社会保障论文


一、引言
通过长期的反贫困战略的实施,我国绝对贫困人口从 2000 年的 9422 万人下降到 2010 年的 2688万人,贫困发生率从 2000 年的 10. 2% 下降到 2010 年的 2. 8%。贫困人口的贫困状况也发生了变化———从绝对贫困到相对贫困,从 “面上贫困”到 “点上贫困”; 贫困的内涵从传统的收入贫困逐渐演变为一个相当复杂的发展现象,以往的单纯依靠测量收入的贫困度量方法已经不能满足目前扶贫政策的需要。在这种背景下,从多维角度把握贫困的实质并进行多维贫困的具体度量,逐渐为国际学术界所认同并成为近年来国内外研究的焦点。目前国内外贫困研究较为流行的是从能力贫困的角度利用森 (Sen) 提出的多维贫困理论识别贫困对象。一些学者分别从社会、经济、教育、健康等角度定义贫困村识别的多维指标体系; 阿尔凯尔 (Alkire) 等人给出了基于贫困剥夺计数的综合贫困指数测算方法; 王小林等人运用该方法和 2006 年 “中国健康与营养调查”数据,对中国城市与农村家庭多维贫困进行了测算; 李佳璐在多维贫困测量理论框架下,沿用王小林以及阿尔凯尔的测算方法对 S 省 30 个国家扶贫开发工作重点县进行多维贫困测算,通过收入分组的方式,分析不同维度对不同收入组家庭的影响程度。但现有的贫困识别指标体系大多着眼于某个或某几个社会经济维度,且由于切入角度、数据源、研究区域不同,识别维度及指标不尽相同,更为重要的是目前国内外的研究仅仅关注了贫困人口本身,而对其贫困特征空间分布模式鲜有涉及。另外,以往的学者对于贫困的分析都是通过统计图表形式描述,而现实中贫困人口及其贫困特征在空间上的分布往往是不均匀分布,所以用统计指标表达贫困并不准确。相比统计图表,专题地图更易于对贫困地区公共基础设施建设的方向提供决策辅助,方便后续扶贫政策的实施。
本文以秦巴山区连片特困区扶贫重点县为例,构建瞄准人口的村级贫困识别技术体系,对多维贫困测算结果及贫困特征空间分布进行空间化处理和分析。以此识别真正的贫困人口和贫困特征分布区域,为各级政府科学决策和科学管理提供更加全面与翔实的基础数据和支持信息,引导贫困地区合理利用优势资源,保护生态环境,实现自我发展的良性循环。
二、研究区概况与数据源
内乡县为秦巴山区连片特困区国家扶贫重点县,位于河南省西南部,南阳盆地西缘。地形呈南北条状,总面积 2465 平方千米。全县共 16 个乡镇,289 个行政村和 8 个居民委员会,3840 个村民小组,153841 户农户,总人口 65 万人。其中,农村人口 45 万人,占总人口的 69. 7%。据 2010 年内乡县政府工作报告,2009 年内乡县人均生产总值为 14125 元,农民人均纯收入为 4906 元。
本研究所采用的数据包括研究区社会经济数据和基础地理数据。社会经济数据主要来自 2010 年该县统计年鉴及扶贫办贫困农户建档立卡调查数据,调查内容包含农户的家庭人员结构、身体健康状况、劳动力输出情况、人均纯收入、住房结构与面积、耕地面积、饮水来源、家庭资产等信息。调查范围涵盖内乡县 157 个行政村,29832 户家庭,村覆盖率达 54. 3%,户覆盖率达 19. 4%,其中,148户数据存在记录遗漏。基础地理数据包括研究区行政村村界数据以及内乡县居民点数据。本文在使用前对此进行了地理配准、数据查漏和剔除粗差等预处理。
三、研究方法
森把发展看做是扩展人们享有实质自由的一个过程,实质自由包括免受困苦 (诸如饥饿、营养不良、可避免疾病、过早死亡之类) 的基本可行为能力。人们的这些基本可行为能力被剥夺因而导致贫困,多维贫困测算的目的就是识别出哪些个体的哪些可行为能力被剥夺,从而测算出标示贫困深度的 “平均剥夺份额”指标,以及标示贫困人口群体综合贫困状况的 “多维贫困发生率”指标(MPI) 。
本文以 2010 河南省南阳市内乡县入户调查数据为样例,基于双临界值法,设计村级多维贫困测算指标体系,进行多维贫困测算。此处的多维贫困测算是指综合考虑收入、健康、教育以及住房条件等因子构建评价模型,测算多维贫困指数、多维贫困发生率、指标贡献度等指标来揭示区域贫困人口综合贫困状况。测算过程包括识别与加总两个环节: 前者的目的是识别出人群中的贫困个体,后者的作用是把前者识别出的贫困个体进行汇总,用综合贫困指标表示该区域的贫困状况。并在上述贫困测算基础上,基于人口密度空间化方法,分析研究区域贫困人口密度的空间分布状况; 并使用地统计插值方法,研究区村级多维贫困以及各维度或指标对贫困贡献度的空间分布状况,从而系统描述研究区贫困人口现状及贫困区域的空间化分布格局。
1. 多维贫困测算
(1) 测算维度与指标。不同研究区贫困人口识别维度与指标的选取需要遵循一些准则: 首先,测算维度及对应基础指标应能覆盖目前 “新纲要”对贫困农户的扶贫监测需求,且保证指标之间的相关性最小; 其次,在一个评价体系中,数据来源应尽可能统一; 最后,每个指标值应都能划定出一条剥夺线。本文基于多维贫困理念,针对我国目前扶贫开发策略的业务需求,以全球性多维贫困维度与指标体系为框架,以国家扶贫办建档立卡入户调查数据为基础,在村级尺度上设计建立了如表 1所示的村级多维贫困测算维度与指标体系。

由于每个维度在贫困识别中所起的作用不同,所以多维贫困加总时需要考虑每个维度和指标的权重。经过相关性分析和一致性检验等实证证明,在选择不同权重的条件下,多维贫困指数是一个稳健的指数。所以本文对各维度和指标权重的处理采用等权重方法,即经济福利、生活水平、健康、教育各维度所占的权重相等; 所有维度权重值之和为 1,每一维度内各基础指标的权重相等,即等分该维度的权重值。例如 “生活水平”维度内指标 “饮水情况”的权重值 (1/20) 就等于 “生活水平”维度的权重 (1/4) 乘以 “饮用水”指标权重 (1/5) 。
(2) 多维贫困测算方法。贫困测量必须遵循两个步骤: 识别总人口中的贫困人口和构建贫困的定量测量方法。本文在构建维度指标体系的基础上,使用 “双临界值” (剥夺临界值+ 贫困临界值) 多维贫困测算方法来综合评价贫困个体在所构建的维度指标体系中的贫困状况。其中,维度加总能够计算出贫困个体所有维度指标的综合贫困指数—MPI,维度分解则可以计算出各个维度指标对综合贫困指数的贡献程度。算法如下: 第一,根据所构建的多维贫困维度指标体系,把入户调查数据中各户所对应的数据项导入数据矩阵。第二,根据各个指标的剥夺临界值确定该研究区域所有用户在各个指标上的剥夺情况,并把个体的剥夺信息存储在剥夺矩阵中。第三,在剥夺矩阵中根据贫困临界值确定贫困个体,并且把非贫困个体的剥夺值进行归零处理,剔除非贫困个体的剥夺信息对贫困加总的干扰,把归零后的剥夺矩阵称为已删减矩阵。第四,根据已删减矩阵的贫困个体剥夺信息进行贫困加总,计算出多维贫困发生率、平均剥夺份额、MPI,通过这三个指标来反映该研究区域的多维贫困人口数、平均被剥夺的指标数量以及贫困程度。
具体变量释义见表 2。

2. 多维贫困测算结果空间化
过往学者进行多维贫困测量研究大都只是停留在统计层面上,然而这些统计数据并不能直接应用到国家的扶贫政策中,必须对多维贫困测算结果进行空间化处理。此处的空间化是指采用一定的算法或者模型,把基于行政区单元的数据 (这里主要是和贫困相关的数据) 反演到规则网格上的过程,即贫困相关数据栅格化过程。多维贫困测算结果空间化是指将多维贫困发生率空间化、MPI 空间化、指标贡献程度空间化,分别用来表示研究区域的贫困人口密度分布、贫困程度分布以及指定贫困识别指标的贫困程度分布。
(1) 多维贫困发生率空间化算法。首先,基于村级居民点数据,根据人口密度空间化模型,获得栅格大小为 600m* 600m 的村级居民点密度分布图。其中,栅格大小值通过村级居民点的聚集距离的最小空间尺度取整获得。其次,根据行政村人口数据,对研究区行政村人口规模进行分级处理并对其结果网格化。通过计算 “行政村人口数/该行政村的自然村数量”指标并将其结果进行分级处理并转换为 600m* 600m 网格。最后,根据网格贫困人口密度公式 (1) ,将前两步中计算生成的栅格数据进行栅格计算,进而得到研究区域贫困人口密度分布图。

其中,PP 表示贫困人口数,N 表示网格的自然村数量,φi表示网格居民点密度。
(2) MPI 以及指标贡献程度空间化算法。为了研究贫困人口贫困特征的空间分布情况,这里使用 GIS “地统计”方法中的 Kriging 空间插值方法对村多维贫困状况进行空间插值处理。方法如下。
首先,最优半变异函数模型选择: 步长值采用样本点的平均邻近距离; 空间数据结构性由空间变化趋势决定; 空间数据变异方向由误差椭圆变化方向决定。以 5 个评价指标 (平均误差、均方根误差、平均标准误差、标准化平均误差、标准化均方根误差) 作为半变异函数模型选择的依据,对各种常用半变异函数模型通过交叉验证方法选取最优半变异函数模型。其中,平均误差反映样本数据估值的总体误差或精度水平,均方根误差反映样本数据的估值灵敏度和极值,一般使用总体误差平均水平和各插值点的均方根误差作为半变异函数模型选择的主要的依据。这里平均误差和均方根误差越接近于 0,表明插值的精度越高,拟合的效果越好; 平均标准误差和标准化平均误差越小越好,标准化均方根误差越接近于 1 越准确。其次,精度验证: 为了证明预测数据的可靠性,比较预测数据与验证数据的差异性,即证明研究区经过样本插值后的预测数据与验证数据是否相等。这里做出假设: H0:
u1= u2, σ12= σ22和 H1: u1≠ u2, σ12≠ σ22采用 t 检验以及 F 检验方法验证数据集间是否具有显著差异。这里,通过方差齐性检验,得到 F值,并查看其显著性,如果大于 0. 1,可认为两组数据方差相等; 在方差齐性检验的基础上通过 t 检验得到 t 值及其相应的显著性概率,如果大于 0. 1,则可以认为两组数据没有显著性差异。
四、研究结果
1. 研究区多维贫困测算分析
利用河南省南阳市内乡县 2010 年的入户调查数据,通过本文所使用的多维贫困测量方法,计算得出的内乡县不同贫困临界值下多维贫困指数 (村级) 变化情况,见图 1。通常,根据不同的扶贫标准设定不同的贫困临界值来判定一个人在多少维度被剥夺到可称之为多维贫困的程度,常常与政策的制定和实施息息相关。从图 2 可以看出,贫困临界值 K =1、2、3 时,内乡县各个村的多维贫困指数都在 0. 5 左右,贫困发生率分别达到 0. 96、0. 94、0. 79。可以看出内乡县三个指标或者三个指标以上同时被剥夺的人很多,故导致其多维贫困发生率以及多维贫困指数偏高。随着贫困临界值 K 的增加,内乡县多维贫困指数开始出现明显的下降趋势,当 K =7 时,多维贫困个体几乎不存在。

在致贫因素中,例如 K =5 时,对多维贫困贡献度分布分别是: 收入 (37%) 、健康 (37%) 、教育年限 (8%) 、儿童入学率 (7%) 以及燃料 (7%) 。
2. 多维贫困空间格局分布
为了更加清楚地反映内乡县各个行政村的多维贫困指数分布情况,选取 K =5 时的各村 MPI 数据进行示例分析。根据上面指出的多维贫困指数空间化方法,多维贫困发生率的半变异函数模型为 RQ(Rational Quadratic) 时拟合的精度最高,多维贫困指数的半变异函数模型为 Hole Effect 时的拟合精度最高。
由插值结果得到图 2 内乡县多维贫困分布图。其中,将不同 MPI 值对应的区域依次划分为非贫困 (0) 、贫困 (0 ~0. 15) 、比较贫困 (0. 15 ~0. 3) 、极端贫困 (>0. 3) 。利用上面的多维贫困测算模型可以分解得到各单一维度对整体贫困的影响和贡献程度。若考虑 “健康”维度对贫困整体表征度量值的贡献度,可进行处理 (健康维度贡献度* MPI) 后,对其健康维度的贫困程度进行空间插值处理,得到图 3 内乡县健康指标剥夺程度分布图。内乡县中北部多维贫困程度最高,空间范围较广,并呈现向周围发散的趋势; 往南贫困程度降低,到达县城附近贫困程度达到了最低点; 但临近县界,贫困程度又逐渐加深。从图 3 可以看出,健康维度被剥夺的程度分布和多维贫困指数分布趋势相似,健康问题集中在内乡县中心区域,不同的是健康维度被剥夺的空间辐射面积要广,即 0. 15 ~0. 20 值域的区域覆盖面积比较大。

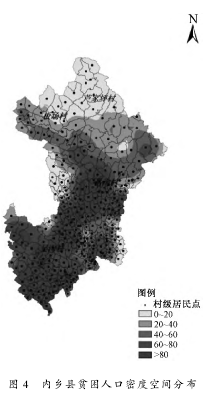
运用上面指出的贫困人口密度空间化方法,基于自然村密度,根据村级多维贫困发生率生成内乡县多维贫困人口密度分布图,见图 4。从图 4 中也可以看出,内乡县贫困人口大部分集中在内乡县中南部,且内乡县南部的贫困人口密度要比北部大很多。
五、结论
为了满足新阶段国家对贫困区域贫困个体精准识别的新需求,本文在多维贫困维度与指标体系框架下,结合研究区的具体情况系统设计了一套村级尺度的多维贫困维度与指标体系,实现了对研究区域的多维贫困测算与分析。同时,运用空间插值技术以及人口密度模型对测算结果进行了空间化处理,由此得到贫困分布空间格局及专题地图,为后续扶贫政策快速实施提供了导向保障。
内乡县贫困特点归纳如下。第一,内乡县大部分个体至少存在三个方面的贫困; 其主要致贫因素依次表现为:收入低、健康问题严重、平均受教育程度低、儿童辍学情况严重以及普遍使用不清洁燃料。第二,内乡县中北部的多维贫困程度较高,往南靠近县城附近的贫困状况有所好转; 但是,靠近西南部边界时,贫困状况又加剧。总体上,内乡县北部地区贫困状况比南部严重。第三,尽管内乡县北部地区贫困严重,但由于其北部区域为山区,海拔普遍都比南部高,人口基数少。因此,内乡县贫困人口大部分集中在内乡县中南部,南部的贫困人口密度要比北部大很多。
参考文献:
[1]国家统计局住户调查办公室. 中国农村 2011 贫困监测报告 [M]. 北京: 中国统计出版社,2012: 11 ~14.
[2]郭熙保. 论贫困概念的内涵 [J]. 山东社会科学,2005,(12) .
[3][印] Amartya Sen. 以自由看待发展 [M]. 任赜,于真译. 北京: 人民大学出版社,2002.
[4]李小云,叶敬忠,张雪梅等. 中国农村贫困状况报告 [J]. 中国农业大学学报 (社会科学版) ,2004,(1) .
[5]汪三贵,P. Albert ,C. Shubham,D. Gaun. 中国新时期农村扶贫与村级贫困瞄准 [J]. 管理世界,2007,(1) .
[6]李佳璐. 农户多维度贫困测量———以 S 省 30 个国家扶贫开发工作重点县为例 [J]. 财贸经济,2009,(10) .
[7]曾永明,张果. 基于 GIS 和 BP 神经网络的区域农村贫困空间模拟分析———一种区域贫困程度测度新方法 [J]. 地理与地理信息科学,2011,(2) .

完善社会保障管理是解决流动人口社会保障问题的必要途径。本文根据流动人口动态监测和社会保障相关数据, 从行政管理、基金管理、对象管理等方面对流动人口的社会保障管理现状进行梳理。...

引言面对人口老龄化程度不断加快的现实情况,在各类养老方式中,居家养老成为中国当前和未来的主要养老方式,在三中主要类型的养老方式(居家养老、机构养老、家庭养老)中居于基础地位,起到了某种程度的托底作用。科学全面地保障老年群体的养老生活,提...
第一章导论第一节研究背景和意义一、研究背景自古以来,健康都是人类发展的必备财富之一,作为一种重要的可行能力,健康具有普适性,且具有重要的内在价值,同时,健康对人类社会的发展也有极其重要的工具性价值。比如健康能够提高劳动者的劳动生产率...
第二章相关理论基础和概念界定第一节相关概念界定一、人口老龄化的概念界定人口老龄化是指年轻人口占总人口的比例不断减少而老龄人口占总人口比例不断上升的一种趋势。按照联合国的标准,当一个国家或地区六十岁以上的老龄人口占该国或地区总人口的百分...
第四章影响农村老龄人口健康的因素分析第一节:农村老龄人口健康的现状中国作为世界上人口最多的国家,其老龄人口的规模也是世界上最大,老龄化速度也是世界老龄化速度较快的国家之一。专家预测:我国将于2050年进入老龄化社会,在中度生育率和死亡率假...
第五章医疗服务可及性对农村老龄人口健康影响的实证分析第一节:变量选...
我国人口老龄化趋势日益加重,因病返贫、有病无法得到有效医治的现象仍然大量存在,这催促我们国家应当尽快完善我国当前的社会保障制度。由于存在体制方面的原因,财政模式转换的困难,以及当前既得利益群体的阻挠等方面的原因,完善社会保障制度困难重重。...
经过近30年的改革,我国的社会保障体系形成了多层次的框架与内容,已由原来的国家-单位保障制转向国家-社会保障制。社会保障作为国家和社会主导的一种制度性的利益分配与再分配,开始逐步发挥社会的稳定器和安全网的作用。党的十八大报告进一步明确要求...
一、新贫困人口以及我国城市新贫困人口问题的危害(一)新贫困人口随着改革开放进程的不断深化,我国的社会结构发生了很大的转变,城乡结构出现了松动,贫困人口问题不再仅仅是农村问题,城市的失业率呈现逐步上升的趋势,社会资源配置在一定程度上更加优化...
一、引言人口老龄化已经成为21世纪长期深刻影响人类社会发展的重大现实问题。2010年第六次全国人口普查结果显示,我国65岁及以上人口为1.19亿人,占总人口比重为8.87%,比2000年上升1.9个百分点。按照联合国最新的人口预测,到2030年我国6...