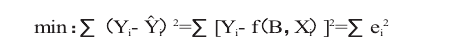摘要:计量经济模型的参数估计是实证经济分析的关键,其在建模技术中处于核心的地位。估计模型参数属于统计学中的参数估计内容。常用的估计方法主要包括最小二剩法、极大似然估计法、矩估计法和贝叶斯估计法等。而这些方法的应用,取决于计算机及其软件的编程。利用 R 软件可以很容易的实现对模型参数的估计,不论是线性模型,还是非线性模型,主要使用 lm、glm 和 nls等几个命令函数来实现。
关键词:经济建模;参数估计;经济参数;R的使用。
一位朋友获得到了一笔意想不到的奖金,于是计划着买一件观注已久的名贵消费品。而同事同样也得到了一笔工资之外的收入,他却将这笔钱用于了投资。用经济学的术语就是前者的消费倾向很高,而后者的消费倾向较低。然而一个地区的消费倾向,应该是该地所有居住者的平均消费倾向。它往往反映着该地区的生活水平和经济发达的程度,是人们比较关心的话题。
这类信息又不可能直接调查获得,因为哪些收入是新增的,以及个人之间的倾向差异较大,抽样的代表性很难保证。所以此类信息的获得主要是通过模型测算的,即以观测得到的消费为被解释变量,收入为解释变量来构建回归方程,其回归系数就是收入的边际消费倾向。在经济模型的各构成要件中,参数是用来表述具体经济关系的重要因素,如消费倾向就是收入决定消费模型中最重要的经济参数。在现实的经济观察中,人们较易观测到收入和消费支出的数据,却很难直接观测到消费倾向的数据,因此我们通过建模来推算。而这种对模型参数进行推算的过程,常被称为模型的估算。
一、经济参数估计及主要方法。
经济模型是用来描绘经济关系方程式或方程组,在经济模型中的各种变量是我们看得到的经济现实,模型中的每一个方程都表述着各变量之间的经济关联。而变量之间精确关系的规律性反映,主要是由模型中伴随着变量存在的参数来承担的。既然是规律性的东西,就是固定不变的。所以建立模型的过程也就是通过变量和方程式的变化观察,来寻找不变的经济参数的过程。为此采用统计回归的方法来探求模型参数的作法最为常见,即依据人们已有的经验或理论成果设定出回归方程的形式,结合一定数量的统计观察来估算出回归方程的具体参数的过程。这种估算的具体方法,主要有如下几种:
1.最小二乘估计法。
在给定一组样本观测值(Xi,Yi)(i=1,2,…n)前提下,即我们能够看到经济现象 X(如收入等影响因素,X可以是一个变量构成的向量,也可以是由多个变量构成的矩阵)和 Y(如消费等被影响因素)的变化过程。且初步认定两者关系的回归方程为Y赞i=(fB,Xi)时,其中Y赞i是被解释变量 Yi的回归拟合值,该方程表明 Yi的变化取决于 Xi的作用,其作用程度就是稳定的 B值(B 为列向量)。要得到该理想的回归方程,就要选择一系列适合的 B 值,以使实际的 Yi与回归测算的Y赞i之间的差距(即残差)达到最小。由于数值残差有正负之分,即使差距很大时也能保证残差之和为零,这样依据残差的分析很难得到控制残差的目的。而将各残差的平方和达到最小的约束控制,却具有唯一性的特点,是求解控制参数的理想目标。这种以样本观察值与回归估计值之差的平方和达到最小约束的参数求解方法,就叫做最小二乘法。其一般表达式为:
这种以残差 ei的平方和达到最小为目标的求得 B中各元素 bk的常规作法,就是将 B 向量中的各个元素bk都看作是变量,而将 X 和 Y 看作是常量,求多项式∑[Yi- (fB,Xi)]^2关于 bk的偏导数式并令其为零,从而可以形成一个由参数个数决定方程个数的方程组,而该方程组的解就是回归方程的经济参数解。
2.极大似然估计法。
极大似然估计方法也是依靠样本的信息,对总体的参数进行估计的常规方法。只是它适合于总体概率分布的类型已知,但分布的具体参数未知时使用。它是以我们得到的样本在现实中出现的概率达到最大为依据进行的参数估计,即样本各单位同时出现的似然函数达到最大时的参数为估计的结果。
与最小二乘估计相比,它的约束条件不是样本的残差最小,而是样本产生的概率最大。其基本原理就是将 n 组数据构成的样本观察值中的每一组 X 和 Y 都分别代入到回归方程中,并将这 n 个方程式视为同时发生事件,即以各个方程发生的概率函数的连乘积来构建该样本发生的概率函数,并称之为似然函数。而极大似然估计法就是以该似然函数取极大值为约束来求解经济参数的。
当总体的概率分布已知时,才能使用极大似然估计。即不同的概率分布,似然估计的结果会有很大的差异。由于在模型估算中人们对总体方程的概率分布往往是未知的,应用极大似然估计受到了一定的限制。不过依据概率论中的中心极限定理,大样本下一般的总体都服从正态分布。所以依据正态分布的估算也很常见,即人们经常假定总体分布是正态的,并在该假设前提下应用极大似然估计方法。具体步骤如下:首先,利用总体的概率分布函数 n 维乘积得到似然函数;其次,将似然函数中的自变量看作是常量,而将参数看作是自变量,先对其求导数,并令该导数为零,求得使似然函数最大的估计量;最后,将样本数据代入到似然估计量的计算式中,得到极大似然法的参数估计值。
3.广义矩估计法。
