3 寿险公司产品结构影响公司经营绩效的实证分析。
在以上理论分析的基础上,本章进行实证分析,实证分析思路如下:分为两个部分,第一部分首先运用主成分分析法对每年每家公司经营绩效做出综合评价,得出绩效得分[38].第二部分将公司经营绩效得分作为被解释变量,将公司寿险产品结构指标作为解释变量,建立面板数据模型,进行回归分析,得出结论。
3.1 寿险公司经营绩效的评价。
3.1.1 样本与数据。
在 2004 年之前,关于寿险公司各项产品的保费收入数据没有公开,并且,2007 年开始实施新会计准则,所以为了数据的可获得性以及统计口径的一致,本文数据选择从 2007 年开始至最新公布 2011 共五年的数据。在本文中所研究的样本数据来自于 2008--2012《中国保险统计年鉴》,在 2008《中国保险统计年鉴》中共有 47 家寿险公司,再考虑到公司成立的年份及规模,本文对这 47 家公司做出删选,得到 31 家公司:中国人寿、太平人寿、民生人寿、太平洋人寿、平安人寿、新华人寿、泰康人寿、生命人寿、天安人寿、中宏人寿、建信人寿、中德安联、金盛、交银康联、中意人寿、光大永明、中荷人寿、海尔人寿、中英人寿、海康人寿、招商信诺、长生人寿、恒安标准、瑞泰、中美联泰大都会、友邦上海、友邦广东、友邦深圳、友邦北京、友邦江苏。以上所列取的保险公司的总市场份额达到了 90%,基本可以代表了整个市场的情况。
3.1.2 绩效评价指标的构建。
企业的经营绩效评价必然通过各项指标来体现,指标体系的选取会影响到绩效评价的结果[39].目前企业绩效评价文献中指标体系构建一般遵循以下原则[40]:
第一,遵循科学,科学性主要表现为:首先,选择的指标应合理、规范,概念准确,有内涵,其次,选择的指标应与国际惯例相应,最后,选择的指标应该是理论上经过学者多年的总结概括;第二,须可操作,指标的选择需要时可以衡量操作的,有数据可以体现,是具有可信度的,并且应避免过于繁琐,指标的数量应适中;第三,有可比性,绩效的评价在于与同行业的公司进行比较,因此,指标的选择上要注重不同公司之间指标的可比性,要统计口径一致,这样才具有评价意义;第四,结合绝对指标和相对指标,绝对指标能反映定量数据,相对指标能消除其他因素的影响使不同样本之间具有可比性,因此,对企业进行绩效评价应结合绝对指标和相对指标,这样才能更加合理;第五,要有发展性,对企业评价不应仅仅限于目前的数据所表现出的结果,更要结合代表企业发展成长性的指标,注重企业的成长能力的考察。于是,本文从以下四个方面来评价我国寿险公司经营绩效[41]:
盈利能力:盈利能力是指企业赚取利润的能力,是企业赖以生存的基础,故受投资者、债权人、企业管理者等的广泛关注。本文选取资产收益率和销售净利率两个指标来反映公司的盈利能力。资产收益率反映的是每 1 元的资产能够给公司带来多少的利润,是从资产角度来考虑的。销售净利率反映保险公司每 1 元的营业收入所带来的净利润有多少,是从营业收入的角度来考虑的。这两个指标基本可以反应公司的盈利状况。
