[1]Derwent Innovations Index[DB/OL].[2013 - 04 - 02].
[2]USPTO Patent Full - Text and Image Database[DB/OL].[2013 -04 - 02].
[3]Bedi P,Chawla S.Agent Based Information Retrieval System UsingInformation Scent[J].Journal of Artificial Intelligence,2010,3(4) : 220 -238.
[4]Pavlin G,de Oude P,Maris M,et al.A Multi - Agent SystemsApproach to Distributed Bayesian Information Fusion[J].Agent -Based Information Fusion,2010,11(3) : 267 - 282.
[5]Jumadinova J,Dasgupta P.A Multi - Agent System for Analyzingthe Effect of Information on Prediction Markets[J].InternationalJournal of Intelligent Systems,2011,26(5) : 383 - 409.
[6]张俊,陈宏刚。基于多 Agent 的实时 ETL 系统模型研究[J].信息技术,2010(2) : 71 - 73.(Zhang Jun,Chen Honggang.Re-search on Real - Time ETL System Model Based on Multi - Agent[J].Information Technology,2010(2) : 71 -73.)
[7]翟东升,杨洋。基于 XML 技术的 USPTO 专利抽取系统[J].北京工业大学学报,2011,37(4) : 628 - 633.(Zhai Dongsheng,Yang Yang.USPTO Patent Information Extraction System Based onXML[J].Journal of Beijing University of Technology,2011,37(4) : 628 -633.)
[8] Kunz T.The Influence of Different Workload Descriptions on aHeuristic Load Balancing Scheme[J].IEEE Transactions on Soft-ware Engineering,1991,17(7) : 725 - 730.
[9]Bahi J M.Dynamic Load Balancing and Efficient Load Estimatorsfor Asynchronous Iterative Algorithms[J].IEEE Transactions onParallel and Distributed Systems,2005,16(4) : 289 - 299.
[10]马雪梅。分布式系统中主机负载预测[D].长春: 吉林大学,2005.(Ma Xuemei.Loading Prediction of Host Computer in Dis-tributed System[D].Changchun: Jilin University,2005.)
[11]王春娟。Web 集群负载均衡算法的分析与研究[J].电脑知识与技术,2008,3(26) : 1623 - 1624.(Wang Chunjuan.Analysisand Research of Load Balancing Algorithm Based on Web ClusterSystem[J].Computer Knowledge and Technology,2008,3 (26 ) :1623 - 1624.)
[12]杨洋。基于多 Agent 系统的专利采集系统研究[D].北京: 北京工业大学,2010.(Yang Yang.Research on Patent InformationAcquisition System Based on Multi - Agent System[D].Beijing:Beijing University of Technology,2010.)