税务硕士论文

我们从中有针对性的选取了电气机械和器材制造业、食品制造业、水的生产和供应业、批发业和零售业等 18 个重点管理行业进行分析。
4.3.3 建立面板数据模型
面板数据模型根据截距项向量和系数向量中各分量的不同可以划分三种类型:无个体影响的不变系数模型(混合模型)、变截距模型、含有个体影响的变系数模型:形式一:无个体影响的不变系数模型的单方程回归形式可以写成【2】

判定规则:如果不拒绝假设2H 则可以认为样本数据符合不变系数模型,检验结束;如果拒绝假设2H ,则检验假设1H .如不拒绝假设1H ,则认为样本数据符合变截距模型;若拒绝1H ,则认为样本数据符合变系数模型。
根据以下公式计算:【3】
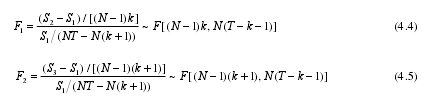
其中,1S2S3S 分别为变系数模型、变截距模型和混合模型的最小二乘残差平方和,k 表示解释变量个数,N 为观测单元个体数,既截面的个数(行业个数),T 为样本期数。
4.3.4 实证分析
在建立面板数据模型之前,我们首先进行单位根检验,来判断序列的平稳性。单位根检验结果如下:【4】

从上面的单位根检验可以发现这些变量都是一阶单整,对他们进行协整检验,结果如下:【5】

上述检验结果检验的样本区间为 2006-2011 年,从以上结果可以发现 Panelv-Statistic 的检验量的 p 值是 0.255,其他的都拒绝原假设,我们可以认为昆明市18 个重点行业的面板数据存在协整关系。
根据 2006-2011 年,昆明市 18 个行业的面板数据,使用 Eviews 6.0 计算得到1S =0.0267,2S =0.0688,3S =0.3026,T =6,k =3,N =18.由公式(4.4)和(4.5)可得检验统计量1F =1.05,2F =5.47. 利用函数得到 F 分布的临界值,其中 d 是临界点, 和 是自由度。在给定 5%的显着性水平下(d=0.95),得到相应的临界值为: (68,36) =1.67; (51,36) = 1.68.
由于 1.68,所以拒绝 ;又由于 1.67,所以不拒绝 .因此,通过计算我们发现拒绝变系数模型和不变系数模型,因此采用变截距模型。根据对个体影响的形式不同,变截距模型又分为固定影响模型变截距模型和随机影响变截距模型两种。通过 Hausman 检验可以看出,模型的 W 统计量大于临界值,这说明模型拒绝个体影响与解释变量不相关的原假设,再结合具体情况,本文选取了昆明市 18 个重点行业的截面数据,故应当将模型中的个体影响确定为固定影响模式。
使用 Eviews6.0 软件,计算结果如下:【6】

由2R 和 F 的值可知,模型拟合优度很高且总体线性关系显着。 DW 接近 2说明模型不存在自相关。JCL,CFL,SF 的系数均能通过 t 检验,这说明检查率,处罚力,税负对流失率的影响显着。
由上式可以看出,检查率,处罚率与流失率成反向关系,而税负与流失率成正向关系。而检查率对流失率的影响程度最大,税负对流失率的影响程度最小,因此,在实际操作中,可以通过提高检查力度来达到降低增值税流失率。

摘要地球是目前唯一适合人类生存的环境。上世纪60年代以来,世界范围内的环境污染状况日益突出,全球气候变暖、雾霾严重、怪病不断等污染引发的问题,引起了国际社会的广泛关注。为此,联合国多次召开了以环境为议题的会议,人们开始关注环境问题并逐渐...
第五节非居民企业股权转让避税地风险分析一、滥用国际税收协定的涉税风险(一)政策解读如果在股权转让中,转让股权的非居民企业所在国与我国签订了税收协定,那么在转让方提出适用其所在国与我国的税收协定待遇的情况下,对其股权转让所得如何征税就要...
摘要改革开放以来,我国市场经济的发展步伐不断加快,越来越多的跨国企业以设立合资企业、独资企业、分支机构或代表处等各种形式进入中国。随着国际资本的流动,我国已吸引外资共计超过万亿美元,外商投资企业接近60万家,跨国公司的大量涌入也为我国税...
3DF汽车股份有限公司税务筹划应注意的问题。企业所得税、增值税、消费税是DF汽车股份有限公司的最重要的几种税种,其税务筹划工作同时也是对政策的动态要求较强,对财务管理业务的技术水平要求很高的工作,DF汽车股份有限公司的经营活动还存在着内部环...
第一章:绪论1.1研究背景及研究意义1.1.1研究背景纳税遵从问题一直以来都受到社会的普遍关注,最近几年,相关部门在治理税收流失、提高公民纳税遵从方面做了大量工作,也取得了很大的进展。但是,我国的个人所得税纳税遵从情况还是不容乐观。我国构建社...
第2章物流业及其税收政策演变2.1物流业的概念、地位及发展模式2.1.1物流业的概念物流活动的历史可谓源远流长。在人类的历史长河中,物流活动与人类朝夕相处、息息相关。物流是社会经济的基础活动。人类对物质不断增长的需求是推动社会发展的根本动力...
第五章税负示意性测算假设:REITs投资的房地产项目的租金收入有10,000元,其他可能收入有1,000元,运营成本为500元,REITs基本管理费为400元,托管费为3元,资产净值为100,000元,在我国,转让资产增值额为10,000元,则按照现行税法情况下...
第二章房地产投资信托基金(REITs)概述第一节REITs的内涵与特征一、内涵房地产投资信托基金(Realestateinvestmenttrust简称REITs)源起美国,对其的定义是:REITs是一种筹集众多投资者的资金用于取得各种收益性房地产或向收益性房地产提供融资...
一、引言(-)研究背景和意义个人所得税作为世界性税种,自1799年在英国出现,经历长期的发展,逐渐成为各国的主体税种,甚至在许多发达国家己经成为主要的收入来源之一,其主体税种的地位得到不断巩固和加强。在我国,个人所得税起步较晚,税制的完善程度与发达国...
3.个人所得税费用扣除现状及问题3.1我国费用扣除制度现状现在个人所得税已经成为大多数国家税收体系当中重要的大税种之一,当然在中国也占有重要的一席之地。相较于其他国家,我国开征个人所得税的时间比较晚,于1980年第五届全国人大代表大会通过并实...