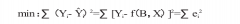计量经济学模型使用中的常见问题剖析
来源:统计与咨询 作者:王涛
发布于:2017-06-06 共3709字
摘要:建立计量经济建模的目的就是用来模拟现实,以达到经济分析。政策测定。预测与决策。理论的实证与检验等多角度的使用需求。然而在现实的应用中却存在着许多的不恰当使用问题,主要表现为模型不检验。甚至未通过检验就使用的问题。这些不恰当的使用主要是对模型及建模工具的理解偏差等原因造成的。如果不加以重视,不但达不到经济分析的目的,甚至会误导后续的研究,以及错误的决策,还会造成重大的经济损失。
关键词:计量经济模型;模型检验;模型应用;协整检验。
计量经济模型是对复杂的现实进行抽象和简化的有效工具。其将社会经济活动的主要关系以方程式的形式表达,让使用者一目了然。同时,这些主要关系往往都是经济社会问题的主要矛盾的反映。所以一个好的模型就应该反映出这些问题产生的因果关系,根据这些因果关系就可以有依据的制定政策和计划方案,提高我们的管理效率。然而在现实的模型使用中,却存在着很多的问题,本文将就模型使用中常见的问题剖析如下:
一、对模型的理解及其使用偏差。
在学生的论文答辩或中期的检查中,经常会遇到为什么不在文章的某处建个模型?或者是我想在某处建个模型该怎么做?甚至某些高校的论文规范中要求论文中都要包含模型才能及格等等问题。产生这类问题的原因,就是对模型一词的理解偏差,即认为模型就是一个方程式,所以在文章的某处加入表明某种关系的方程式就算是建模了。这种错误可能产生的后果就是局部的关系与全局系统是否恰当问题。即局部的关系在全局中是否真的起作用并没有得到实证,甚至是局部关系与全局的关系相矛盾。如果在论文写作的制度规范中要求有模型,则这种制度规范必然会引起学生们对模型理解上的偏差。这种偏差不但会迅速扩大,还会很容易导致大量的形而上学式的分析结果。
我们所写的任何一篇学术研究类的论文,都可以看做是一个模型,或者是更大模型中的局部细化。即使你没有使用模型一词,也没有想构建什么模型,你都避不开文章的框架和对现实的各类描绘。现实属于客观的存在,你的描绘就是对现实存在的抽象缩影,这种抽象就属于建模。只不过你使用的是语言描述,并非方程式而已。现代意义上的计量经济模型,是以方程式(组)加残差的形式构成的。往往是复杂的社会经济问题的简化描述,它应该是论文的核心,而论文的其他部分则是对模型解释、铺垫、基础说明等内容。
二、建模理论的恰当性。
任何一个模型的构建都有着其观察视角,及其理论或经验依据。只有你依据的理论符合现实时,你才能得到有代表性的有效模型。这种有效性在模型的使用阶段主要表现为预测性误差很小。这一点在现实的模型使用中是很难做到的,主要原因如下:
首先,我所依据的理论经验,多是盲人摸象式的观察和感受得到的。这种有偏感受的代表性,自然要影响到模型的质量。由于西方主流经济学的形式化片面发展,使得其经济理论很难符合我国的现实,其解释力也很有限,而我们的很多学者又以学习和借鉴西方理论来构建模型,所以这是目前的大量模型无效的根本原因。
其次,计划经济的实验性道路的失败,社会主义市场经济的初建时间不长。还有很多理论和猜想需要实践的检验。在没有实践检验之前,我们的猜想所产生的任何偏差都会引起模型的无效。
三、对现实观察的恰当性。
统计观察数据是决定模型有效的另一个重要因素,即在模型的初步设计后,我们多会感觉到观察数据的短缺,于是会产生很多获取统计数据途经,进而就会产生一系列的数据代表性问题。这在论文写作中又是普遍存在的较严重的问题,其具体的表现及成因可能有如下几个方面:
第一,有相当一部分论文采取以相关数据来替代实证所需的观察数据,而已有数据的代表性就成为模型有效与否的主要问题。由于已有数据多是国家统计局的公开信息,因此很多模型的内涵不同,实证的结果却都很相近,甚至模型的经济意义都变了味道。