矩函数是统计学中常用的指标函数,即变量值的 k次乘方的平均值就叫 k 阶原点矩。而变量与其均值的离差的 k 次乘方的平均值,就叫 k 阶中心矩。矩函数则是将原点矩、中心矩、相关系数、回归系数等一系列特殊统计指标,以一个统一的一般形式表达的函数。矩估计方法是统计估计的常用方法,其基本思想就是以样本的矩函数来代表总体矩函数的过程。由于回归方程的估计是为了使残差达到最小的估计过程,所以借助于这一思想,对各回归系数的估算考虑如下:
首先,关于回归方程误差的矩函数可以表述为ε=Y- Xβ,该误差列向量实质上是在 X 给定的条件下,各组观察值偏离回归值的程度,即以总体回归方程为中心的实际偏离。而该离差的期望值就是在 X 给定条件下的总体一阶中心矩,随着 X 的条件不同,以该距离为核心的函数表达式就是一阶中心矩函数。
其次,以样本的参数估计量代替总体参数,并形成样本的矩函数,有∑ei=i(‘Y- XB)=0,根据该方程组可以求解出各参数的估计值 B,但是该方程组存在着能否识别的问题。在方程的个数等于未知参数的个数时,有可能求解,或称之谓恰好识别。但是矩估计是依据大数定律进行的,它要求对总体观察的样本数量要尽可能大。而在大样本时,即样本容量为 n 组观察值,则可以建立 n 个方程。即当 n≥K+1 时,方程组常是过度识别的。解决这种过度识别的方法就是将各组数据都参与各参数的估算,只是估算的结果以 X 为权重进行加权平均。该过程就是将上式中的单位向量 i,换为矩阵 X的简单过程。即 X'Y- X'XB=0,所以就有了 X'Y=X'XB.在 X为确定的变量观察值时,线性回归方程的参数估算公式将为 B=(X'X)- 1X'Y.人们将这种过度识别的,并采取加权方式进行估计的过程称之谓广义矩估计。
4.贝叶斯估计法。
概率论中着名的贝叶斯分式,也叫后验概率公式。它所描述的是通过对现实样本信息的观察,来修正对该事物的先前认知。在经济研究中,研究者对研究对象都有初步的认识。这类样本之外的信息,在上述的各种估计方法中都被忽略了。从信息充分利用的原则出发,在考虑先前信息的条件下,通过样本信息的修正,来测算研究对象的真实概率分布。有了真实的概率分布,才能得到准确的参数估计。这就是贝叶斯估计的基本特点,它较其他方法更接近现实,利用的信息更系统。
二、模型估计量的质量评价。
采用不同的方法对方程求解所估算的结果常有不同,因此需要一定的标准来评价各种方法的科学性,高斯和马尔科夫的研究认为具有线性、无偏性、有效性的估算方法是最佳的。在放宽条件时,达到一致性的要求也就是较好的估计了。其具体含义如下:
1.线性。
线性是指估计量 B 与研究对象 Y 是线性的关系,它表明在解释变量确定时,经济参数的改变会引起被解释变量的确定性改变。
2.无偏性。
无偏性是指经济参数估计的均值或期望值是否等于总体的真实值,即对于参数的估计量有 E(B)=β。
3.有效性。
在所有的无偏估计中,方差最小者为有效,即对于任意的无偏估计量 G 与有效的无偏估计量 B 必有 Var(G)≥Va(rB),即 B较任意的G更具有效性。
4.大样本下的一致性。
一致性是指样本容量趋于无穷大时,样本估计量是否依较大的概率收敛于总体参数的真值。具体表现为渐近无偏性和渐近有效性。渐近无偏性是指样本容量趋于无穷大时,样本估计量如果能趋于总体经济参数时,则称之谓具有渐近无偏性的统计估计量;而渐近有效性是指样本容量趋于无穷大时,样本估计量如果是所有的一致估计量中方差趋于最小者,则称之为渐近有效的估计。
前面所学习过的各类估计方法所得到的估计量,都能满足这些性质的要求。且在大样正态分布的总体假设下,最小二乘法、极大似然估计法和广义矩估计法所得到的线性估计的结果是相同的。同时也可以证明三种方法都是线性无偏的一致有效的最佳估计量。
三、回归方程估算程序。
不论是前述的哪种估计方法,要实现其估算操作,都需要编制计算机的程序软件。而成熟的程序软件很多,大致可以分为两类,一类是隐藏内码的软件商品,如 SAS、SPSS、STAT、MATLAB 等一系列公司开发的商品软件。另一类是开放内码的,公益性开原软件,如 R软件。
在 R 程序中提供了一系列很方便使用的估算函数。主要内容介绍如下:
1.线性回归模型的估算程序。
使用 R 软件求解线性回归方程是非常方便的,求解中可以对模型参数进行点估计和区间估计。参数的点估计命令为 1m(模型公式,数据…);对该函数的各参数说明如下:
(1)模型公式:被解释变量 ~ 解释变量 1+ 解释变量 2+…+ 解释变量 K(注:公式中加入“0”项时为无截距的方程)。数据:为内存中的向量或数据框中的数据。如果是内存中的数据对象,则该项可以省略。如果是数据框中的数据,则要在该项中指明数据框。
(2)参数的区间估计。
如果要进行区间估计,则需要在点估算的基础上,并将其存入回归对象后,可以使用如下命令做区间估计:confin(tobject,parm,level=0.95,…);各参数意义如下:object:指回归估算的结果对象名;parm:指定区间估计的参数列表,默认时为全部;level:估计的把握程度,默认时为 95%.
2.回归对象可以读取的其他信息。
在回归的程序中还包含着残差和回归值等若干信息,需要时可以采用如下读取方法:
(1)残差项数据。
使用“回归对象$resid”就可以获得回归对象中的残差信息,或者使用 residuals(回归对象)读取残差;使用 rstandard(回归对象)函数计算获得标准残差;使用rstudent (回归对象) 函数来计算获得学生化的标准残差。
(2)预测值数据。
对样本数据进行回归的估计值也可以观察到,即使用“回归对象$fitted.values”,或使用 predic(t回归对象)函数进行回归预测。
(3)回归对象中的其他常用信息。
对回归对象可以使用如下命令可获得一些回归分析的有用信息:
①回归对象$df:获得回归的自由度;②回归对象$coef或 coef(回归对象):获得回归系数估计值;③logLik(回归对象):获得回归的自然对数似然统计量;④vcov(回归对象):获得回归系数的方差-协方差矩阵。
利用这些信息可以进一步测算更多的有关回归分析的评价指标,并将其绘制成图,以直观反映这些特征。
3.非线性回归的估计方法。
一个现象的数量可随另一个现象而改变,但是改变的量是非固定的常数,反映这种关系的模型就是非线性模型。对于非线性模型的参数估计,基本上可以分为如下两种情况:
(1)可线性化的模型。
主要采取变量置换和取对数这两种处理方式,将非线性摸型转化为线性模型,然后再利用线性模型的求解方法进行求解,或者采取广义线性程序来求解。在R 中广义线性程序为 glm(线性公式,模型方法选择,数据源);其中各参数使用方法如下:线性公式 formula:公式的列示方法与前述相同。模型方法选择 family:是选择特定的分布等类型(默认时是正态分布模型,即与 lm函数相同),如选择 family=binomial 时,是二项选择模型,其默认方法是 Logit 模型;而要选择 Probit 模型时,就要使用 family=binomia(llink=probit)来表达。数据框data:指定公式和模型中使用的数据来源。
(2)无法线性化的模型。
回归方程无法进行线性化时,由于多数非线性方程不存在求根公式,因此求精确根非常困难,甚至是不可能的。为此,牛顿在 17 世纪提出的一种在实数域和复数域上,近似求解方程的方法,简称牛顿迭代法(Newton's method)。该方法的基本思想是:先给一组参数估计的初始值(如线性解 B),在 B 处做泰勒级数展开有 (fX,β)=(fX,β)+[α(fX,β)/αβ](β-B);设 D=α(fX,B)/αB为 K 阶列向量,则有 (fX,β)=(fX,B)+D(β- B)则原模型可表述为 Y=(fX,B)- DB+Dβ+ε;进一步设 Y- f(X,B)+DB=y;则有线性化的模型 y=Dβ+ε;对该线性模型可以求得关于 β 的线性最小二乘解 C.该解 C在形式上是变量替换后的最小二乘法或极大似然法的线性解,实质上是其非线性近似解。如果将该 C解做为初始解,重新进行上述变换和求解过程,则可以得到更加近似的迭代解。如果将该迭代过程循环进行下去,就会使迭代解逐渐的趋近理想的估计值,不过这一过程需要依靠计算机程序来完成。在 R 中的非线性求解程序为 nls (formula,data,start,control,algorithm,trace,subset,weights, na.action,,…);各参数说明如下:formula 表示似然函数或回归方程的公式;data 表示样本数据框,可以是数据列单,不可使用矩阵;start 表示初始的参数值;control 表示控制列表可选项;algorithm 表示线性部分设定;trace 表示显示打印设置;subset 表示指定拟合数据子集;weights 表示指定加权最小二乘的权重;na.action 表示缺损数据的处理等。注意:使用 nls 采用同一数据系统,求解线性方程所得到的结果与 lm 函数相同。同时,对于特殊的非线性问题,R 软件中还提供了一些求极值的函数,如单一参数的点估计函数 optimize(),多参数的牛顿迭代似然估计函数 nlm(),通用极值函数 optim()等,都可以使用,具体用法可参见在线帮助。
参考文献:
王涛《计量经济学》科学出版社 2015/6.