营运能力:公司的营运能力决定了公司各个方面的成绩,通常,综合费用率、综合赔付率、给付率、退保率都能反映寿险公司的经营能力,本文选取寿险公司独有的退保率作为反映寿险公司经营能力的指标,其衡量的是保险公司退保情况的指标,正常范围一般应<5%,如果退保率较高,说明公司展业质量差,公司的支出增加,影响公司的获利能力。另外选择投资收益率作为衡量公司资金运作能力的指标,保险公司能够适当的运用其所拥有的资金获得使其获得最大的收益,实现保值增值的目的,对于保险公司的发展至关重要。
偿付能力:寿险公司经营的很多业务都是长期性的,因此,公司的偿付能力至关重要,好的偿付能力才能保证公司的长久良性经营。判断寿险公司偿债能力高低的指标有很多,本文选取资产负债率和流动比率两个指标来衡量公司的偿债能力,资产负债率是是从长期角度衡量公司的偿付能力,流动比率又称之为短期偿债能力比率,是衡量保险公司短期内流动性的能力,是从短期的角度来衡量公司的偿付能力。[42]自 2007 年保险会计准则变更后,会计报表不再公布合计的流动资产与流动负债数值,新会计准则中流动资产与流动负债的会计目录如下表格:
成长能力:保险公司的成长能力对其利益相关者来说非常重要。其可以通过不同时期股东权益、资产、净利润和保费收入的增长率来衡量。本文将从净利润增长率、保费收入增长率、资产增长率三个指标来度量寿险公司的成长能力。首先,资产增长率仅仅考察的是总资产的增长情况,其次,考察一个公司的成长能力仅仅考察资产增长是不够的,资产的增长必须与公司的业务增长以及利润的增长联合起来考察,因为只有这三个方面同时的增长才代表是整个公司的成长,才是有效的成长,因此,笔者将保费收入增长率,净利润增长率也考虑进来,这样三个指标才更能有效的反应公司的成长能力。
对于绝对指标与相对指标结合的原则,本文指标选取上在以上四个方面再加入总资产、总保费收入以及利润总额三个绝对指标。因此,本文的指标体系构建总体内容见下表:
3.1.3 方法介绍。
目前,随着多元统计方法的发展和应用,在评价经济综合效益方面,主成分分析方法应用普遍并且成熟,普遍认为此方法较优。主成分分析方法是通过降维的方法达到目的,是 1933 年 Hotelling 提出的,它是通过降维的思想达到综合评价的效果。主成分分析法的基本思想[43]:在评价实际经济问题时,通常会有许多的指标,而这些指标内在上或多或少都存在一定的信息重叠。主成分分析方法就是通过降维的方法,用降维后的指标代替原有指标的大部分信息。假设有 n个原始指标,通过主成分提取出新的相互无关的指标,第一个指标的方差最大,其所包含的原始指标的信息量最大,把这个方差最大的指标称为第一主成分,当第一个主成分不够时,还会提取第二个主成分,一般提取方差大于 1 的主成分,这几个主成分能代表的原始指标的大部分信息,这几个主成分之间互不相关并且方差逐渐减小。因此,通过此方法,可以通过简化原有指标,对其进行降维,经过处理后的维度可以代替原有指标的大量信息,再通过一定的方法计算,得出评价结果。
3.1.4 评价及结果。
根据上述方法,本文利用统计软件 SPSS17.0 对31家寿险公司2007年~2011年数据进行绩效评价[44].
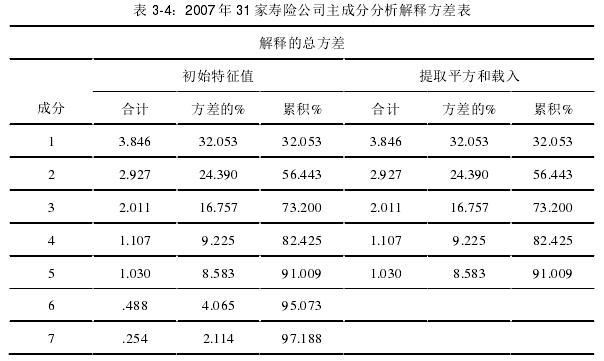
首先,通过对 2007 年 31 家寿险公司的数据做主成分分析为示范,得出其综合绩效得分,以后年份遵循同样方法步骤。第一步对指标中的逆指标如退保率以及资产负债率作正向化处理,这里采取其原始数据的负数作为新的数据,则所有指标数据上都统一为正向指标,即数值越大越好。另外,由于各个指标的意义不同,数据所代表的信息不具有可比性,因此,在进行软件分析前,须对所有的数据进行标准化处理,主要是通过一定的数学变换方法,这里可以通过软件实现的,这样性质、量纲各异的指标转化为可以进行比较的量化值,消除了量纲的影响。[45]通过软件操作得出以下结果:
由上表可知,主成分对各个变量都提取了较大的信息,最大的为保费收入信息达到了 0.992,而最小的则为流动比率 0.772,信息损失量较小,说明提取效果很好。
上表给出的是各成分的方差贡献率和累计贡献率,前 5 个特征根大于 1,因此SPSS 只提取了前 5 个主成分。第一主成分的贡献率为 32.053%,所提取的 5 个主成分的累计贡献率达到了 91.009%,几乎涵盖了原变量所有的信息,这也说明了信息损失量很小,因此选前 5 个主成分己足够描述公司绩效的水平。
通过软件运算自动得出所提取的 5 个因子得分,即 factor_1-factor_5 的结果(此处未展示出),但这不代表 5 个主成分的得分,要得出 5 个主成分得分,需通过公式计算得出,例如:主成分 1 得分=factor_1 得分?主成分 1 的方差即3.846 的算术平方根,以此类推,得出各主成分的得分(如下表 3-5 所示),然后,通过 5 个主成分得分可以计算出最终综合得分,公式为:
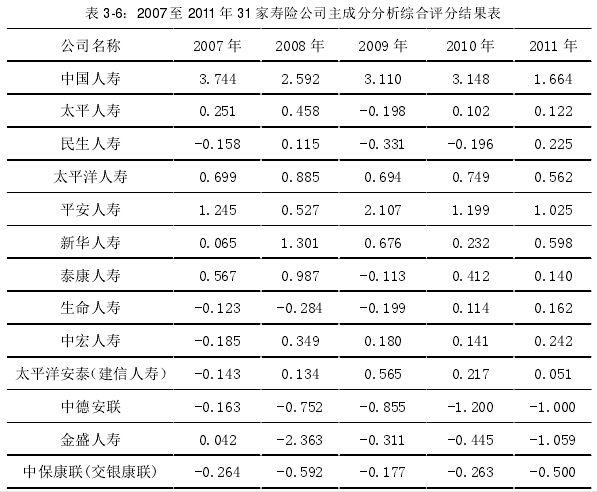
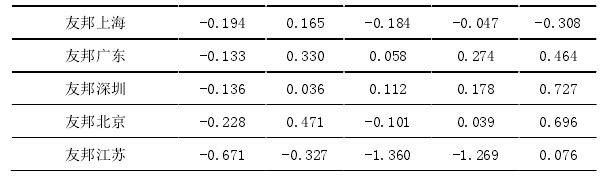
本文需要的是各样本的综合绩效得分,因此,其中涉及的运行过程不再赘述,2008 至 2011 年的综合绩效得分同样按照主成分分析法得出。经过整理得出每年各样本综合绩效得分见下表:
在这里说明,主成分的均值与综合绩效的总和得分都是 0,在进行主成分分析前,数据都已经过标准化处理。正数得分表示比平均水平高,负数得分表示比平均水平低。
3.2 公司经营绩效与产品结构指标的回归。
本节就利用上一节所得的 31 家寿险公司 2007-2011 年的绩效得分(JIXIAO)作为被解释变量,利用面板数据模型与公司产品结构指标进行回归。
3.2.1 样本与数据。
样本是与上节中绩效评价的样本选择相同,数据来源于《中国保险统计年鉴》每家公司公布的各项产品业务的保费收入情况,通过整理而得。
3.2.2 产品结构指标的构建。
寿险产品结构即是不同寿险产品的配比,依据数据可得性,本文按照《保险年鉴》中所公布的各家寿险公司业务保费收入情况来直接体现产品结构状况,《保险年鉴 2008》 公布的寿险业务数据包括普通寿险(即传统寿险)产品、分红寿险产品、其他寿险产品的保费收入情况,其他寿险产品实际上就是万能险和投连险,自《保险年鉴 2009》开始,才将万能险和投连险各自的保费收入情况分开公布。据此,本文将寿险产品结构直接体现指标分为:普通寿险产品保费收入占比(PTZB)、分红险产品保费收入占比(FHZB)、其他寿险保费收入占比(即万能险与投连险保费收入之和)(QTZB)三个指标。
3.2.3 方法介绍。
面板数据指多个样本在多个时间序列上同时观测的数据。因此,面板数据的样本更大,信息量更多,即反映了个体随着时间的变化,又反映了同一时间所有个体的比较信息,这比单独的横截面数据模型和时间序列模型效果更佳。
1、面板数据模型的基本原理如下[46]:
3.2.4 模型的建立建立最符合文章的面板数据模型大致需要经过下列三大步骤[47]:
第一步是对数据进行单位根检验和协整检验,这样可以检测出数据是否是平稳并且关系稳定的,李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的 R 平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归,因此数据平稳是模型建立的前提,这样的模型结果才是有意义的,如果单位根检验有变量是非平稳,那么,进行协整检验,如果能通过协整检验,说明这些变量的线性组合是长期均衡的,也可以避免“伪回归”的现象。
当前,检验方法主要有 LLC、Im-Pesaran-skin、Fisher-ADF 和 Fisher-PP 等检验法,协整检验是检测数据之间是否是长期稳定的均衡关系,检测方法也有很多种。
第二步是确定模型的形式,即样本适合的是上节中介绍的哪一种模型,主要是通过协方差分析检验,下面将介绍协方差分析检验的原理,该方法检验以下两个假设:
其中,F2是可以代入各参数的值计算得到的,后面服从的统计量需要通过查表得到结果,如果F2大于服从的统计量的值,那么接受原假设,则无需再进行检验,此时,样本数据符合模型一的形式,相反,如果F2小于服从的统计量的值则拒绝原假设,然后继续检验假设假设H1 ,这时,检验下面的统计量:
同样,还是通过上面的介绍算出两者的值,比较其大小,如果统计量Fl比服从的统计量的值大那么接受假设H1,这时样本数据符合模型二,相反,如果统计量Fl比服从的统计量的值小那么拒绝H1,这时候用模型三作为样本数据的模型。
其中的S1、S2、S3分别为含有个体影响的变系数模型、变截距模型和混合回归模型进行最小二乘估计后的残差平方和(Sum squared resid )。除了以上检验样本数据是符合哪种类型的面板数据模型外,还需要检测模型是固定效应还是随机效应,这时可通过Hausman检验。
第三步是对模型中的参数进行估计以及其他数据结果,通过广义最小二乘法。
下面,根据上面介绍的步骤方法利用Eviews6.0对31家公司的综合绩效得分和另外3个自变量进行面板数据回归模型的建立。建立过程如下[[48]
1、面板单位根检验。
首先,对4个变量进行单位根检验以检验数据的平稳性,防止伪回归或虚假回归。下表显示的是各变量的单位根检验结果:
由上表可见,分红占比和其他占比两个变量在 IPS 和 ADF 两种检验方法下接受原假设,其他变量在这 4 中检验方法下都拒绝原假设。因此,可以认为,FHZB和 QTZB 变量是存在单位根的,即非平稳的,不过,可以通过协整来检验这几个变量的线性组合是否是均衡关系。
2、面板协整检验。
上文所说到的协整检验各变量之间是否存在长期均衡稳定的关系。这样可以避免伪回归现象。为此,对各变量进行协整检验。进行协整检验的方法有 Pedroni检验、Kao 检验和 Johansen 检验,此处用的是 Pedroni 检验。检验结果见下图:
表中,Panel-PP、Panel-ADF、Group-rho、GrouP-PP、GrouP-ADF 统计量都显着地拒绝原假设,而 panel-v 统计量未能通过。因此,从总体上可以认为各变量之间存在显着的协整关系,即长期均衡的稳定关系,这防止了“伪回归”的现象,为模型的有效性和合理性提供了支持。
3、协方差分析检验。
根据上述的步骤所描述的方法,首先,通过软件得到 S1、S2、S3的值。方法是对样本数据分别进行变系数模型回归、变截距模型回归、无个体效应、无时点效应的回归即上述的混合模型回归得出软件结果显示的 Sum squared resid 的值即残差平方和。下表为结果:
4、进行 Hausman 检验。
在上一步的基础上,不仅要检验样本符合哪一种模型,还有判定模型是固定效应还是随机效应,Hausman 检验的原假设为模型符合随机效应,因此,下面就要检验是符合原假设还是拒绝原假设。方法是先对样本数据进行随机变截距回归,在此结果基础上进行 Hausman 检验。
其中,i = (1,2,…,31)表示的是31个寿险公司,t = (2007,2008,…,2011)表示年份,αi表示截距项,因每个个体的不同而不同,它不随时间t而变化,并且对每个个体i而言是固定的,它代表了模型中个体的差异。β1表示普通寿险产品占比对公司绩效影响的系数,同理,β2、β3为分红险占比和其他险占比对公司绩效影响的系数,这些系数不随时间变化而变化,也不随个体变化而变化。μit代表了模型中随个体又随时间变化的并且被遗漏的信息。模型的确定也表明和现实意义是相符的,各寿险公司产品结构的配置并不会因为个体的不同而对公司的影响不同,并且,模型中也并没有存在不随时间变化而变化的自变量,三个自变量在时间上都是变化的,因此,从这方面来看也正是适用于固定效应模型,Hausman 检验结果也正好符合这一点。
3.2.5 回归结果及分析。
本文用广义最小二乘法(GLS)对各模型进行参数估计,模型 1 至模型 3 设计意义在于每项指标都与综合绩效回归,模型 4 与模型 5 为渐进式,以形成对比,详细结果如下文结果分析,估计结果如下:
从上表的结果数据中可以看出,每个模型的拟合度都较好,只有模型 5 相对其他模型的拟合度有所下降,不过文章研究的是各种寿险产品的占比份额对公司经营绩效的影响的大小问题,因此不影响结果分析。从 Prob(F-statistic)数值上看,所有的模型都通过了 F 检验。总体来说,各模型回归结果较好。
模型 1 中,只有普通寿险占比指标和公司综合绩效回归,系数为 1.62038,并且在0.01水平下显着,这说明普通险种占比是有利于公司经营绩效的提高的,这与理论分析假设一一致的。
模型 2 中,只有分红寿险占比指标和公司经营绩效回归,系数为 0.27539,但是其显着性水平不是很高,只是在 0.1 水平下,这在一定的程度上是与假设二符合的。
模型 3 中,只有其他寿险占比指标和公司经营绩效回归,系数为-0.38813,并且显着性水平很高,在 0.01 水平下显着,这表明了其他寿险占比过高是不利于保险公司综合经营绩效的提高的。投资连结险和万能寿险是以投资为主的保险产品,并不适合寿险公司的发展。这结果验证了假设三中的假设。
模型 4 中,将普通寿险占比指标和分红寿险占比指标作为两个自变量与综合经营绩效一起回归。结果显示,普通寿险占比和模型 1 的结果一致,系数为正数,且非常显着。分红寿险占比指标的系数为 0.1402,不显着,这说明在保险公司同时经营传统寿险产品和分红寿险产品的情况下,普通寿险产品是有利于公司经营绩效的提高,而分红寿险产品虽然系数为正,但是却并不显着,对于是否有利于公司经营绩效的提高是不确定的。
模型 5 表明了在寿险公司综合绩效同时与三个产品结构指标回归的情况下各自的系数大小,传统寿险对公司经营绩效的结果与模型1和模型4的结果一致,并且非常显着,分红寿险产品占比与公司经营绩效的回归结果与模型 2 结果一致,不显着,其他寿险产品占比对公司经营绩效的影响与模型 3 结果一致,显着性有所降低,但在总体上看还是显着的。