第二,有部分论文采取了自己组织问卷或采访等方式来获取所需数据。这是值得提倡的做法,但是由于观察范围的有限,很难获得会面有代表性的系统数据。进而使得模型也不具有代表性了。
四、模型应用的条件及其恰当性。
反映社会经济现象的系统性模型很多,常见的模型及其应用条件是人们经常忽略的问题,现总结如下:
第一,最简单和最常用的系统模型就是期望值为零,方差为固定常数的随机干扰系统。它是计量经济模型的重要组成部分,建模过程中以残差的方式出现。如果模型中的解释变量能够很好的解释被解释变量的话,则残差将是零均值、同方差、无自相关的平稳变化的随机干扰子系统。否则,残差将表现出存在异方差或自相关等严重问题。
第二,对社会经济现象的动态规律的研究,可以通过自相关、偏自相关、互相关等函数的分布特征,来确定计量经济模型中各变量的滞后阶数。即当某变量的自相关函数是拖尾的,而偏自相关函数表现为 P 阶截尾的特征时,则说明该变量为 P 阶自回归过程 AR(P);如果某变量的自相关函数是 Q 阶截尾的,而偏自相关函数却是拖尾的,则该变量为 Q 阶移动平均过程 MA(Q);如果一个变量的自相关和偏自相关函数都是截尾的或都表现为拖尾的特征时,则该变量就是自回归移动平均过程 ARMA(P,Q)。在回归模型中如果被解释变量是自回归过程,则该模型就叫做自回归模型 ARM;如果解释变量是自回归过程,则该模型叫做分布滞后模型 DLM;如果两者都是自回归过程,该模型就叫做自回归分布滞后模型 ADLM.ADLM 的分布滞后阶数可以通过互相关系数的阶数,或格兰杰因果检验等方法来分析判断。
五、模型的估算和检验的恰当性。
模型的估算和检验多是采用固定的程序进行的,其中的算法、应用条件、使用原则等方面的不恰当使用,或者根本不进行检验等情况的广泛存在,使得模型的有效性大大减弱。常见错误的主要表现如下:
(一)没有进行各类检验或检验内容不全面的问题。
在上期有关计量模型的检验知识介绍中,我们将对模型的检验分为四类,其中的绝大多数检验都是要做的。而我们会看到很多不做检验就使用的模型,这在科学研究中是很避讳的事情,然而这种避讳却是目前很容易出现问题。模型构建中的某些检验是必须要做的,如变量的显着性检验、残差的异方差性和自相关性检验等等都是不能缺省的。
(二)模型估算上的主要问题。
目前在计量建模中的估算方法很多,尤其是机器学习思想引导下,新的人工智能研究所得到估算方法更多。而这些算法所产生的偏差及随机干扰性的误差,多数是不可控制的。其中经过证明的最佳线性无偏估计很少,很多方法需要逐步修正来完善。而这一完善过程需要收敛集中才有意义。可在实际建模中,却存在着大量的只适合内插预测,不适合外推预测的估算模型。
如大量的存在条件异方差、自相关的各类模型,以及向量自回归的、两点法、三点法、指数平滑和移动平均等方法得到的估算模型,往往都存在着这类不收敛问题。
(三)回归与协整分析的恰当使用问题。
回归分析的方法在自然科学的研究中广泛使用,且效果很好。但是在社会科学的研究中,却广泛的存在着伪回归的问题。为了避免伪回归,恩格尔和格兰杰等学者研发出协整分析的相关内容,并因此而获得了诺贝尔经济学奖。然而我们在使用和理解这些知识时却产生了很多问题:
首先,将协整与回归分裂开来,并视为豪不相关的东西。在自然界的大量平稳现象中,回归关系是稳定的,所以回归分析是科学研究中最常用的方法之一。但是在经济学的研究中,人们发现社会经济现象绝大多数都是非平稳的(即单整过程)。在非平稳的现象之间建立回归方程,很容易产生伪回归的结果。即本来豪不相关的现象,往往被认为是因果关系,且统计上是显着的。只有协整系统所表现出的回归关系,才是真正的因果关系,我们称之为协整回归。
协整系统是指由一系列不平稳的单整序列构成的复杂稳定系统。在该系统中,就各个单整序列而言,都是不稳定的。而它们综合在一起时,却表现为平稳的状态。所以在求解回归方程时,需要进行协整性检验,即观察其残差项是否为平稳的,若残差平稳,则回归方程就是协整的回归。
