英语论文

大数据背景下的谷歌翻译---现状与挑战
内容提要: 在大数据时代,如何通过数据分析挖掘事物的内在规律是人们需要思考的问题。谷歌翻译基于“最好的表达为出现频率最高的表达”这样的认识,将翻译问题转化为统计问题。本文以谷歌翻译为案例,详细分析了案例背景、实现过程,并给出案例反思。谷歌翻译的成功之处在于,将实际问题巧妙地转化为统计问题,并利用其强大的计算能力解决问题。其瓶颈在于,当前的方法只利用了大数据的少量信息,不能充分刻画大数据的全部信息。谷歌翻译对问题的转化和处理方式是大数据应用的典范,对利用大数据解决实际问题有重要的借鉴意义。
关键词: 谷歌翻译; 统计机器翻译; 最大熵; 最小误差率损失。
一、背景
谷歌翻译是谷歌公司推出的针对文本、语音、图像以及实时视频的多语种翻译服务。该项目始于2001 年,上线初期采用其他同类型公司( 例如雅虎)类似的机器翻译系统,但是翻译精度并不理想[1].譬如在 2004 年,上述机器翻译系统机械地将总统候选人克里( Kerry) 翻译成“爱尔兰的小母牛”[2].2004 年下半年起,随着 Franz Josef Och 成为其首席科学家,谷歌翻译进入迅速发展阶段。在 2005 年的NIST 机器翻译系统比赛中,谷歌翻译一举拿到第一名。在 2006 年的比赛中,谷歌翻译几乎包揽全部比赛项目的第一名[3].根据维基百科公布的数据,截至 2016 年 1 月,谷歌翻译支持 90 种语言,每天为超过两亿人提供免费的多种语言翻译服务。
Och 认为,“句法知识对统计机器翻译毫无益处,甚至有反作用”[3].因此由他领衔的谷歌翻译放弃了基于句法规则的机器翻译模型。在实践中,Och 的“基本想法是从数据中学习”[2].因此谷歌翻译的工作本质上是基于多种语言的平行语料库,结合统计和数学方法,构建大数据分析模型挖掘各种语言间的内在规律。按照 Och 的观点,谷歌翻译“构造非常非常大的语言模型,比人类历史上任何人曾经构造的都要大”[2].因此,谷歌翻译本质是一种大数据分析模型,翻译结果则是基于训练好的模型,进行样本外预测泛化的结果。
2006 年,谷歌采用联合国 6 国官方语言文档作为平行语料库。随着互联网技术的不断进步,谷歌掌握的互联网数据越来越庞大,具有明显的大数据的 4V 特征[4]
: 这些平行语料库数据不仅数量庞大,而且种类很多,包括文本、声音、图像等大量非结构化数据,蕴含着大量的信息。另一方面,对于某些小语种,其语料库密度相对较低,具有明显的稀疏性。
尽管近年来谷歌翻译发展很快,但是也面临诸多问题和挑战。Och[5]指出了统计机器翻译( 当然包括谷歌翻译) 的不足: 一是不同语言组的翻译效果不一样。例如,中译英不如阿拉伯语译英。二是翻译的结果不稳健,有些文档翻译结果很好,有些很差。三是不同题材的文档翻译效果不一样,例如体育新闻比政治新闻更难翻译。而近期维基百科提供的资料表明,对于不同语言组的翻译效果不一样的问题,目前谷歌翻译还没有很好解决。另外还表明,谷歌翻译不能翻译过长的文档; 不能识别语法结构,例如不能处理时态和虚拟语气。因此,就目前的情况而言,谷歌翻译至少面临上述不足,需要面对的挑战还很多。
本文将以谷歌利用大数据分析实现机器翻译为案例,分析大数据分析在本案例中如何应用,阐述实现过程中的基本思想。并且从本案例成功方面和不足方面进行思考,阐述谷歌翻译对利用大数据分析解决实际问题的启示。
二、实现过程
谷歌翻译采用的基本工具是统计机器翻译模型( Statistical Machine Translation,SMT) .该模型将语句视为由基本语言单位构成的序列。不妨设源语言的语句为 f = ( f1,f2,…,fJ) ,目标语言的语句为 e =( e1,e2,…,eI) .其中,fj和 ei是基本的语言单元,例如词汇、短语等。在已知源语言的情况下,对应的最有可能出现的目标语言语句就是翻译的结果,即翻译结果为 e^= argmaxP( e | f) .围绕如何估计翻译模型中的条件概率,产生了很多机器翻译模型。20 世纪 90 年代初,IBM 研究人员提出噪音信道模型[6],并给出了相应的数学基础和算法[7],这些研究成果为统计机器翻译模型的研究奠定了基础。但是,接下来的研究进展缓慢,直到 2001 年谷歌开始机器翻译项目时,效果还很不理想。Och 采用了与噪音信道模型完全不同的参数化方法,提出了对数线性模型的参数化方法。Och 的研究为谷歌翻译奠定了坚实的理论基础。下面阐述这些模型的基本思想。
( 一) 翻译模型
Och 等[8]在 2002 年提出了基于对数线性模型的参数化方法:
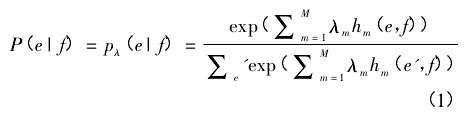
其中,hm( e,f) 为特征函数( feature function) ,λm是权重。特征函数事先选定,不同的特征函数将得到不同的翻译模型。事实上,当取 M = 2,λ1= λ2= 1,h1( e,f) = log[P( f| e) ],h2( e,f) = log[P( e) ]时,式( 1) 就退化为噪声信道模型。因此,式( 1) 是一种非常一般的模型。但是一般情况下,权重是未知参数,需要进行估计。
式( 1) 是这类模型的最基本形式。为了进一步考察不同语言间,基本语言单位之间的对应关系,可以在式( 1) 的基础上引入一个隐随机变量 a,这个随机变量是对不同语言间基本语言单位对应关系的刻画。于是式( 1) 改进为:
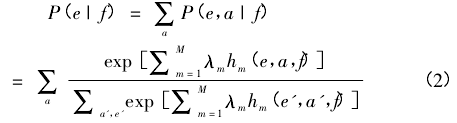
式( 2) 可以解决语言单位之间的一对一和一对多的对应关系。但是对于多对一和多对多的情形,需要进一步改进。Och 等[9]在 1999 年的文章中首次提出对应板块( Alignment Template) 的概念。其处理方法的本质是将平行预料分块,在不同分块中,再考虑不同的对应问题。这种处理方法在一定程度上考虑了上下文信息,和不同语言间语法结构的不同,因此在统计翻译模型中有重要地位。对应分块模型的表达式如下:
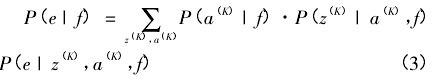
其中,z( K)表示对应板块,a( K)表示对应板块中的对应关系。式( 3) 中有 3 个连乘的条件概率,可以分别利用对数线性模型进行参数化,并且可以选择不同的特征函数。从而增加建模的灵活性[10].
( 二) 参数估计和翻译结果
翻译模型中的参数是特征函数的权重: λ =( λ1,…,λM) .在经典统计理论中,对数线性模型可以采用极大似然方法估计参数。但是,当数据是大量的平行语料库时,对总体是不能做合理的分布假定的,直接采用极大似然估计不合适。Och[10]根据信息论中的最大互信息( Maximum MutualInformation)原理构造了基于最大熵的损失函数,通过最大化损失函数,得到参数估计,即:
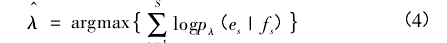
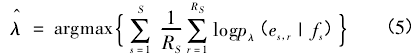
其中,源语言有 RS种目标语言的参考译文:es,1,…,es,RS.基于损失函数式( 4) 和式( 5) 的翻译模型称为最大熵模型( Maximum Entropy Models) .
Och[11]进一步指出,最大熵模型的优化本质上是翻译好坏的间接评价,为此他提出基于最小误差率损失( Minimum Error Rate) 的参数估计方法。这种损失函数是基于对翻译结果的直接评价得到的,其具体表达式为:
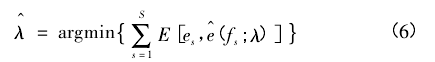
其中,E(·) 是误差函数,用于刻画参考译文 es与模型给出的翻译 e^( fs; λ) 之间的差异。实践证明,基于损失函数式( 6) 的翻译模型优于最大熵模型[12].2014 年,Och 等人将该方法申请了专利①。
在得到权重估计值之后,最终的机器翻译问题便归结为模型的样本外预测问题,即:
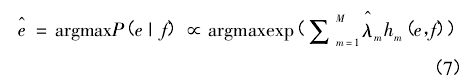
其中,e^表示从源语言 f 出发得到目标语言的翻译结果。
三、案例反思
谷歌翻译的成功,是利用大数据分析解决实际问题的典范。但是,当前谷歌翻译还有很多瑕疵,不可能达到人工翻译的精确度。围绕此案例,我们从四个方面进行反思总结。
第一,谷歌翻译是大数据时代的产物,其效果的好坏受到平行语料库数据量的制约。从翻译模型的定义可以看出,谷歌翻译的基本思想是由训练样本探索语言规律的过程。其中不同语言之间的对应规则是模型参数。谷歌翻译试图用平行语料库反映出来的规律来推测参数。由于语言规则复杂,势必要求样本信息足够大才能有好的效果。尽管谷歌掌握的平行语料库总量很大,但是也面临三个不同: 不同的语言组之间的平行语料库数量不同; 不同题材的平行语料库不同; 不同语言组的翻译需要的样本量不同。上述差异是造成谷歌翻译处理不同语言组效果不一、处理不同题材文档效果不一的重要原因。这个事实也启示我们,大数据时代,数据的大小是相对的,对某些复杂问题必然需要大数据。例如对于进一步提高中译英精度的问题,当前的数据量似乎还不够大,谷歌需要找到更多的平行语料库才能逐步解决这些问题。
第二,谷歌翻译模型在识别上下文信息方面存在不足。事实上,谷歌翻译模型只通过引入隐变量刻画了基本语言单位的对应关系。但是,对于语言,上下文不仅仅是邻近的几个词汇和短语的信息就足够了。很多时候上下句之间就构成了上下文。甚至段落与段落之间,都需要考虑的上下文。从识别文本信息角度而言,谷歌翻译的算法只识别了文本的少部分信息。这就造成机器翻译不能识别语法信息,例如时态,虚拟语气等。当然更不可能与人工翻译的质量相提并论。语法的重要性对于翻译而言是显而易见的。为了让计算机能够识别语法信息,仅仅让计算机识别少量上下文信息是不够的。需要更加先进的方法,经验贝叶斯方法[13]可能是一条途径。事实上,贝叶斯方法已经在人工智能方面有了成功的应用,例如 Lake B M 等[14],实现了机器人像人类一般学习书写。
第三,大规模计算问题是统计翻译模型面临的重要问题。谷歌翻译不能翻译过长的文档,很重要的原因是计算能力的限制。但是,模型的复杂度和模型的效果需要进行权衡。追求精确是建模的重要目标。但是谷歌翻译的案例显示,考虑到模型的复杂度,有时候需要牺牲一部分精确度,并且对翻译的文档长度进行限制。吴军[2]以噪音信道模型为例阐述了这个问题,假定取长度为 n 个词作为一个基本语言单位,则模型的空间复杂度为 O(Vn) ,时间复杂度为 O(Vn -1) .其中,V为语言词典的词汇量。随着 n 的增大,计算量呈指数级增长。但是n = 3 和 n = 4 之间的精确度变化不如 n = 2 和 n = 3.事实上也是如此,目前谷歌翻译模型选择 n = 4[2.因此,囿于计算能力,模型复杂度不可能过高,翻译文档也不能过长。
第四,谷歌翻译模型没有对模型参数做任何分布假定。这和经典的统计建模区别明显。检验模型好坏的标准不涉及经典统计学中的显着、p 值等概念。翻译结果的好坏是检验模型好坏的唯一标准。从统计学习角度而言,模型外推能力是检验模型好坏的唯一标准。这是和经典统计研究方式的一个很重要的差别。事实上,对于大数据,其分布形式是什么是不得而知的,不能对其分布形式做唐突的假定。吴军[2]指出“引入人为的假定,这和蒙没什么差别”.这也许是我们在挖掘大数据信息时,非常值得注意的地方。
将本属于语言学范畴的翻译问题,转化为基于大数据分析、利用统计模型和算法进行参数估计和预测的问题,这是谷歌翻译的成功之处。其大数据分析的思想和方法十分深刻,值得我们学习借鉴。
谷歌翻译的瓶颈在于,当前的技术只利用了数据少量的信息没有充分挖掘文本的全部信息。另外,计算问题也制约着谷歌翻译。因此,发展新的技术,充分挖掘大数据信息,需要人们的进一步思考。
参考文献
[1]Levy S. In the plex: How Google thinks,works,and shapes ourlives[M]. Simon and Schuster,2011.
[2]吴军。 数学之美。 第 2 版[M]. 北京: 人民邮电出版社,2014.
[3]黄瑾,刘洋,刘群。 机器翻译评测介绍[C]∥第一届全国少数民族青年自然语言处理学术研讨会,2008.
[4]李金昌。 大数据与统计新思维[J]. 统计研究,2014,31( 01) :10 - 17.
[5]Och F J. Statistical Machine Translation: Foundations and RecentAdvances[EB / OL]. In: TENTH MT SUMMIT,2005.
[6]Nirenburg S,Somers H,Wilks Y. A statistical approach to machinetranslation[J]. Computational Linguistics,1990,16( 2) : 79 - 85.
[7]Brown P F,Pietra V J D,Pietra S A D,et al. The Mathematics ofStatistical Machine Translation: Parameter estimation [ J ].Computational Linguistics,1993,19( 2) : 263 - 311.
[8]Och F J,Ney H. Discriminative trainig and maximum entropymodels for statistical machine translation [C]. Proc of AnnualMeeting of the Association for Computational Linguistics,2002: 295- 302.
[9]Och F J,Tillmann C,Ney H. Improved alignment models forstatistical machine translation[C]/ / Proc. of the Joint SIGDATConf. on Empirical Methods in Natural Language Processing andVery Large Corpora. 1999: 20 - 28.
[10]Och F J,Ney H. The Alignment Template Approach to StatisticalMachine Translation. [J]. Computational Linguistics,2004,30( 4) :417 -449.
[11]Och F J. Minimum error rate training in statistical machinetranslation [C]/ / Proceedings of the 41st Annual Meeting onAssociation for Computational Linguistics-Volume 1. Association forComputational Linguistics,2003: 160 - 167.
[12]宗成庆。 统计自然语言处理。 第 2 版[M]. 北京: 清华大学出版社,2013.
[13]Efron B. Large-Scale Inference[M]. Cambridge University PressCambridge,2010.
[14]Lake B M, Salakhutdinov R, Tenenbaum J B. Human-levelconcept learning through probabilistic program induction [J].Science,2015,350( 6266) : 1332 - 1338.