其次,为了避免伪回归,提高寻找协整回归的效率,在建立协整回归之前,先要对各回归元素进行平稳性检验。一般要求各回归元素都是同阶单整过程,若单整阶数不同,则要求被解释变量的单整阶数不能单独高于解释变量的单整阶数,且最高阶的单整变量要在两个以上。这是保证多阶协整关系存在的必要条件。
六、模型能否好用问题。
模型的作用一般认为是预测、政策模拟、结构分析、理论验证等四个方面。其中经济预测是最基本的使用,所以保证能够预测是对模型好用与否的最基本要求。由于早期的计量经济建模多是截面数据模型,用于动态性预测时很不准确,后来人们又开发出很多时序分析的方法。然而时序分析用于预测时,又多基于“鉴往知来”的统计经验规律进行的,所以在不平稳的现实社会经济问题中,由于历史重演的可能性不大的,因此预测也很准确。这样人们比较热中的向量自回归 VAR、AR、ARMA、DLM 等一系列序列模型的使用都未必是有效的。也正因为如此,目前倍受关注的面版数据模型,可以使用静态数据验证动态规律,使用动态数据来验证静态规律,这很可能是较为有效的建模途径。
上述所涉及的各类问题,都是我在教学和科研中发现的,多数同学容易犯的错误。而处理原则也只是我个人的体会和经验,仅供同学们参考使用。
原文出处:王涛. 计量经济模型的使用[J]. 统计与咨询,2016,(06):46-48.
相关内容推荐
-
探讨劳伦斯・克莱因的主张及其建立经济计量模
1980年10月15日,由瑞典皇家科学院宣布,授予劳伦斯克莱因诺贝尔经济学奖金,从而表彰他在创造计量经济学模型将该模型用于经济波动分析和经济政策方面的贡献。他是当代西方经济学流派中着名的经济计量学家。计量经济学是经济学的一个分支。计...
-
分析计量经济学模型基本功能和局限性
在经济学理论研究中, 计量经济学模型被得到了广泛的应用, 并逐渐发展成为一个主流实证经济研究理论。虽然计量经济学模型有着非常强大的功能, 但是在使用的过程中也存在一定的局限性。...
-
计量经济模型的参数估计方法
摘要:计量经济模型的参数估计是实证经济分析的关键,其在建模技术中处于核心的地位。估计模型参数属于统计学中的参数估计内容。常用的估计方法主要包括最小二剩法、极大似然估计法、矩估计法和贝叶斯估计法等。而这些方法的应用,取决于计算机及其软件的编...
-
计量经济模型检验方法探析
经得起上述各种检验的模型,应该是较好的可以实际使用的模型了。不过上述各类检验都是基于观察数据的范围内进行的,属于内插式的检验。而从实践是检验真理的唯一标准出发,真正的实践是外推性的。所以在模型建成后,还要经过若干时期的实际应用的检验。这类检...
-
我国人均卫生费用的变化进行定量的分析和预测
近年来, 国内卫生医疗领域的矛盾日益显现, 成为了影响社会发展的不和谐因素, 它不仅影响到国民的健康, 也带来了贫困、公众不满情绪、群体间关系失衡等一系列社会问题。...
-
影响我国粮食产量的计量经济学模型探究
根据官方数据, 通过模型设定、估计、检验、调整, 得出影响我国粮食产量的计量经济学模型。分析了影响我国粮食产量的主要因素, 提出了相关建议。...
-
国家税收收入的预测分析及政策建议
1研究背景从21世纪以来,中国在科技与互联网产业飞速发展的基础上,经济的发展迫在眉睫,面临着巨大的压力和挑战,新形势下的经济发展是经济稳定与和谐发展的结果。税从经济中来,而又作用于经济。运用计量经济模型分析我国税收收入其作为一种无可替代...
-
-
计量经济学模型四个方面的应用
1、引言1.1国内外计量经济学的发展。计量经济学(Econometrics)一词最早是在1926年由挪威经济学家、第一届诺贝尔经济学奖获得者R.Frisch发表的《论纯经济问题》一文中,按照生物计量学(biometrics)一词的结构提出的。但计量经济学作为一门独立学科被...
-
网络视频的计量经济学模型建立方法
本文采用2009年第一季度到2015年第三季度的相关统计数据, 给出建立计量经济学模型和对其进行多种检验的详细过程, 并根据模型预测未来网络视频市场规模。...
相关标签: